Project Loom — один из проектов, спонсируемых Hotspot Group, и призванных обеспечить высокую производительность и облегченную модель параллелизма в мире JAVA. На момент написания этой статьи проект Loom все еще находился в активной разработке, и его API может измениться.
Почему ткацкий станок?
Первый вопрос, который может и должен появиться в каждом новом проекте: почему?
Почему мы должны изучать что-то новое и где это нам помогает? (если это действительно так)
Поэтому, чтобы ответить на этот вопрос специально для Loom, нам сначала нужно знать основы того, как работает существующая система потоков в JAVA.
Каждый поток, созданный в JVM, заканчивается соответствующим потоком в пространстве ядра ОС со своим стеком, регистрами, счетчиком программ и состоянием. Вероятно, самой большой частью каждого потока будет его стек, размер стека в мегабайтах и обычно составляет от 1 до 2 МБ.
Таким образом, эти типы потоков являются дорогими с точки зрения как инициации, так и времени выполнения. Невозможно создать 10 тысяч потоков в одной машине и ожидать, что это просто сработает.
Кто-то может спросить, зачем нам столько потоков? Учитывая, что процессоры просто имеют несколько гиперпотоков. Например, CPU Core Core i9 имеет в общей сложности 16 потоков.
Что ж, процессор — не единственный ресурс, который использует ваше приложение, любое программное обеспечение без ввода-вывода просто способствует глобальному потеплению!
Как только потоку требуется ввод / вывод, ОС пытается выделить ему требуемый ресурс и планирует в то же время другой поток, которому требуется процессор.
Таким образом, чем больше потоков у нас в приложении, тем больше мы можем использовать эти ресурсы параллельно.
Один очень типичный пример — веб-сервер. каждый сервер может обрабатывать тысячи открытых соединений в любой момент времени, но для обработки такого количества соединений одновременно требуются тысячи потоков или асинхронный неблокирующий код ( в ближайшие недели я, возможно, напишу еще один пост, чтобы объяснить больше о асинхронный код ) и, как упоминалось ранее, тысячи потоков ОС — это не то, что ни вам, ни ОС не понравится!
Как ткацкий станок помогает?
В рамках Project Loom представлен новый тип нити, называемый Fiber . Волокно также называется Виртуальный поток , Зеленый поток или Пользовательский поток, поскольку эти имена подразумевают, что он полностью обрабатывается виртуальной машиной, и ОС даже не знает, что такие потоки существуют. Это означает, что не каждый поток ВМ должен иметь соответствующий поток на уровне ОС! Виртуальные потоки могут быть заблокированы вводом-выводом или ждать получения сигнала от другого потока, однако, тем временем базовые потоки могут использоваться другими виртуальными потоками!
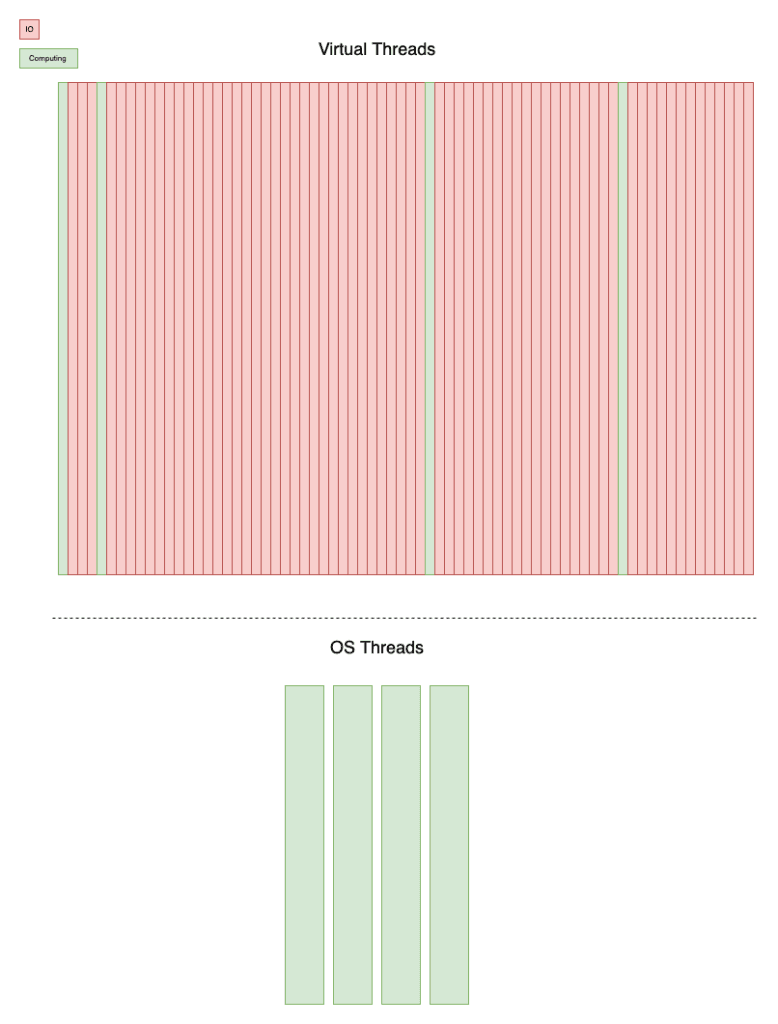
Изображение выше иллюстрирует взаимосвязь между виртуальными потоками и потоками ОС. Виртуальные потоки могут быть просто заблокированы вводом-выводом, и в таких случаях базовый поток будет использоваться другим виртуальным потоком.
Объем памяти этих виртуальных потоков будет измеряться в килобайтах, а не в мегабайтах. Их стек потенциально может быть расширен после порождения, если это необходимо, так что JVM не нужно выделять им значительную память.
Итак, теперь, когда у нас есть очень легкий способ реализации параллелизма, мы можем переосмыслить лучшие практики, существующие и в классических потоках в Java.
В настоящее время наиболее используемая конструкция для реализации параллелизма в Java — это разные реализации ExecutorService . Они имеют довольно удобные API и относительно просты в использовании. Службы Executor имеют внутренний пул потоков для управления количеством потоков, которые могут быть созданы на основе характеристик, определенных разработчиком. Этот пул потоков в основном используется для ограничения количества потоков ОС, создаваемых приложением, поскольку, как мы упоминали выше, они являются дорогостоящими ресурсами, и мы должны использовать их как можно больше. Но теперь, когда есть возможность создавать легкие виртуальные потоки, мы можем переосмыслить то, как мы используем ExecutorServices .
Структурированный параллелизм
Структурированный параллелизм — это парадигма программирования, структурированный подход к написанию параллельных программ, которые легко читать и поддерживать. Основная идея очень похожа на структурированное программирование, если в коде есть четкие точки входа и выхода для параллельных задач, рассуждение о коде будет намного проще по сравнению с запуском параллельных задач, которые могут длиться дольше, чем текущая область!
Чтобы понять, как может выглядеть структурированный параллельный код, рассмотрим следующий псевдокод:
|
1
2
3
4
5
6
7
|
void notifyUser(User user) { try(var scope = new ConcurrencyScope()) { scope.submit( () -> notifyByEmail(user)); scope.submit( () -> notifyBySMS(user)); } LOGGER.info("User has been notified successfully");} |
Предполагается, что метод notifyUser уведомляет пользователя по электронной почте и SMS, и как только оба будут выполнены успешно, этот метод будет регистрировать сообщение. При структурированном параллелизме можно гарантировать, что журнал будет записан сразу после выполнения обоих методов уведомления. Другими словами, область действия try будет выполнена, если все запущенные параллельные задания внутри нее завершатся!
Примечание. Для простоты примера мы предполагаем notifyByEmail и notifyBySMS. В приведенном выше примере выполняем все возможные угловые случаи внутренне и всегда выполняем их.
Структурированный параллелизм с JAVA
В этом разделе я покажу, как можно писать структурированные параллельные приложения в JAVA и как Fibers поможет масштабировать приложение на очень простом примере.
Что мы собираемся решить
Представьте, что у нас есть 10 тысяч задач, связанных с вводом-выводом, и каждая задача занимает ровно 100 мс. Нас просят написать эффективный код для выполнения этих задач.
Мы используем класс Job, определенный ниже, чтобы имитировать нашу работу.
|
1
2
3
4
5
6
7
8
9
|
public class Job { public void doIt() { try { Thread.sleep(100l); } catch (InterruptedException e) { e.printStackTrace(); } }} |
Первая попытка
В первой попытке напишем его с помощью пула кэшированных потоков и потоков ОС.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public class ThreadBasedJobRunner implements JobRunner { @Override public long run(List<Job> jobs) { var start = System.nanoTime(); var executor = Executors.newCachedThreadPool(); for (Job job : jobs) { executor.submit(job::doIt); } executor.shutdown(); try { executor.awaitTermination(1, TimeUnit.DAYS); } catch (InterruptedException e) { e.printStackTrace(); Thread.currentThread().interrupt(); } var end = System.nanoTime(); long timeSpentInMS = Util.nanoToMS(end - start); return timeSpentInMS; }} |
В этой попытке мы не применили ничего из проекта Loom. Просто кешированный пул потоков, чтобы обеспечить использование свободных потоков вместо создания нового потока.
Давайте посмотрим, сколько времени потребуется для выполнения 10000 заданий с этой реализацией. Я использовал приведенный ниже код, чтобы найти 10 самых быстрых прогонов кода. Для простоты не использовался инструмент для микро-бенчмаркинга.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
public class ThreadSleep { public static void main(String[] args) throws InterruptedException { List<Long> timeSpents = new ArrayList<>(100); var jobs = IntStream.range(0, 10000).mapToObj(n -> new Job()).collect(toList()); for (int c = 0; c <= 100; c++) { var jobRunner = new ThreadBasedJobRunner(); var timeSpent = jobRunner.run(jobs); timeSpents.add(timeSpent); } Collections.sort(timeSpents); System.out.println("Top 10 executions took:"); timeSpents.stream().limit(10) .forEach(timeSpent -> System.out.println("%s ms".formatted(timeSpent)) ); }} |
Результат на моей машине:
Топ 10 казней заняли:
694 мс
695 мс
696 мс
696 мс
696 мс
697 мс
699 мс
700 мс
700 мс
700 мс
Пока у нас есть код, который в лучшем случае занимает около 700 мсек, чтобы выполнить 10000 заданий на моей машине. Давайте реализуем JobRunner на этот раз, используя функции Loom.
Вторая попытка (с волокнами)
В реализации с Fibers или виртуальными потоками я также собираюсь структурировать параллелизм.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
public class FiberBasedJobRunner implements JobRunner { @Override public long run(List<Job> jobs) { var start = System.nanoTime(); var factory = Thread.builder().virtual().factory(); try (var executor = Executors.newUnboundedExecutor(factory)) { for (Job job : jobs) { executor.submit(job::doIt); } } var end = System.nanoTime(); long timeSpentInMS = Util.nanoToMS(end - start); return timeSpentInMS; }} |
Возможно, первой примечательной особенностью этой реализации является ее краткость, если вы сравните ее с ThreadBasedJobRunner, вы заметите, что в этом коде меньше строк! Основная причина — новое изменение в интерфейсе ExecutorService, которое теперь расширяет Autocloseable, и в результате мы можем использовать его в области проб с ресурсами. Коды после блока try будут выполнены после выполнения всех отправленных заданий.
Это как раз основная конструкция, которую мы используем для написания структурированных параллельных кодов в JAVA.
Другая новая вещь в приведенном выше коде — это новый способ создания фабрик потоков. Класс Thread имеет новый статический метод с именем builder, который можно использовать для создания Thread или ThreadFactory .
Эта строка кода создает фабрику потоков, которая создает виртуальные потоки.
|
1
|
var factory = Thread.builder().virtual().factory(); |
Теперь давайте посмотрим, сколько времени потребуется для выполнения 10000 заданий с помощью этой реализации.
Топ 10 казней заняли:
121 мс
122 мс
122 мс
123 мс
124 мс
124 мс
124 мс
125 мс
125 мс
125 мс
Учитывая, что Project Loom все еще находится в активной разработке, и есть еще возможности для повышения скорости, но результат действительно отличный.
Многие приложения, будь то полностью или частично, могут извлечь пользу из волокон с минимальными усилиями! Единственное, что нужно изменить — это фабрика потоков из пулов потоков, и все!
В частности, в этом примере скорость выполнения приложения улучшилась в ~ 6 раз, однако скорость — это не единственное, чего мы добились здесь!
Хотя я не хочу писать об объеме памяти приложения, которое резко сократилось при использовании Fibers, но я настоятельно рекомендую вам поиграть с кодами этого поста, доступными здесь, и сравнить объем используемой памяти вместе с количество потоков ОС каждая реализация занимает! Вы можете скачать официальную сборку раннего доступа Loom здесь .
В следующих статьях я напишу больше о других API-проектах, которые представляет Loom, и о том, как мы можем применять их в реальных случаях использования.
Пожалуйста, не стесняйтесь поделиться своими отзывами через комментарии со мной
|
Смотрите оригинальную статью здесь: OpenJDK Loom и структурированный параллелизм Мнения, высказанные участниками Java Code Geeks, являются их собственными. |