Когда я впервые услышал постановку задачи, я сразу понял, что нужно. Тем не менее, мой подход в этот раз будет отличаться от прошлого. Это было просто связано с тем, как я смотрю на технологии в моей жизни сегодня. Я не буду вдаваться в какие-либо нетехнические аспекты и сразу же перейду к проблеме и ее решению. Я начал смотреть на то, что существовало на рынке, и наткнулся на пару постов, которые помогли мне правильно распределить свои мысли.
Постановка задачи
Нам нужно решение для пакетной миграции. Мы переносим данные из Системы 1 в Систему 2, и в процессе нам нужно выполнить три задачи:
- Загрузка данных из базы данных на основе групп
- Обработать данные
- Обновите записи, загруженные на шаге 1, с изменениями
Мы должны обработать сотни групп, и каждая группа будет иметь около 40 тысяч записей. Вы можете себе представить количество времени, которое потребовалось бы, если бы мы выполнили это упражнение синхронно. Изображение здесь объясняет эту проблему эффективным способом.
 |
| Производитель Потребитель: проблема |
Модель производителя и потребителя
Давайте сначала посмотрим на шаблон «Потребитель-производитель». Если вы обратитесь к постановке задачи выше и посмотрите на изображение, мы увидим, что есть очень много сущностей, которые готовы со своей частью данных. Однако не хватает работников, которые могут обрабатывать все данные. Следовательно, поскольку производители продолжают выстраиваться в очередь, она просто продолжает расти. Мы видим, что системы начинают перегружать потоки и занимают много времени.
Промежуточное решение
 |
| Производитель Потребитель: Промежуточный подход |
У нас есть промежуточное решение. Обратитесь к изображению, и вы сразу же заметите, что продюсеры накапливают свою работу в шкафу для хранения документов, и рабочий продолжает поднимать ее, как только они закончили с предыдущим заданием. Однако у этого подхода есть некоторые явные недостатки:
- Есть еще один работник, который должен сделать всю работу. Внешние системы могут быть счастливы, но задача будет продолжать существовать, пока работник не выполнит все задачи
- Производители накапливают свои данные в очереди, и для этого нужны ресурсы. Как и в этом примере, кабинет может заполниться, то же самое может произойти и с ресурсами JVM. Нам нужно быть осторожными, сколько данных мы собираемся поместить в память, а в некоторых случаях их может быть немного.
Решение
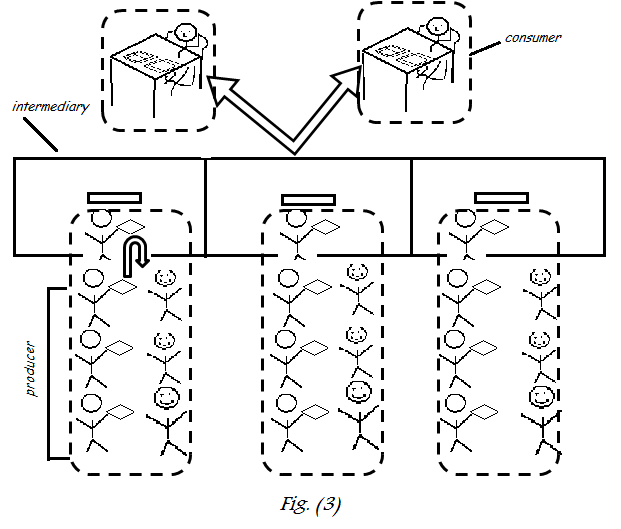 |
| Производитель Потребитель: решение |
Решение — это то, что мы видим каждый день во многих местах — например, очередь в кинозале, бензиновые насосы и т. Д. Есть так много людей, которые приходят, чтобы забронировать билет, и исходя из того, сколько людей приходит, тем больше людей добавляется к выдаче билетов , По сути, обратитесь к изображению здесь, и вы заметите, что производители будут продолжать добавлять свои работы в кабинет, и у нас есть больше работников для обработки рабочей нагрузки.
Java предоставила пакет параллелизма для решения этой проблемы. До сих пор я всегда работал над многопоточностью на гораздо более низком уровне, и я впервые собирался работать с этим пакетом. Когда я начал изучать Интернет и читать блоггерам то, что они говорят, я наткнулся на одну очень хорошую статью . Это помогло понять использование BlockingQueue очень эффективным способом. Тем не менее, решения, предоставленные Dhruba, не помогли бы мне достичь необходимой высокой пропускной способности. Итак, я начал исследовать использование ArrayBlockingQueue для того же самого.
Контроллер
Это первый класс, где контракт между производителями и потребителями управляется. Контроллер настроит 1 поток для источника и 2 потока для потребителя. Исходя из потребностей, мы можем создать столько потоков, сколько нам нужно; и даже может даже прочитать данные из свойств или сделать некоторую динамическую магию. Пока мы будем держать это просто.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
package com.kapil.techieforever.producerconsumer;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.Future;public class TestProducerConsumer{public static void main(String args[]){try{Broker broker = new Broker();ExecutorService threadPool = Executors.newFixedThreadPool(3);threadPool.execute(new Consumer("1", broker));threadPool.execute(new Consumer("2", broker));Future producerStatus = threadPool.submit(new Producer(broker));// this will wait for the producer to finish its execution.producerStatus.get();threadPool.shutdown();}catch (Exception e){e.printStackTrace();}}} |
Я использую ExecuteService для создания пула потоков и управления им. Вместо использования базовой реализации Thread, это более эффективный способ, поскольку он будет обрабатывать выход и перезапуск потоков по мере необходимости. Вы также заметите, что я использую класс Future для получения статуса потока продюсера. Этот класс очень эффективен и остановит мою программу от дальнейшего выполнения. Это хороший способ замены метода «.join» в потоках. Примечание: в этом примере я не очень эффективно использую Future; поэтому вам, возможно, придется попробовать несколько вещей по своему усмотрению.
Также следует отметить класс Broker, который используется в качестве шкафа для хранения документов между производителями и потребителями. Мы увидим его реализацию в самое ближайшее время.
Продюсер
Этот класс отвечает за создание данных, над которыми нужно работать.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
package com.kapil.techieforever.producerconsumer;public class Producer implements Runnable{private Broker broker;public Producer(Broker broker){this.broker = broker;}@Overridepublic void run(){try{for (Integer i = 1; i < 5 + 1; ++i){System.out.println("Producer produced: " + i);Thread.sleep(100);broker.put(i);}this.broker.continueProducing = Boolean.FALSE;System.out.println("Producer finished its job; terminating.");}catch (InterruptedException ex){ex.printStackTrace();}}} |
Этот класс делает самые простые вещи, которые он может сделать — добавление целого числа к брокеру. Некоторые ключевые области, на которые следует обратить внимание:
1. В Broker есть свойство, которое в конце обновляется производителем, когда оно завершено. Это также известно как «окончательная» или «отравленная» запись. Это используется потребителями, чтобы знать, что больше нет данных, поступающих
2. Я использовал Thread.sleep, чтобы имитировать, что некоторым производителям может потребоваться больше времени для получения данных. Вы можете настроить это значение и увидеть, как потребители действуют
Потребитель
Этот класс отвечает за чтение данных от брокера и выполнение своей работы
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
package com.kapil.techieforever.producerconsumer;public class Consumer implements Runnable{private String name;private Broker broker;public Consumer(String name, Broker broker){this.name = name;this.broker = broker;}@Overridepublic void run(){try{Integer data = broker.get();while (broker.continueProducing || data != null){Thread.sleep(1000);System.out.println("Consumer " + this.name + " processed data from broker: " + data);data = broker.get();}System.out.println("Comsumer " + this.name + " finished its job; terminating.");}catch (InterruptedException ex){ex.printStackTrace();}}} |
Это снова простой класс, который читает Integer и печатает его на консоли. Тем не менее, ключевые моменты, на которые следует обратить внимание:
1. Цикл для обработки данных представляет собой бесконечный цикл, который выполняется в двух условиях — до тех пор, пока производитель не потребит и не будет данных у брокера.
2. Опять же, Thread.sleep используется для создания эффективных и разных сценариев.
Брокер
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
package com.kapil.techieforever.producerconsumer;import java.util.concurrent.ArrayBlockingQueue;import java.util.concurrent.TimeUnit;public class Broker{public ArrayBlockingQueue queue = new ArrayBlockingQueue(100);public Boolean continueProducing = Boolean.TRUE;public void put(Integer data) throws InterruptedException{this.queue.put(data);}public Integer get() throws InterruptedException{return this.queue.poll(1, TimeUnit.SECONDS);}} |
Первое, что нужно отметить, это то, что мы используем ArrayBlockingQueue в качестве держателя данных. Я не собираюсь говорить, что это делает, но настаиваю, чтобы вы прочитали это на JavaDocs здесь. однако я объясню, что производители собираются поместить данные в очередь, а потребители будут извлекать данные из очереди в формате FIFO. Но если производители работают медленно, потребители будут ждать поступления данных, а если массив заполнен, производители будут ждать его заполнения.
Также обратите внимание, что я использую функцию ‘poll’ вместо того, чтобы попасть в очередь. Это сделано для того, чтобы потребители не дождались вечно, а время ожидания истекло через несколько секунд. Это помогает нам во взаимодействии и убивает потребителей, когда обрабатываются все данные. (Примечание: попробуйте заменить poll на get, и вы увидите некоторые интересные результаты).
Код
У меня есть код, сидящий на хостинге проекта Google . Не стесняйтесь перейти и скачать его оттуда. По сути, это проект затмения (Spring STS). Вы также можете получить дополнительные пакеты и классы при загрузке, основываясь на том, когда вы их загружаете. Не стесняйтесь смотреть на них тоже и поделиться своими комментариями
— Вы можете просмотреть исходный код в браузере SVN или;
— Вы можете скачать его из самого проекта .
Решение проблемы
Изначально я разместил это решение посередине, но потом понял, что это не тот способ, и поэтому я вынул его из основного контента и поместил в конце. Другим вариантом окончательного решения может быть то, что рабочие / потребители не берут по одной работе за раз, а собирают несколько работ вместе и заканчивают их, прежде чем перейти к следующему набору. Такой подход может привести к схожим результатам, но в некоторых случаях, когда у нас есть рабочие места, которые не занимают одно и то же время, это может означать, что некоторые работники в конечном итоге окажутся более узкими, чем другие. И, если задания распределяются заранее, что означает, что все потребители будут иметь все задания до их обработки (не шаблон «производитель-потребитель»), тогда эта проблема может сложиться еще больше и привести к большим задержкам в логике обработки.
Статьи по Теме
- Очереди — это собственные структуры данных дьявола (petewarden.typepad.com)
- Я ошибаюсь, что очереди — маленькие помощники сатаны? (Petewarden.typepad.com)
- http://code.google.com/p/disruptor/
Ссылка: шаблон параллелизма: производитель и потребитель от нашего партнера JCG Капил Вирен Ахуджа в блоге Scratch Pad .