Ctrl + Alt + M используется в IntelliJ IDEA для извлечения метода . Ctrl + Alt + M. Это так же просто, как выбрать кусок кода и нажать эту комбинацию. Затмение также имеет это . Я ненавижу длинные методы. До такой степени, что это пахнет слишком долго для меня:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
public void processOnEndOfDay(Contract c) { if (DateUtils.addDays(c.getCreated(), 7).before(new Date())) { priorityHandling(c, OUTDATED_FEE); notifyOutdated(c); log.info("Outdated: {}", c); } else { if(sendNotifications) { notifyPending(c); } log.debug("Pending {}", c); }} |
Прежде всего, это нечитаемое состояние. Неважно, как это реализовано, то, что оно делает, имеет значение. Итак, давайте сначала извлечем его:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
public void processOnEndOfDay(Contract c) { if (isOutdated(c)) { priorityHandling(c, OUTDATED_FEE); notifyOutdated(c); log.info("Outdated: {}", c); } else { if(sendNotifications) { notifyPending(c); } log.debug("Pending {}", c); }} private boolean isOutdated(Contract c) { return DateUtils.addDays(c.getCreated(), 7).before(new Date());} |
Видимо, этот метод на самом деле не принадлежит здесь ( F6 — метод перемещения экземпляра):
|
01
02
03
04
05
06
07
08
09
10
11
12
|
public void processOnEndOfDay(Contract c) { if (c.isOutdated()) { priorityHandling(c, OUTDATED_FEE); notifyOutdated(c); log.info("Outdated: {}", c); } else { if(sendNotifications) { notifyPending(c); } log.debug("Pending {}", c); }} |
Заметили разные? Моя IDE сделала isOutdated() экземпляром метода Contract , который звучит правильно. Но я все еще несчастен. В этом методе слишком много всего происходит. Одна ветвь выполняет некоторые связанные с бизнесом priorityHandling() , некоторые системные уведомления и ведение журнала. Другая ветка делает условные уведомления и логирование. Сначала давайте перенесем обработку устаревших контрактов на отдельный метод:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
public void processOnEndOfDay(Contract c) { if (c.isOutdated()) { handleOutdated(c); } else { if(sendNotifications) { notifyPending(c); } log.debug("Pending {}", c); }} private void handleOutdated(Contract c) { priorityHandling(c, OUTDATED_FEE); notifyOutdated(c); log.info("Outdated: {}", c);} |
Можно сказать, что этого достаточно, но я вижу поразительную асимметрию между ветвями. handleOutdated() очень высокоуровневый, в то время как ветка отправки — техническая. Программное обеспечение должно быть легко читаемым, поэтому не смешивайте разные уровни абстракции рядом друг с другом. Теперь я счастлив
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
public void processOnEndOfDay(Contract c) { if (c.isOutdated()) { handleOutdated(c); } else { stillPending(c); }} private void handleOutdated(Contract c) { priorityHandling(c, OUTDATED_FEE); notifyOutdated(c); log.info("Outdated: {}", c);} private void stillPending(Contract c) { if(sendNotifications) { notifyPending(c); } log.debug("Pending {}", c);} |
Этот пример был немного надуманным, но на самом деле я хотел доказать что-то другое. Не так часто в наши дни, но все еще есть разработчики, которые боятся извлекать методы, полагая, что это медленнее во время выполнения. Они не понимают, что JVM — это замечательный программный продукт (он, вероятно, намного превосходит язык Java), который имеет много по-настоящему удивительных встроенных оптимизаций во время выполнения. Прежде всего, более короткие методы легче рассуждать. Поток более очевиден, область действия короче, побочные эффекты лучше видны. При длинных методах JVM может просто сдаться. Вторая причина еще важнее:
Метод встраивания
Если JVM обнаруживает какой-то небольшой метод, выполняемый снова и снова, он просто заменяет каждый вызов этого метода своим телом. Возьмите это как пример:
|
1
2
3
4
5
6
7
|
private int add4(int x1, int x2, int x3, int x4) { return add2(x1, x2) + add2(x3, x4);} private int add2(int x1, int x2) { return x1 + x2;} |
Вы можете быть почти уверены, что через некоторое время JVM избавится от add2() и переведет ваш код в:
|
1
2
3
|
private int add4(int x1, int x2, int x3, int x4) { return x1 + x2 + x3 + x4;} |
Важным замечанием является то, что это JVM, а не компилятор. javac довольно консервативен при создании байт-кода и оставляет всю эту работу на JVM. Это дизайнерское решение оказалось блестящим:
- JVM знает больше о целевой среде, процессоре, памяти, архитектуре и может более агрессивно оптимизировать
- JVM может обнаружить характеристики времени выполнения вашего кода, например, какие методы выполняются чаще всего, какие виртуальные методы имеют только одну реализацию и т. Д.
-
.classскомпилированный с использованием старой Java, будет работать быстрее на более новой JVM. Скорее всего, вы будете обновлять Java, а не перекомпилировать исходный код.
Давайте проверим все эти предположения. Я написал небольшую программу с рабочим названием « Худшее применение принципа разделяй и властвуй» . add128() принимает 128 аргументов (!) И вызывает add64() дважды — с первой и второй половиной аргументов. add64() похож, за исключением того, что он вызывает add32() дважды. Я думаю, вы add2() идею, в конце мы add2() на add2() который делает тяжелую работу. Некоторые числа обрезаны, чтобы пощадить ваши глаза :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
public class ConcreteAdder { public int add128(int x1, int x2, int x3, int x4, ... more ..., int x127, int x128) { return add64(x1, x2, x3, x4, ... more ..., x63, x64) + add64(x65, x66, x67, x68, ... more ..., x127, x128); } private int add64(int x1, int x2, int x3, int x4, ... more ..., int x63, int x64) { return add32(x1, x2, x3, x4, ... more ..., x31, x32) + add32(x33, x34, x35, x36, ... more ..., x63, x64); } private int add32(int x1, int x2, int x3, int x4, ... more ..., int x31, int x32) { return add16(x1, x2, x3, x4, ... more ..., x15, x16) + add16(x17, x18, x19, x20, ... more ..., x31, x32); } private int add16(int x1, int x2, int x3, int x4, ... more ..., int x15, int x16) { return add8(x1, x2, x3, x4, x5, x6, x7, x8) + add8(x9, x10, x11, x12, x13, x14, x15, x16); } private int add8(int x1, int x2, int x3, int x4, int x5, int x6, int x7, int x8) { return add4(x1, x2, x3, x4) + add4(x5, x6, x7, x8); } private int add4(int x1, int x2, int x3, int x4) { return add2(x1, x2) + add2(x3, x4); } private int add2(int x1, int x2) { return x1 + x2; } } |
Нетрудно заметить, что, вызывая add128() мы делаем 127 вызовов метода. Много. Для справочных целей здесь приведена простая реализация :
|
1
2
3
4
5
|
public class InlineAdder { public int add128n(int x1, int x2, int x3, int x4, ... more ..., int x127, int x128) { return x1 + x2 + x3 + x4 + ... more ... + x127 + x128; } |
Наконец, я также включаю реализацию, которая использует abstract методы и наследование. 127 виртуальных звонков довольно дороги. Эти методы требуют динамической отправки и, следовательно, гораздо более требовательны, так как не могут быть встроены. Разве они не могут?
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
public abstract class Adder { public abstract int add128(int x1, int x2, int x3, int x4, ... more ..., int x127, int x128); public abstract int add64(int x1, int x2, int x3, int x4, ... more ..., int x63, int x64); public abstract int add32(int x1, int x2, int x3, int x4, ... more ..., int x31, int x32); public abstract int add16(int x1, int x2, int x3, int x4, ... more ..., int x15, int x16); public abstract int add8(int x1, int x2, int x3, int x4, int x5, int x6, int x7, int x8); public abstract int add4(int x1, int x2, int x3, int x4); public abstract int add2(int x1, int x2);} |
и реализация:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
public class VirtualAdder extends Adder { @Override public int add128(int x1, int x2, int x3, int x4, ... more ..., int x128) { return add64(x1, x2, x3, x4, ... more ..., x63, x64) + add64(x65, x66, x67, x68, ... more ..., x127, x128); } @Override public int add64(int x1, int x2, int x3, int x4, ... more ..., int x63, int x64) { return add32(x1, x2, x3, x4, ... more ..., x31, x32) + add32(x33, x34, x35, x36, ... more ..., x63, x64); } @Override public int add32(int x1, int x2, int x3, int x4, ... more ..., int x32) { return add16(x1, x2, x3, x4, ... more ..., x15, x16) + add16(x17, x18, x19, x20, ... more ..., x31, x32); } @Override public int add16(int x1, int x2, int x3, int x4, ... more ..., int x16) { return add8(x1, x2, x3, x4, x5, x6, x7, x8) + add8(x9, x10, x11, x12, x13, x14, x15, x16); } @Override public int add8(int x1, int x2, int x3, int x4, int x5, int x6, int x7, int x8) { return add4(x1, x2, x3, x4) + add4(x5, x6, x7, x8); } @Override public int add4(int x1, int x2, int x3, int x4) { return add2(x1, x2) + add2(x3, x4); } @Override public int add2(int x1, int x2) { return x1 + x2; } } |
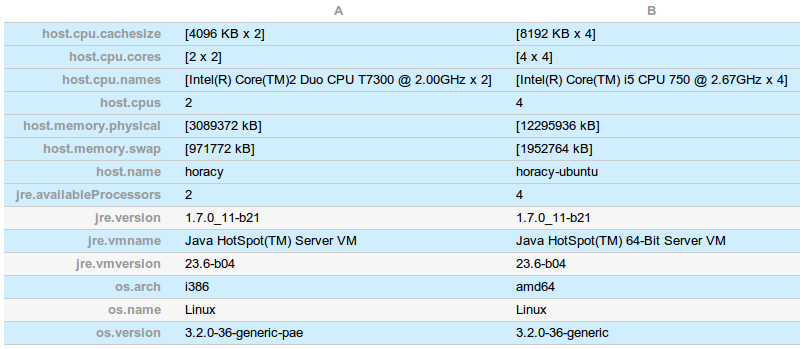
Воодушевленный некоторыми интересными комментариями читателей после моей статьи о накладных @Cacheable я написал быстрый тест для сравнения накладных расходов из-за извлеченных ConcreteAdder и VirtualAdder (чтобы увидеть накладные расходы виртуальных вызовов). Результаты неожиданны и немного неоднозначны. Я запускаю один и тот же тест на двух компьютерах (синий и красный), на одном и том же программном обеспечении, но второй имеет больше ядер и имеет 64-разрядную версию 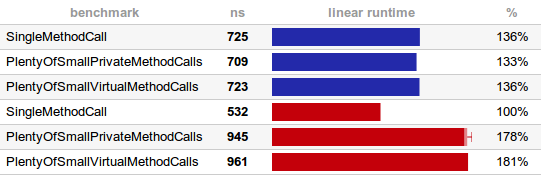
Подробные условия:
Оказывается, на более медленной машине A JVM решила все встроить. Не только простые private звонки, но и виртуальные. Как это возможно? Ну, JVM обнаружил, что существует только один подкласс Adder , таким образом, только одна возможная версия каждого abstract метода. Если во время выполнения вы загружаете другой подкласс (или даже больше подклассов), вы можете ожидать снижения производительности, так как встраивание больше невозможно. Но, оставив детали в стороне, в этом тесте вызовов методов не дешево, они фактически бесплатны ! Вызовы методов (их значительная документация улучшает читабельность) существуют только в вашем исходном коде и байт-коде. Во время выполнения они полностью исключены (встроены).
Я не совсем понимаю второй тест, хотя. Похоже, что более быстрый компьютер B действительно выполняет эталонный тест SingleMethodCall быстрее, но другие работают медленнее, даже по сравнению с A. Возможно, решили отложить врезку? Разница значительна, но не настолько велика. Опять же, как при оптимизации генерации трассировки стека — если вы начинаете оптимизировать свой код, вручную вставляя методы и, таким образом, делая их намного длиннее и сложнее, вы решаете не ту проблему.
Тест доступен на GitHub вместе с источником статьи . Я рекомендую вам запустить его на вашей установке. Более того, каждый запрос на выборку автоматически строится на Travis , поэтому вы можете легко сравнивать результаты в одной и той же среде.
Справка: Насколько агрессивен метод встраивания в JVM? от нашего партнера JCG Томаша Нуркевича в блоге о Java и соседстве .