Для большинства типичных корпоративных приложений Spring / Hibernate производительность приложений практически полностью зависит от производительности его уровня сохраняемости.
В этом посте будет рассказано, как подтвердить, что мы находимся в приложении с привязкой к базе данных, а затем пройдем 7 часто используемых советов по быстрому выигрышу, которые могут помочь повысить производительность приложения.
Как подтвердить, что приложение привязано к базе данных
Чтобы подтвердить, что приложение «привязано к базе данных», начните с типичного запуска в некоторой среде разработки с использованием VisualVM для мониторинга. VisualVM — это профилировщик Java, поставляемый с JDK и запускаемый из командной строки путем вызова jvisualvm .
После запуска Visual VM попробуйте следующие шаги:
- дважды щелкните по запущенному приложению
- Выбрать сэмплер
- нажмите на флажок
Settings - Выберите «
Profile only packagesи введите следующие пакеты:-
your.application.packages.* -
org.hibernate.* -
org.springframework.* -
your.database.driver.package, напримерoracle.* - Нажмите
Sample CPU
-
Профилирование процессора типичного приложения с привязкой к базе данных должно выглядеть примерно так:
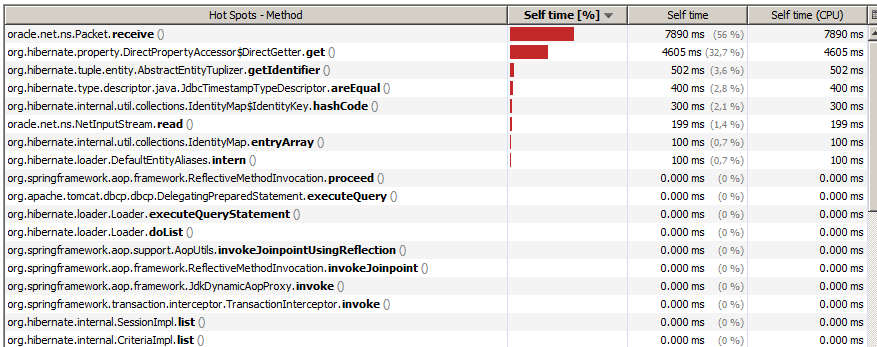
Мы видим, что клиентский Java-процесс тратит 56% своего времени на ожидание, пока база данных вернет результаты по сети.
Это хороший признак того, что запросы к базе данных — это то, что замедляет работу приложения. 32.7% вызовов Hibernate в отражении — это нормально, и с этим ничего не поделаешь.
Первый шаг для тюнинга — получение базового прогона
Первым шагом настройки является определение базового прогона для программы. Нам нужно идентифицировать набор функционально допустимых входных данных, которые заставляют программу проходить типичное выполнение, аналогичное производственному циклу.
Основное отличие состоит в том, что базовый прогон должен выполняться в гораздо более короткий промежуток времени, так как рекомендуемое время выполнения, составляющее от 5 до 10 минут, является хорошей целью.
Что делает хорошую базовую линию?
Хорошая базовая линия должна иметь следующие характеристики:
- это функционально правильно
- входные данные похожи на производство в своем разнообразии
- это завершается в короткие сроки
- оптимизации в базовом прогоне могут быть экстраполированы на полный прогон
Получение хорошего базового уровня решает половину проблемы.
Что делает плохую базовую линию?
Например, в пакетном прогоне для обработки записей данных о вызовах в телекоммуникационной системе взятие первых 10 000 записей может быть неправильным подходом.
Причина в том, что первые 10 000 могут быть в основном голосовыми вызовами, но неизвестная проблема с производительностью заключается в обработке SMS-трафика. Взятие первых записей большого пробега приведет нас к плохому исходному уровню, из которого будут сделаны неправильные выводы.
Сбор журналов SQL и времени запросов
Запросы SQL, выполненные с их временем выполнения, могут быть собраны, например, с помощью log4jdbc . См. Этот пост в блоге о том, как собирать SQL-запросы с использованием log4jdbc — Spring / Hibernate улучшил ведение журнала SQL с помощью log4jdbc .
Время выполнения запроса измеряется со стороны клиента Java и включает в себя обратную связь по сети с базой данных. Журналы SQL-запросов выглядят так:
|
1
|
16 avr. 2014 11:13:48 | SQL_QUERY /* insert your.package.YourEntity */ insert into YOUR_TABLE (...) values (...) {executed in 13 msec} |
Сами подготовленные операторы также являются хорошим источником информации — они позволяют легко идентифицировать частые типы запросов. Записаться в них можно, следуя этому сообщению в блоге. Почему и где Hibernate выполняет этот SQL-запрос?
Какие показатели можно извлечь из журналов SQL
Журналы SQL могут дать ответ на эти вопросы:
- Какие самые медленные запросы выполняются?
- Каковы наиболее частые запросы?
- Сколько времени потрачено на генерацию первичных ключей?
- Есть ли какие-то данные, которые могли бы выиграть от кэширования?
Как разобрать логи SQL
Вероятно, единственная жизнеспособная опция для больших томов журнала — это использование инструментов командной строки. Этот подход имеет то преимущество, что он очень гибкий.
За счет написания небольшого скрипта или команды мы можем извлечь практически любую необходимую метрику. Любой инструмент командной строки будет работать так долго, как вам удобно.
Если вы привыкли к командной строке Unix, bash может быть хорошим вариантом. Bash может также использоваться на рабочих станциях Windows, например, с помощью Cygwin или Git, который включает командную строку bash.
Часто используемые Quick-Wins
Ниже приводятся краткие справки по выявлению общих проблем с производительностью в приложениях Spring / Hibernate и соответствующих решений.
Быстрый выигрыш Совет 1 — Сокращение накладных расходов на генерацию первичного ключа
В процессах, требующих «вставки», выбор стратегии генерации первичного ключа может иметь большое значение. Один из распространенных способов создания идентификаторов — использовать последовательности базы данных, обычно по одной на таблицу, чтобы избежать конфликтов между вставками в разные таблицы.
Проблема заключается в том, что, если вставлено 50 записей, мы хотим избежать 50 обращений к сети в базу данных, чтобы получить 50 идентификаторов, в результате чего процесс Java в большинстве случаев зависает.
Как Hibernate обычно справляется с этим?
Hibernate предоставляет новые оптимизированные генераторы идентификаторов, которые позволяют избежать этой проблемы. А именно для последовательностей, по умолчанию используется генератор идентификаторов HiLo . Вот как работает генератор последовательности HiLo:
- вызовите последовательность один раз и получите 1000 (значение High)
- рассчитать 50 идентификаторов, как это:
- 1000 * 50 + 0 = 50000
- 1000 * 50 + 1 = 50001
- …
- 1000 * 50 + 49 = 50049, достигнуто низкое значение (50)
- последовательность вызовов для нового высокого значения 1001… и т. д.
Таким образом, из одного последовательного вызова было сгенерировано 50 ключей, что привело к сокращению накладных расходов.
Эти новые оптимизированные генераторы ключей включены в Hibernate 4 по умолчанию и даже могут быть отключены при необходимости, если для hibernate.id.new_generator_mappings установлено значение false.
Почему генерация первичного ключа все еще может быть проблемой?
Проблема заключается в том, что если вы объявили стратегию генерации ключей как AUTO , оптимизированные генераторы по- прежнему отключены, и ваше приложение получит огромное количество последовательных вызовов.
Чтобы убедиться, что новые оптимизированные генераторы включены, обязательно используйте стратегию SEQUENCE вместо AUTO :
|
1
2
3
|
@Id@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "your_key_generator")private Long id; |
Благодаря этому простому изменению улучшение в диапазоне от 10%-20% может быть измерено в приложениях с интенсивной вставкой, практически без изменений кода.
Быстрый выигрыш Совет 2 — Используйте пакетные вставки / обновления JDBC
Для пакетных программ драйверы JDBC обычно обеспечивают оптимизацию для сокращения сетевых обходов, называемых «пакетные вставки / обновления JDBC». Когда они используются, вставки / обновления ставятся в очередь на уровне драйвера перед отправкой в базу данных.
При достижении порогового значения весь пакет операторов в очереди отправляется в базу данных за один раз. Это препятствует тому, чтобы водитель отправлял операторы один за другим, что привело бы к множественным обходам сети.
Это конфигурация фабрики диспетчера сущностей, необходимая для активных пакетных вставок / обновлений:
|
1
2
3
|
<prop key="hibernate.jdbc.batch_size">100</prop> <prop key="hibernate.order_inserts">true</prop> <prop key="hibernate.order_updates">true</prop> |
Установка только размера пакета JDBC не будет работать. Это связано с тем, что драйвер JDBC будет пакетировать вставки только при получении вставки / обновлений для точно такой же таблицы.
Если получена вставка в новую таблицу, драйвер JDBC сначала сбросит пакетные операторы в предыдущей таблице, прежде чем начинать пакетные операторы в новой таблице.
Подобная функциональность неявно используется при использовании Spring Batch. Эта оптимизация может легко купить от 30% до 40% для «вставки интенсивных» программ без изменения одной строки кода.
Быстрый выигрыш Совет 3 — Периодически очищайте и очищайте сеанс Hibernate
При добавлении / изменении данных в базе данных Hibernate сохраняет в сеансе версию сущностей, которая уже сохранена, на случай, если они снова изменятся до закрытия сеанса.
Но много раз мы можем безопасно отбрасывать сущности после соответствующих вставок в базу данных. Это освобождает память в клиентском процессе Java, предотвращая проблемы с производительностью, вызванные длительными сеансами Hibernate.
Таких длительных сессий следует избегать, насколько это возможно, но если по какой-то причине они необходимы, вот как ограничить потребление памяти:
|
1
2
|
entityManager.flush();entityManager.clear(); |
flush вызовет вставки из новых сущностей для отправки в базу данных. clear освобождает новые сущности от сеанса.
Быстрый выигрыш Совет 4 — Сокращение накладных расходов на проверку Hibernate
Hibernate внутренне использует механизм для отслеживания измененных объектов, называемый грязной проверкой . Этот механизм не основан на методах equals и hashcode классов сущностей.
Hibernate делает все возможное, чтобы свести к минимуму затраты производительности на «грязную» проверку, и «грязную» проверку только тогда, когда это необходимо, но механизм имеет такую стоимость, которая более заметна в таблицах с большим количеством столбцов.
Перед применением какой-либо оптимизации наиболее важно измерить стоимость грязной проверки с помощью VisualVM.
Как избежать грязной проверки?
В бизнес-методах Spring, которые мы знаем, доступны только для чтения, грязная проверка может быть отключена следующим образом:
|
1
2
3
4
|
@Transactional(readOnly=true)public void someBusinessMethod() { ....} |
Альтернативой, позволяющей избежать грязной проверки, является использование сеанса без состояния гибернации, который подробно описан в документации .
Быстрый выигрыш Совет 5 — Поиск «плохих» планов запросов
Проверьте запросы в списке самых медленных запросов, чтобы увидеть, есть ли у них хорошие планы запросов. Наиболее распространенные «плохие» планы запросов:
- Полное сканирование таблицы: они происходят, когда таблица полностью сканируется из-за обычно отсутствующего индекса или устаревшей статистики таблицы.
- Полное декартово соединение: это означает, что вычисляется полное декартово произведение нескольких таблиц. Проверьте наличие пропущенных условий соединения или, если этого можно избежать, разделив шаг на несколько.
Быстрый выигрыш Совет 6 — проверьте правильность интервалов коммита
Если вы выполняете пакетную обработку, интервал принятия может существенно повлиять на производительность, например, в 10-100 раз быстрее.
Убедитесь, что интервал фиксации соответствует ожидаемому (обычно около 100-1000 для заданий Spring Batch). Часто этот параметр неправильно настроен.
Быстрый выигрыш Совет 7 — Использование кэшей второго уровня и запросов
Если некоторые данные определены как подходящие для кэширования, ознакомьтесь с этим сообщением в блоге, чтобы узнать, как настроить кэширование Hibernate: Подводные камни кэшей второго уровня / запросов Hibernate
Выводы
Чтобы решить проблемы с производительностью приложений, наиболее важным действием является сбор метрик, позволяющих определить текущее узкое место.
Без некоторых показателей часто невозможно вовремя угадать, какова правильная причина проблемы.
Кроме того, можно избежать многих, но не всех типичных ошибок производительности приложения, управляемого базой данных, с помощью среды Spring Batch.
| Ссылка: | Настройка производительности приложений Spring / Hibernate от нашего партнера JCG Алексея Новика в блоге The JHades Blog . |