Я отличный многозадачник. Даже когда я пишу этот пост, я все еще могу чувствовать себя неловко из-за замечания, которое я сделал вчера на вечеринке, на которую все смотрели на меня странно. Что ж, хорошая новость в том, что я не одинок — Java 8 также неплохо справляется с многозадачностью. Посмотрим как.
Одной из ключевых новых функций, представленных в Java 8, являются операции с параллельными массивами. Это включает в себя такие вещи, как возможность сортировать, фильтровать и группировать элементы, используя лямбда-выражения, которые автоматически используют многоядерные архитектуры. Обещанием здесь является немедленное повышение производительности с минимальными усилиями со стороны наших разработчиков Java. Довольно круто.
Таким образом, возникает вопрос — как быстро эта вещь и когда я должен ее использовать? Ну, быстрый ответ, к сожалению, зависит . Хотите знать, на что? читать дальше.
Новые API
Новые API параллельной работы Java 8 довольно удобны. Давайте посмотрим на некоторые из них, которые мы будем тестировать.
- Чтобы отсортировать массив, используя несколько ядер, все что вам нужно сделать, это —
1
Arrays.parallelSort(numbers); - Чтобы сгруппировать коллекцию в различные группы на основе определенных критериев (например, простые и не простые числа) —
12
Map<Boolean, List<Integer>> groupByPrimary = numbers.parallelStream().collect(Collectors.groupingBy(s -> Utility.isPrime(s))); - Чтобы отфильтровать значения, все что вам нужно сделать, это —
12
Integer[] prims = numbers.parallelStream().filter(s -> Utility.isPrime(s)).toArray();
Сравните это с написанием многопоточных реализаций самостоятельно. Совсем повышение производительности! Что мне лично понравилось в этой новой архитектуре, так это новая концепция Spliterators, используемая для разбиения целевой коллекции на куски, которые затем могли обрабатываться параллельно и сшиваться обратно. Как и их итераторы старших братьев, которые используются для просмотра коллекций элементов, это гибкая архитектура, которая позволяет писать пользовательское поведение для просмотра и разделения коллекций, к которым вы можете подключиться напрямую.
Так как это работает?
Чтобы проверить это, я проверил, как параллельные операции работают в двух сценариях — низкий и высокий уровень конкуренции . Причина в том, что запуск многоядерного алгоритма сам по себе обычно дает довольно хорошие результаты. Кикер приходит, когда он начинает работать в реальной серверной среде. Именно здесь большое количество объединенных потоков постоянно борется за драгоценные циклы ЦП для обработки сообщений или пользовательских запросов. И вот тут все начинает замедляться. Для этого я настроил следующий тест . Я рандомизировал массивы целых 100K с диапазоном значений от нуля до миллиона. Затем я запустил на них операции сортировки, группировки и фильтрации, используя как традиционный последовательный подход, так и новые API-интерфейсы параллелизма Java 8. Результаты не были удивительными.
- Быстрая сортировка теперь в 4,7 раза быстрее.
- Группировка теперь в 5 раз быстрее.
- Фильтрация теперь в 5,5 раз быстрее.
Счастливый конец? К сожалению нет .
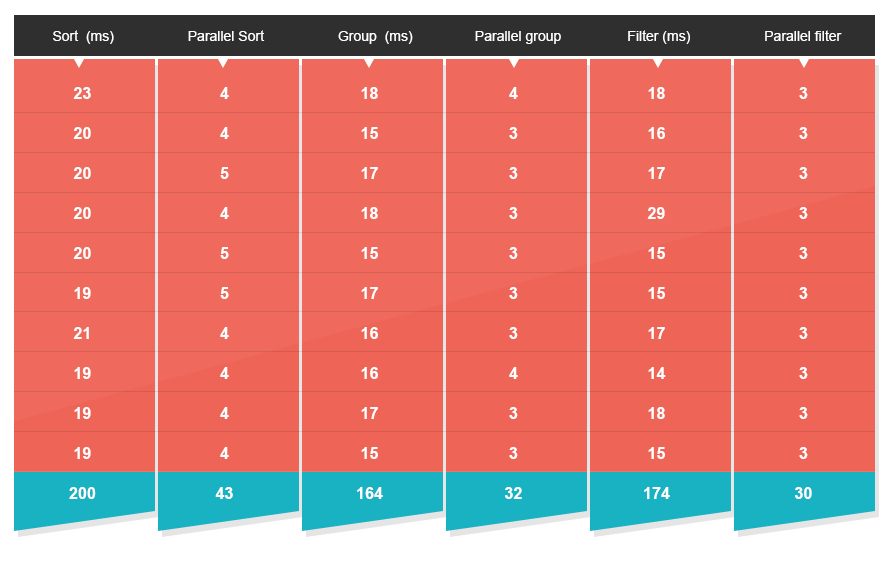
* Результаты соответствуют дополнительному тесту, который проводился 100 раз * Тестовый компьютер представлял собой MBP i7 Quad Core.
Так что же происходит под нагрузкой?
До сих пор все было довольно привлекательно, причина в том, что между циклами ЦП мало конфликтов. Это идеальная ситуация, но, к сожалению, в реальной жизни такого не бывает много. Чтобы смоделировать сценарий, который больше соответствует тому, что вы обычно видите в реальной среде, я создал второй тест. Этот тест запускает тот же набор алгоритмов, но на этот раз выполняет их в десяти параллельных потоках, чтобы имитировать обработку десяти одновременных запросов, выполняемых сервером, когда он находится под давлением ( спойте это, Кермит! ). Каждый из этих запросов будет затем обрабатываться либо последовательно с использованием традиционного подхода, либо с помощью новых API-интерфейсов Java 8.
Результаты
- Сортировка теперь только на 20% быстрее — снижение в 23 раза .
- Фильтрация теперь только на 20% быстрее — снижение в 25 раз .
- Группировка теперь на 15% медленнее .
Более высокие уровни масштаба и конкуренции, скорее всего, приведут эти цифры еще ниже. Причина в том, что добавление потоков в многопоточную среду вам не поможет. У нас столько же, сколько у нас процессоров, а не потоков. 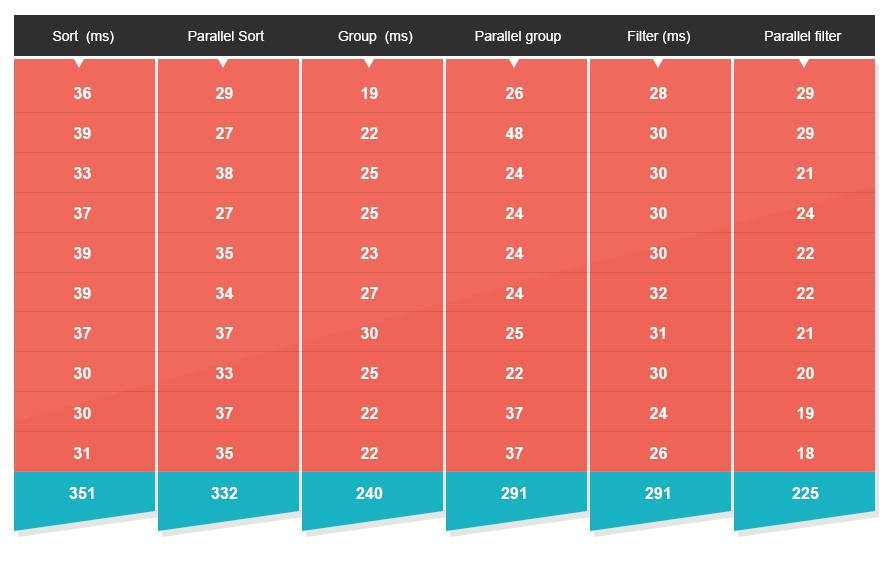
Выводы
Хотя это очень сильные и простые в использовании API-интерфейсы, они не являются «серебряной пулей». Нам все еще нужно принять решение относительно того, когда их использовать. Если вы заранее знаете, что будете выполнять несколько операций обработки параллельно, было бы неплохо подумать об использовании архитектуры очередей для сопоставления числа одновременных операций с фактическим числом доступных вам процессоров. Сложность в том, что производительность во время выполнения будет зависеть от фактической аппаратной архитектуры и уровней нагрузки. Ваш код, скорее всего, будет видеть только те, которые находятся во время нагрузочного тестирования или в производстве, что делает его классическим случаем «легко программировать, трудно отлаживать».
| Ссылка: | Новые API параллелизма в Java 8: Позади блеска и гламура от нашего партнера по JCG Тала Вайса из блога Takipi . |