 В одной из моих предыдущих публикаций я уже обсуждал, как обрабатывать образец канала Twitter с помощью Apache Storm , и теперь мы собираемся пройти через шаги по созданию примера приложения Spring Boot, которое читает сообщения из примера канала Twitter с помощью Spring Social Twitter. рамки и записывает данные в Neo4J с помощью Spring Data Neo4J .
В одной из моих предыдущих публикаций я уже обсуждал, как обрабатывать образец канала Twitter с помощью Apache Storm , и теперь мы собираемся пройти через шаги по созданию примера приложения Spring Boot, которое читает сообщения из примера канала Twitter с помощью Spring Social Twitter. рамки и записывает данные в Neo4J с помощью Spring Data Neo4J .
Весь проект доступен на Github по адресу https://github.com/davidkiss/twitter-keyword-graph , но мы будем обсуждать здесь каждый шаг один за другим.
Что такое Spring Boot?
Если вам интересно, каким может быть Spring Boot, это одно из последних дополнений к стеку Spring, построенное поверх Spring Framework. Spring Boot выводит продуктивность разработки программного обеспечения на новый уровень, а также предлагает готовые к работе инструменты из коробки (метрики, проверки работоспособности, внешняя конфигурация и интеграция с liquibase , инструментом рефакторинга БД).
Настройка приложения
Все связанные с приложением конфигурации хранятся в файле src / main / resources / application.properties, который необходимо создать из файла шаблона application-template.properties в той же папке. Обязательно обновите файл свойств, указав свои собственные значения конфигурации для подключения к Twitter Api ( https://twittercommunity.com/t/how-to-get-my-api-key/7033 ).
Свойство neo4j.uri используется для установки сведений о соединении с нашим сервером Neo4J.
Если для свойства twitterProcessing.enabled установлено значение false, обработка твиттера отключится, а мы все еще можем запросить API REST приложения для уже обработанных данных.
Свойства taskExecutor.xyz используются для TaskExecutorPool, где мы настраиваем пул рабочих, которые будут обрабатывать твиты параллельно из ленты Twitter.
Spring Boot может творить чудеса, используя свои аннотации, и это помогло настроить и запустить веб-приложение в несколько строк кода. См. Классы Application , Neo4JConfig , TwitterConfig и TaskExcutorConfig о том, как клиенты Neo4J и Twitter соединяются вместе с помощью файла конфигурации application.properties .
Чтение сообщений из твиттера
В классе обслуживания TwitterStreamIngester настроен прослушиватель для примера канала Twitter с использованием Spring Social Twitter. В зависимости от количества рабочих, настроенных для TaskExecutor , приложение создает несколько экземпляров класса TweetProcessor, которые будут обрабатывать твиты асинхронно и параллельно (если обработка включена).
Асинхронная обработка выполняется с использованием BlockingQueue и компонента ThreadPoolTaskExecutor, внедренного Spring. Если обработка твитов происходит медленнее, чем скорость входящих твитов, приложение будет отбрасывать новые твиты (см. Метод BlockingQueue # offer () ) до тех пор, пока оно не догонит их.
Вот код, который читает сообщения из ленты и помещает их в очередь в TwitterStreamIngester :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
public void run() { List<StreamListener> listeners = new ArrayList<>(); listeners.add(this); twitter.streamingOperations().sample(listeners); } @PostConstruct public void afterPropertiesSet() throws Exception { if (processingEnabled) { for (int i = 0; i < taskExecutor.getMaxPoolSize(); i++) { taskExecutor.execute(new TweetProcessor(graphService, queue)); } run(); } } @Override public void onTweet(Tweet tweet) { queue.offer(tweet); } |
А вот код в классе TweetProcessor, который обрабатывает сообщения из очереди:
|
01
02
03
04
05
06
07
08
09
10
11
|
@Override public void run() { while (true) { try { Tweet tweet = queue.take(); processTweet(tweet); } catch (InterruptedException e) { e.printStackTrace(); } } } |
Разговор с базой данных Neo4J
Для работы приложения требуется автономный сервер Neo4j. Вы можете скачать последнюю версию Neo4J Community Edition с http://neo4j.com/download/ и запустить ее, запустив bin / neo4j-community .
В небольшом диалоговом окне нажмите кнопку «Пуск» в правом нижнем углу, и через несколько секунд база данных должна быть запущена по адресу http: // localhost: 7474 / .
Возвращаясь к коду, класс KeywordRepository расширяет интерфейсы репозитория Spring Data Neo4J, позволяя нам создавать запросы Cypher для извлечения данных из Neo4j без какого-либо стандартного кода. Используя аннотацию @RepositoryRestResource, она также создает конечные точки REST для доступа к данным ключевых слов в твиттере:
|
01
02
03
04
05
06
07
08
09
10
11
|
@RepositoryRestResource(collectionResourceRel = "keywords", path = "keywords")public interface KeywordRepository extends GraphRepository<Keyword>, RelationshipOperationsRepository<Keyword> { // Spring figures out Neo4j query based on method name: Keyword findByWord(String word); // Spring implements method using query defined in annotation: @Query("START n = node(*) MATCH n-[t:Tag]->c RETURN c.word as tag, count(t) AS tagCount ORDER BY tagCount DESC limit 10") List<Map> findTopKeywords(); @Query("start n=node({0}) MATCH n-[*4]-(m:Keyword) WHERE n <> m RETURN DISTINCT m LIMIT 10") List<Keyword> findRelevantKeywords(long keywordId);} |
Обратите внимание, что класс Application должен быть настроен для поиска аннотации @RepositoryRestResource:
|
1
2
3
4
|
...@Import(RepositoryRestMvcConfiguration.class)public class Application extends Neo4jConfiguration {... |
Класс GraphService инкапсулирует все связанные с Neo4j операции — создавая узлы и связи в базе данных и запрашивая существующие записи. Вот выдержка из класса:
|
01
02
03
04
05
06
07
08
09
10
11
|
public Tag connectTweetWithTag(Tweet tweet, String word) { Keyword keyword = new Keyword(word); keyword = keywordRepository.save(keyword); Tag tag = tweetRepository.createRelationshipBetween(tweet, keyword, Tag.class, "Tag"); return tag; }// ... public List<Map> findTopKeywords() { return keywordRepository.findTopKeywords(); } |
Rest API для запроса Neo4j
Помимо конечных точек REST, автоматически предоставляемых Spring Data (например, http: // localhost: 8080 / Keywords / ), класс TwitterController настроен для обработки пользовательских запросов REST с использованием аннотаций Spring MVC:
|
1
2
3
4
5
|
@RequestMapping("/keywords/relevants/{word}") @ResponseBody public Iterable<Keyword> findRelevantKeywords(@PathVariable("word") String word) { return graphService.findRelevantKeywords(word); } |
Вы можете проверить эту конечную точку, как только приложение будет запущено по адресу http: // localhost: 8080 / Keywords / релевантное / <ваше ключевое слово> .
Сборка приложения
В этом примере приложения используется Maven v3 +, и, если у вас его нет, вот ссылка для его загрузки: http://maven.apache.org/download.cgi .
Pom.xml очень прост, он содержит список всех зависимостей пружин. Обратите внимание на конфигурацию подключаемого модуля spring-boot-maven- в файле и свойство start-class, которое определяет основной класс, который подключаемый модуль весеннего запуска maven может запускать из командной строки (Spring Boot использует встроенный сервер Tomcat для обслуживания HTTP-запросов. ).
|
1
2
3
4
5
6
|
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <java.version>1.7</java.version> <start-class>com.kaviddiss.keywords.Application</start-class> <spring-data-neo4j.version>3.2.0.RELEASE</spring-data-neo4j.version></properties> |
|
1
2
3
4
5
6
7
8
|
<build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins></build> |
Запуск приложения
Для запуска приложения выполните следующую команду:
|
1
|
mvn spring-boot:run |
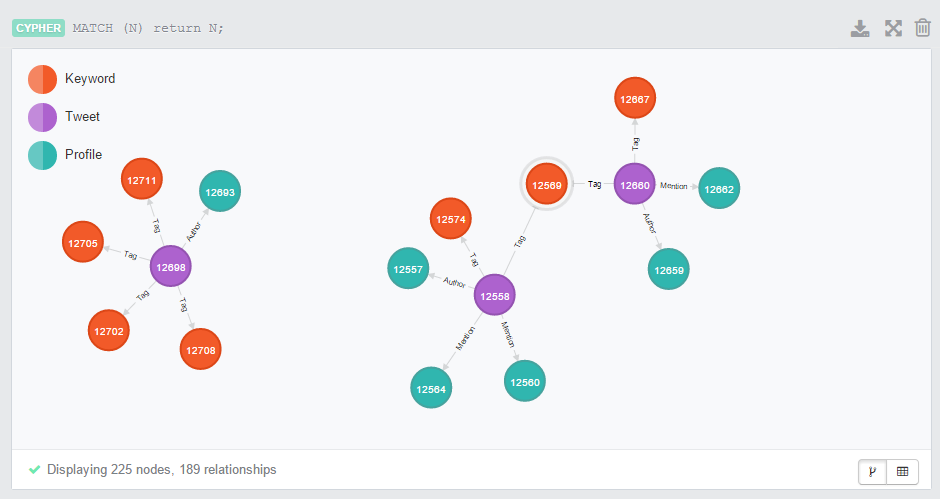
Чтобы увидеть существующие данные, заполненные в Neo4j, перейдите по адресу http: // localhost: 7474 / browser / и выполните этот запрос:
|
1
|
MATCH (N) return N; |
Результатом будет что-то похожее на скриншот ниже.
Резюме
Этот пост дает представление об использовании некоторых из самых интересных технологий Spring (Spring Boot и Spring Data) и Neo4j DB. Надеюсь, вам понравилось, и вы получили достаточно информации, чтобы начать свой собственный проект.
Вы использовали Spring Boot раньше? Какой у вас опыт работы с Spring Boot или другими упомянутыми здесь технологиями? Оставьте свои комментарии ниже.
Если вам нужна помощь в создании эффективных и масштабируемых веб-приложений на основе Java, сообщите мне об этом .
| Ссылка: | Обработка ленты Twitter с использованием Spring Boot от нашего партнера по JCG Дэвида Кисса из блога Building масштабируемых корпоративных приложений . |