

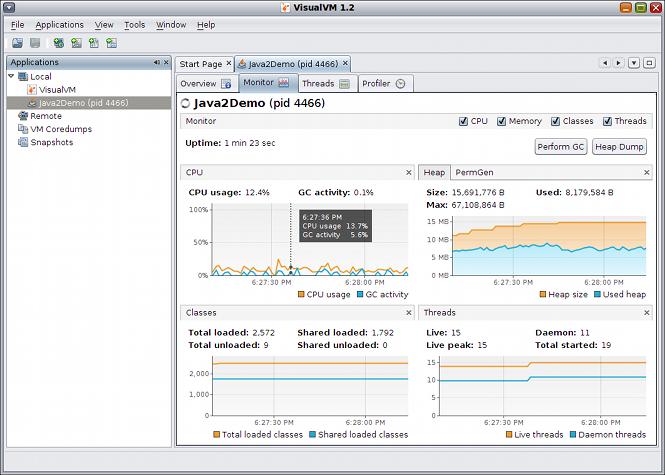
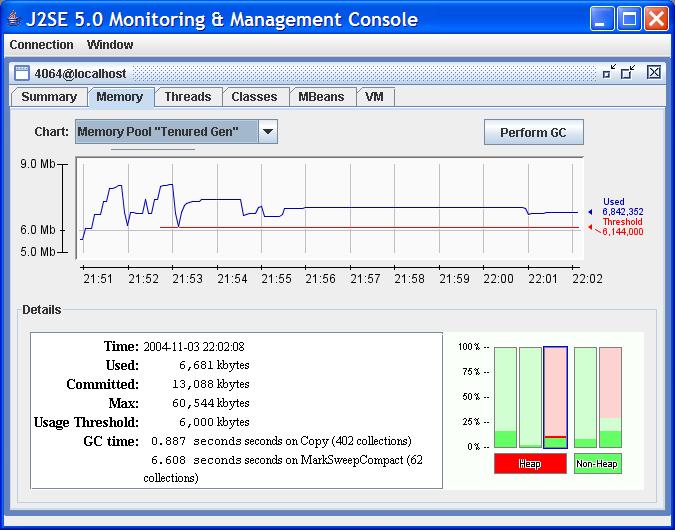

Плагин Java JMX Nagios N / A
Кроме того, существуют различные специальные инструменты, например, для ActiveMQ , JBoss , Quartz scheduler , Tomcat / tcServer … Так какой из них вы должны использовать в качестве основной панели мониторинга? Ну, ни один из них не предоставляет готовых функций, которые вам могут понадобиться. В некоторых приложениях вы должны постоянно следить за содержимым и размером данной очереди JMS. Другие, как известно, имеют проблемы с памятью или процессором. Я также видел программное обеспечение, в котором системным администраторам приходилось постоянно выполнять какой-либо SQL-запрос и проверять результаты или даже анализировать журналы, чтобы убедиться, что выполняется какой-то важный фоновый процесс. Возможности бесконечны, потому что это действительно зависит от программного обеспечения и его вариантов использования. Что еще хуже, вашего клиента не заботит активность GC, количество открытых соединений JDBC и не зависает ли этот неприятный пакетный процесс. Это должно просто работать .
В этом посте мы попытаемся разработать простую, дешевую, но мощную консоль управления. Он будет построен вокруг идеи единого двоичного результата — работает он или нет. Если этот единственный индикатор здоровья зеленый, нет необходимости углубляться. Но! Если он стал красным, мы можем легко развернуть. Это возможно, потому что вместо отображения сотен несвязанных метрик мы сгруппируем их в древовидную структуру. Состояние здоровья каждого узла в дереве так же плохо, как и у худшего ребенка. Таким образом, если с нашим приложением случится что-то плохое, оно начнет расти.
Мы не заставляем системного администратора постоянно отслеживать несколько показателей. Мы решаем, что важно, и если даже самая маленькая часть нашего программного обеспечения работает со сбоями, она появится. Сравните это с сервером непрерывной интеграции, у которого нет зеленых / красных сборок и уведомлений по электронной почте. Вместо этого вам нужно переходить на сервер при каждой другой сборке и вручную проверять, компилируется ли код и все ли тесты были зелеными. Журналы и результаты есть, но зачем разбирать их и агрегировать вручную? Это то, чего мы пытаемся избежать в нашем собственном решении для мониторинга.
В качестве основы я выбрал (не в первый раз ) мост Jolokia JMX to HTTP. JVM уже предоставляет инфраструктуру мониторинга, так зачем ее изобретать? Также благодаря Jolokia вся панель инструментов может быть реализована в JavaScript на стороне клиента. Это имеет несколько преимуществ: минимальная занимаемая площадь сервера, а также позволяет нам быстро настраивать метрики, добавляя их или изменяя пороги оповещения.
Мы начнем с загрузки различных метрик JMX на клиент (браузер). Я разработал небольшое приложение для демонстрационных целей, используя как можно больше технологий — Tomcat, Spring, Hibernate, ActiveMQ, Quartz и т. Д. Я не использую встроенную клиентскую библиотеку JavaScript для Jolokia, поскольку я считаю ее несколько громоздкой. Но, как вы можете видеть, это всего лишь один вызов AJAX для получения большого количества метрик.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
function request() { var mbeans = [ "java.lang:type=Memory", "java.lang:type=MemoryPool,name=Code Cache", "java.lang:type=MemoryPool,name=PS Eden Space", "java.lang:type=MemoryPool,name=PS Old Gen", "java.lang:type=MemoryPool,name=PS Perm Gen", "java.lang:type=MemoryPool,name=PS Survivor Space", "java.lang:type=OperatingSystem", "java.lang:type=Runtime", "java.lang:type=Threading", 'Catalina:name="http-bio-8080",type=ThreadPool', 'Catalina:type=GlobalRequestProcessor,name="http-bio-8080"', 'Catalina:type=Manager,context=/jmx-dashboard,host=localhost', 'org.hibernate:type=Statistics,application=jmx-dashboard', "net.sf.ehcache:type=CacheStatistics,CacheManager=jmx-dashboard,name=org.hibernate.cache.StandardQueryCache", "net.sf.ehcache:type=CacheStatistics,CacheManager=jmx-dashboard,name=org.hibernate.cache.UpdateTimestampsCache", "quartz:type=QuartzScheduler,name=schedulerFactory,instance=NON_CLUSTERED", 'org.apache.activemq:BrokerName=localhost,Type=Queue,Destination=requests', "com.blogspot.nurkiewicz.spring:name=dataSource,type=ManagedBasicDataSource" ]; return _.map(mbeans, function(mbean) { return { type:'read', mbean: mbean } });} $.ajax({ url: 'jmx?ignoreErrors=true', type: "POST", dataType: "json", data: JSON.stringify(request()), contentType: "application/json", success: function(response) { displayRawData(response); }}); |
Просто чтобы дать вам представление о том, какая информация доступна на клиентской стороне, мы сначала спустим все данные и отобразим их на аккордеоне jQuery UI :
|
01
02
03
04
05
06
07
08
09
10
|
function displayRawData(fullResponse) { _(fullResponse).each(function (response) { var content = $('<pre/>').append(JSON.stringify(response.value, null, '\t')); var header = $('<h3/>').append($("<a/>", {href:'#'}).append(response.request.mbean)); $('#rawDataPanel'). append(header). append($('<div/>').append(content)); }); $('#rawDataPanel').accordion({autoHeight: false, collapsible: true});} |
Помните, что это просто для справки и отладки, мы не стремимся отображать бесконечный список атрибутов JMX.


Как вы можете видеть, на самом деле можно реализовать полный порт jconsole в браузере с Jolokia и JavaScript… возможно, в следующий раз (кто-нибудь захочет помочь?). Возвращаясь к нашему проекту, давайте выберем несколько важных метрик и отобразим их в виде списка:

Сам список выглядит очень многообещающе. Вместо отображения графиков или значений я назначил значок для каждой метрики (подробнее об этом позже). Но я не хочу все время просматривать весь список. Почему у меня не может быть только одного индикатора, который объединяет несколько показателей? Поскольку мы уже используем jsTree , переход относительно прост:

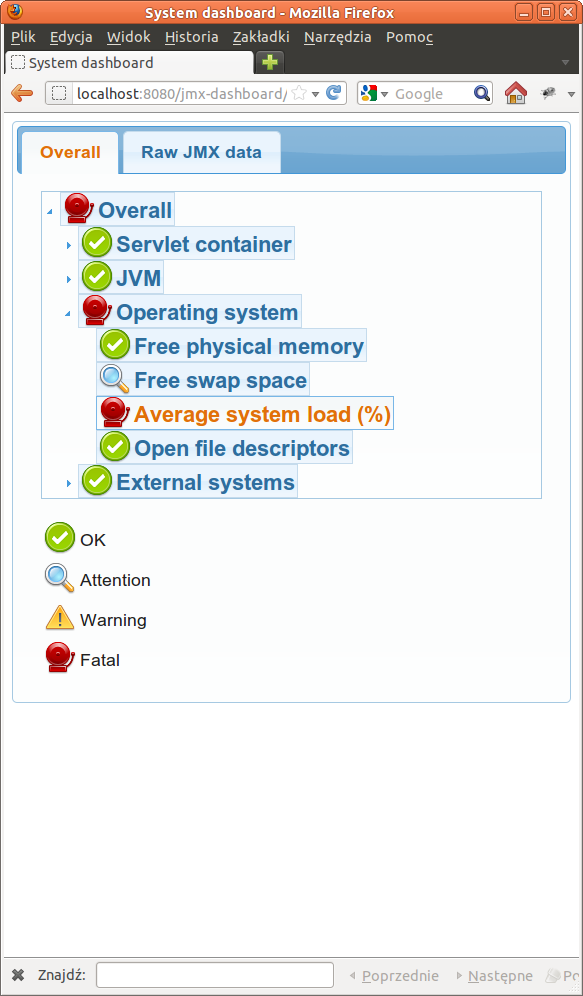
На первом скриншоте вы видите здоровую систему. На самом деле нет необходимости в детализации, так как общий показатель — зеленый. Однако ситуация хуже на втором скриншоте. Загрузка системы тревожно высока, также пространство подкачки требует внимания, но это не так важно. Как вы можете видеть, предыдущие метрики всплывают на всем пути к общей, верхней метрике. Таким образом, мы можем легко обнаружить, что неправильно работает в нашей системе. Вам может быть интересно, как мы достигли этого красивого дерева, в то время как в начале у нас были только необработанные данные JMX? Никакой магии здесь, посмотрите, как я строю дерево:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
function buildTreeModel(jmx) { return new CompositeNode('Overall', [ new CompositeNode('Servlet container', [ new Node( 'Active HTTP sessions', jmx['Catalina:context=/jmx-dashboard,host=localhost,type=Manager'].activeSessions, Node.threshold(200, 300, 500) ), new Node( 'HTTP sessions create rate', jmx['Catalina:context=/jmx-dashboard,host=localhost,type=Manager'].sessionCreateRate, Node.threshold(5, 10, 50) ), new Node( 'Rejected HTTP sessions', jmx['Catalina:context=/jmx-dashboard,host=localhost,type=Manager'].rejectedSessions, Node.threshold(1, 5, 10) ), new Node( 'Busy worker threads count', jmx['Catalina:name="http-bio-8080",type=ThreadPool'].currentThreadsBusy, Node.relativeThreshold(0.85, 0.9, 0.95, jmx['Catalina:name="http-bio-8080",type=ThreadPool'].maxThreads) ) ]), //... new CompositeNode('External systems', [ new CompositeNode('Persistence', [ new Node( 'Active database connections', jmx['com.blogspot.nurkiewicz.spring:name=dataSource,type=ManagedBasicDataSource'].NumActive, Node.relativeThreshold(0.75, 0.85, 0.95, jmx['com.blogspot.nurkiewicz.spring:name=dataSource,type=ManagedBasicDataSource'].MaxActive) ) ]), new CompositeNode('JMS messaging broker', [ new Node( 'Waiting in "requests" queue', jmx['org.apache.activemq:BrokerName=localhost,Destination=requests,Type=Queue'].QueueSize, Node.threshold(2, 5, 10) ), new Node( 'Number of consumers', jmx['org.apache.activemq:BrokerName=localhost,Destination=requests,Type=Queue'].ConsumerCount, Node.threshold(0.2, 0.1, 0) ) ]) ]) ]);} |
Модель дерева довольно проста. Корневой узел может иметь список дочерних узлов. Каждый дочерний узел может быть либо листом, представляющим одну оцененную метрику JMX, либо составным узлом, представляющим набор внуков. Каждый внук по очереди может быть листом или еще одним составным узлом. Да, это простой пример шаблона Composite ! Однако неясно, где использовался шаблон стратегии . Посмотрите, у каждого объекта конечного узла есть три свойства: метка (то, что вы видите на экране), значение (одиночная метрика JMX) и нечетная функция Node.threshold (200, 300, 500)… Что это? На самом деле это функция более высокого порядка (функция, возвращающая функцию), используемая позже для интерпретации метрики JMX. Помните, что исходное значение не имеет смысла, оно должно быть интерпретировано и переведено в красивый значок индикатора. Вот как работает эта реализация:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
Node.threshold = function(attention, warning, fatal) { if(attention > warning && warning > fatal) { return function(value) { if(value > attention) { return 1.0; } if(value > warning) { return 0.5; } if(value > fatal) { return 0.0; } else { return -1.0; } } } if(attention < warning && warning < fatal) { return function(value) { if(value < attention) { return 1.0; } if(value < warning) { return 0.5; } if(value < fatal) { return 0.0; } else { return -1.0; } } } throw new Error("All thresholds should either be increasing or decreasing: " + attention + ", " + warning + ", " + fatal); } |
Теперь становится понятно. Функция получает пороговые значения уровня и возвращает функцию, которая переводит их в число в диапазоне -1: 1. Я мог бы вернуть значки напрямую, но я хотел абстрагировать модель дерева от графического представления. Если вы теперь вернетесь к примеру Node.threshold (200, 300, 500) примера метрики « Активные сеансы HTTP», то, наконец, станет очевидно: если число активных сеансов HTTP превышает 200, показывайте значок внимания вместо «ОК». Если оно превышает 300, появляется предупреждение . Выше 500 появится смертельный значок. Эта функция — стратегия, которая понимает ввод и обрабатывает его так или иначе.
Конечно, эти значения / функции являются только примерами, но именно здесь проявляется настоящая тяжелая работа — для каждой метрики JMX вы должны определить набор нормальных пороговых значений. 500 HTTP-сессий — это катастрофа или только высокая нагрузка? Является ли загрузка процессора 90% проблемной или, может быть, если она действительно низкая, нам стоит начать беспокоиться? Как только вы настроите эти уровни, вам больше не нужно будет следить за всем одновременно. Достаточно взглянуть на метрику верхнего уровня. Если он зеленый, сделайте перерыв. Если это не так, просмотрите детали за несколько секунд, чтобы найти реальную проблему. Просто и эффективно. И я упоминал, что это не требует никаких изменений на стороне сервера (кроме добавления Jolokia и сопоставления его с некоторым URL)?
Очевидно, что это всего лишь небольшое подтверждение концепции, а не полное решение для мониторинга. Однако, если вы хотите попробовать и улучшить его, весь исходный код доступен — как всегда, в моей учетной записи GitHub.
Справка: Мониторинг сервера на стороне клиента с помощью Jolokia и JMX от нашего партнера JCG