Вступление
В моих предыдущих публикациях здесь и здесь я показал вам, как индексировать данные в Elasticsearch из базы данных SQL с помощью библиотеки импорта JDBC JDBC и Elasticsearch. В первой статье здесь я упомянул некоторые недостатки использования библиотеки импортера, которые я скопировал здесь:
- Нет поддержки ES версии 5 и выше
- Существует возможность дублирования объектов в массиве вложенных объектов. Но дедупликация может быть обработана на прикладном уровне.
- Возможна задержка поддержки последних версий ES.
Все вышеперечисленные недостатки можно преодолеть с помощью Logstash и его следующих плагинов:
- Плагин JDBC Input — для чтения данных из базы данных SQL с использованием JDBC
- Плагин Aggregate Filter — для объединения строк из базы данных SQL во вложенные объекты.
Создание индекса Elasticsearch
Я буду использовать последнюю версию ES, то есть 5.63, которую можно скачать с сайта Elasticsearch здесь . Мы создадим индекс world_v2, используя доступное здесь отображение.
|
1
2
|
$ curl -XPUT --header "Content-Type: application/json" http://localhost:9200/world_v2 -d @world-index.json |
или используя REST-клиент Postman, как показано ниже:
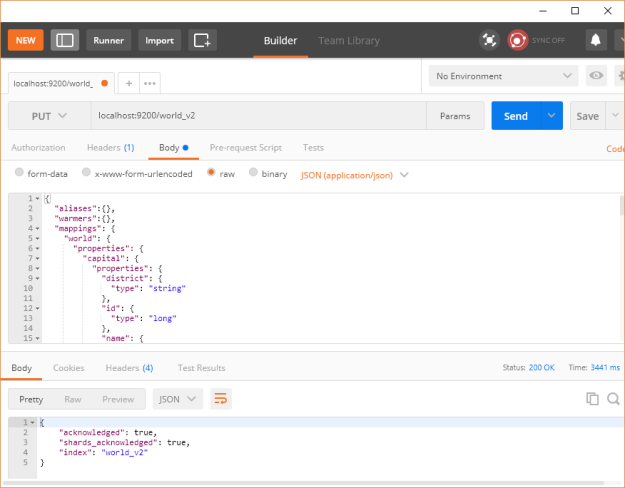
Чтобы подтвердить, что индекс был успешно создан, откройте этот URL-адрес http: // localhost: 9200 / world_v2 в браузере, чтобы получить что-то похожее, как показано ниже:

Создание файла конфигурации Logstash
Мы должны выбрать эквивалентную версию logstash, которая будет 5.6.3, и ее можно скачать отсюда . Затем нам нужно установить плагин ввода JDBC, плагин Aggregate filter и плагин Elasticsearch output, используя следующие команды:
|
1
2
3
|
bin/logstash-plugin install logstash-input-jdbcbin/logstash-plugin install logstash-filter-aggregatebin/logstash-plugin install logstash-output-elasticsearch |
Нам нужно скопировать следующее в каталог bin, чтобы иметь возможность запустить нашу конфигурацию, которую мы определим следующим:
- Загрузите банку MySQL JDBC отсюда .
- Загрузите файл, содержащий запрос SQL для получения данных, отсюда .
Мы скопируем вышеупомянутое в каталог bin Logstash или любой каталог, где у вас будет файл конфигурации logstash, потому что мы ссылаемся на эти два файла в конфигурации, используя их относительные пути. Ниже приведен файл конфигурации Logstash:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
|
input { jdbc { jdbc_connection_string => "jdbc:mysql://localhost:3306/world" jdbc_user => "root" jdbc_password => "mohamed" # The path to downloaded jdbc driver jdbc_driver_library => "mysql-connector-java-5.1.6.jar" jdbc_driver_class => "Java::com.mysql.jdbc.Driver" # The path to the file containing the query statement_filepath => "world-logstash.sql" }}filter { aggregate { task_id => "%{code}" code => " map['code'] = event.get('code') map['name'] = event.get('name') map['continent'] = event.get('continent') map['region'] = event.get('region') map['surface_area'] = event.get('surface_area') map['year_of_independence'] = event.get('year_of_independence') map['population'] = event.get('population') map['life_expectancy'] = event.get('life_expectancy') map['government_form'] = event.get('government_form') map['iso_code'] = event.get('iso_code') map['capital'] = { 'id' => event.get('capital_id'), 'name' => event.get('capital_name'), 'district' => event.get('capital_district'), 'population' => event.get('capital_population') } map['cities_list'] ||= [] map['cities'] ||= [] if (event.get('cities_id') != nil) if !( map['cities_list'].include? event.get('cities_id') ) map['cities_list'] << event.get('cities_id') map['cities'] << { 'id' => event.get('cities_id'), 'name' => event.get('cities_name'), 'district' => event.get('cities_district'), 'population' => event.get('cities_population') } end end map['languages_list'] ||= [] map['languages'] ||= [] if (event.get('languages_language') != nil) if !( map['languages_list'].include? event.get('languages_language') ) map['languages_list'] << event.get('languages_language') map['languages'] << { 'language' => event.get('languages_language'), 'official' => event.get('languages_official'), 'percentage' => event.get('languages_percentage') } end end event.cancel() " push_previous_map_as_event => true timeout => 5 } mutate { remove_field => ["cities_list", "languages_list"] }}output { elasticsearch { document_id => "%{code}" document_type => "world" index => "world_v2" codec => "json" hosts => ["127.0.0.1:9200"] }} |
Мы помещаем файл конфигурации в каталог bin logstash. Мы запускаем конвейер logstash, используя следующую команду:
|
1
|
$ logstash -w 1 -f world-logstash.conf |
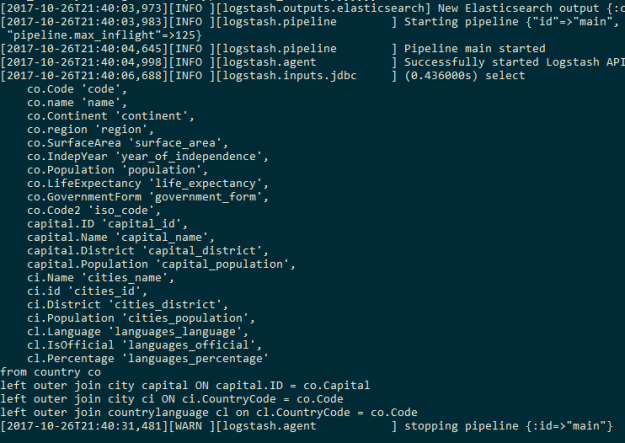
Мы используем 1 работника, потому что несколько работников могут разбить агрегацию, поскольку агрегация происходит на основе последовательности событий, имеющих общий код страны. Мы увидим следующий вывод об успешном завершении конвейера logstash:
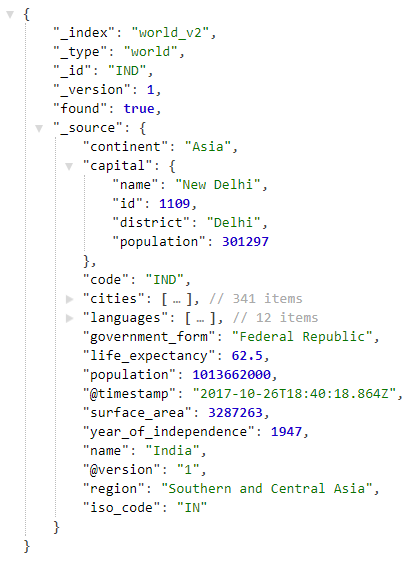
Откройте следующий URL-адрес http: // localhost: 9200 / world_v2 / world / IND в браузере, чтобы просмотреть информацию об Индии, проиндексированную в Elasticsearch, как показано ниже:
| Опубликовано на Java Code Geeks с разрешения Мохамеда Санауллы, партнера нашей программы JCG . См. Оригинальную статью здесь: агрегирование и индексирование данных в Elasticsearch с использованием Logstash, JDBC
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |