Microsoft SQL Server 2016 недавно стал лидером в системах управления реляционными базами данных (RDBMS). Сочетание высокой производительности, безопасности, аналитики и совместимости с облаком делает его ведущей СУБД . SQL Server 2017 даже поддерживает языки программирования R и Python, что еще больше повышает его привлекательность для специалистов по данным и специалистов по данным в академических учреждениях.
Настало время стать разработчиком SQL Server по многим причинам, которые выходят за рамки этой статьи, но для краткого изложения их: SQL Server не только стал СУБД номер один, но и стал больше, чем СУБД.
Имея в виду эти впечатляющие новые выпуски SQL Server, вы можете подумать, как извлечь максимальную пользу из функций, которые, как вы ожидаете, окажут наибольшее влияние на вашу общую производительность, особенно если у вас нет опыта. Если, с другой стороны, вы не посещаете каждый вебинар и не просматриваете каждую статью о новых функциях, то не стоит слишком беспокоиться; множество компаний по-прежнему используют SQL Server 2008 R2, особенно в таких жестко регулируемых отраслях, как финансы и здравоохранение.
Я хотел бы предостеречь любого от сосредоточения внимания на каких-либо новых функциях и возможностях SQL Server без предварительного ознакомления (если не овладения) необходимыми навыками.
В этой статье объясняется, почему метаданные ценны, что такое метаданные, а затем рассматриваются две практические проблемы, которые решаются с помощью кода Transact-SQL (T-SQL), который ссылается на метаданные. От запросов к представлениям каталога до динамического использования метаданных вы должны уйти со знаниями, которые сделают ваши навыки разработки на SQL Server значительно более ценными за счет сокращения времени и усилий, необходимых для ознакомления с данными и самостоятельного решения проблем.
Независимо от вашей отрасли, компании или даже текущей версии SQL Server, которую вы используете, эти три общих навыка, которые вы можете освоить, легко переносимы — даже при относительно больших скачках в версиях программного обеспечения (например, с SQL Server 2008 R2 до 2014) ,
Три основных навыка SQL Server для разработчиков
SQL — это первый и наиболее очевидный навык, в котором вы должны быть компетентны. Одна из основных причин изучения этого языка сценариев (помимо того, что он интересный) заключается в том, насколько он переносим, даже через другие РСУБД. Конечно, я говорю о синтаксисе стандартного SQL (SQL) Американского национального института стандартов (ANSI), не обязательно T-SQL, который является диалектом Microsoft от SQL. Лично я также обнаружил, что легче изучать новые элементы синтаксиса SQL / T-SQL, чем настраиваться на новые функции в графическом интерфейсе пользователя. Для целей этой статьи я сосредоточусь на T-SQL, исходя из предположения, что любой, кто читает этот фрагмент, является разновидностью разработчика SQL Server.
PowerShell — это второй навык. PowerShell — это еще один язык сценариев, который позволяет пользователям автоматизировать различные полезные задачи, которые часто включают запуск отчетов служб отчетов SQL Server, планирование заданий и в основном выполнение работы администратора базы данных (DBA). Однако то, что делает PowerShell еще более привлекательным, — это то, что он заменяет пакетный язык Windows DOS (т. Е. Язык пакетной обработки, который вы используете в командной строке), в котором используются объекты и методы .NET. Еще одной причиной его значимости является тот факт, что в отличие от T-SQL PowerShell может автоматизировать задачи, которые охватывают среды Windows и SQL Server.
Помимо этих двух богатых языков сценариев, есть еще один навык, который будет очень полезен для любого пользователя SQL Server, который хорошо разбирается в нем, — это использование метаданных . Технически, понимание метаданных SQL Server (для целей данной статьи все ссылки на «метаданные» подразумевают «SQL Server», если не указано иное) является предметом изучения и возможностью применять и применять навыки (т. Е. Запоминание отношений и обучение T-SQL) — сам по себе не навык. По этой причине всякий раз, когда я ссылаюсь на «использование метаданных», я имею в виду «насколько хорошо разработчик применяет знания метаданных в T-SQL».
Однако я бы сказал, что метаданные также являются одной из самых недооцененных и недооцененных тем в сообществе разработчиков (хотя изучение T-SQL явно не так). Многие вводные книги по SQL Server или T-SQL даже не обсуждают это до более поздних глав, если вообще, и даже потом, в мелких деталях.
Ознакомление с метаданными SQL Server — гораздо более ценный навык, чем кажется большинству инструкторов, особенно для начинающих, потому что это практическое средство применения знаний в теоретических концепциях языка SQL, проектирования баз данных, а также физической и логической обработки.
Даже для более опытных разработчиков и администраторов баз данных метаданные SQL Server могут быть чрезвычайно ценными, поскольку их полезность масштабируется с вашей креативностью и компетенцией в других областях проектирования и программирования баз данных. В этой статье я приведу примеры сценариев T-SQL, которые усложняются, и покажу, как ознакомление с метаданными может оказаться неоценимым при попытке решить проблемы.
Прежде чем углубиться в примеры, я должен сделать пару важных общих замечаний. Веб-сайт Microsoft, обычно называемый «Книгами в Интернете» (BOL), является единственным лучшим ресурсом, который я могу рекомендовать по этой теме. Фактически, вы должны просмотреть эту страницу, чтобы ознакомиться с различными типами метаданных, и эту страницу о том, как вам следует обращаться к метаданным (т. Е. Использовать представления каталога).
Основные запросы метаданных
Простота и гибкость запросов к представлениям каталога объектов позволяет даже пользователям с минимальными знаниями SQL удивительно хорошо исследовать объекты и отношения в базе данных. Позвольте мне на небольшом примере продемонстрировать, почему метаданные полезны для разработчиков.
Для тех, кто заинтересован в следующем, обратите внимание, что я использую SQL Server 2016 Express Edition и образец базы данных AdventureWorks2014 (обе полностью бесплатны).
Представьте, что вы новый сотрудник вымышленной компании Adventure Works Cycles. Посмотрев несколько таблиц, вы заметите, что столбец с именем «BusinessEntityId» выглядит довольно немного. Не было бы неплохо, чтобы запрос отображал каждый столбец с таким именем в базе данных? Понимание основ метаданных SQL Server делает это легко.
Поскольку вам известны [sys]. [All_objects], [sys]. [Schemas] и [sys]. [All_columns], вы можете написать простой запрос для достижения этого единого представления BusinessEntityId.
|
01
02
03
04
05
06
07
08
09
10
11
|
use AdventureWorks2014goselect s.name as 'SchemaName',o.name as 'TableName',c.name as 'ColumnName'from sys.schemas as s inner join sys.all_objects as o on s.schema_id = o.schema_id inner join sys.all_columns as c on c.object_id = o.object_idwhere c.name like 'BusinessEntityId'and o.type = 'U'order by SchemaName,TableName,ColumnName; |
Вот набор результатов:
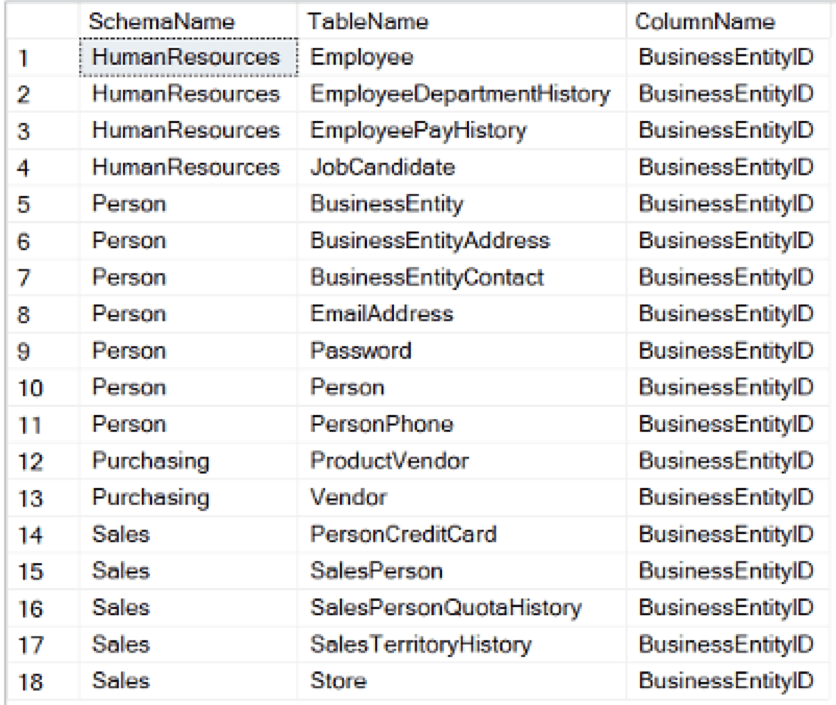
Метаданные предназначены не только для написания базовых специальных запросов. Рассмотрите возможность делать невероятно сложные запросы, чтобы отвечать на чрезвычайно сложные или трудоемкие вопросы. Например, сколько дублирующих индексов существует в данной базе данных? Какие это типы индексов?
Знакомство с метаданными, особенно с помощью представлений каталога и динамических представлений управления (DMV), чрезвычайно ценно независимо от вашего текущего уровня навыков T-SQL. Это забавный и доступный механизм для оттачивания ваших знаний как языка T-SQL, так и основных данных компании, который расширяется с ростом вашей компетенции в программировании баз данных.
Теперь следуйте комментариям в оставшихся запросах, которые демонстрируют, как изучение основных данных с метаданными (в сочетании с небольшим знанием бизнеса) может помочь вам независимо ответить на вопросы.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
use AdventureWorks2014goselect s.name as 'SchemaName',o.name as 'TableName',c.name as 'ColumnName'from sys.schemas as s inner join sys.all_objects as o on s.schema_id = o.schema_id inner join sys.all_columns as c on c.object_id = o.object_idwhere c.name like 'BusinessEntityId'and o.type = 'U'order by SchemaName,TableName,ColumnName;--Now join two tables using BusinessEntityIdselect *from HumanResources.Employee as e inner join Person.Person as p on e.BusinessEntityID = p.BusinessEntityIDorder by p.BusinessEntityID;--hmm, it looks like PersonType "EM" stands for "Employee," but what does "SP" mean?--let's see if there are any other PersonType valuesselect distinct PersonTypefrom HumanResources.Employee as e inner join Person.Person as p on e.BusinessEntityID = p.BusinessEntityIDorder by p.BusinessEntityID;--apparently, there are none--run the previous query again and look for patterns--perhaps it has something to do with JobTitle?select distinct p.PersonType,e.JobTitlefrom HumanResources.Employee as e inner join Person.Person as p on e.BusinessEntityID = p.BusinessEntityIDorder by p.BusinessEntityID;--looks like it could have something to do with all sales-related jobs |
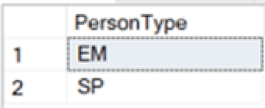
Можно многое узнать независимо от данных компании, если вы знаете, как обращаться с метаданными SQL Server.
Расширенное применение метаданных
Но как насчет более сложного применения метаданных? Что делать, если вы опытный разработчик, который работал в компании в течение многих лет? Почему вы должны узнать о метаданных SQL Server? Что ж, более сложный пример может убедить вас.
В одной из презентаций Гранта Фричи на мероприятии локальной группы пользователей PASS он описал 10 советов о том, как повысить производительность SQL Server. Один из них заключался в том, чтобы искать вложенные представления и переписывать их (в идеале, объединяя таблицы). Под «вложенным» я подразумеваю, что представления создаются со ссылкой на другие представления в их определении. Чем больше уровней вложенности в данном определении представления, тем больше будет снижаться производительность.
Очевидное решение состоит в том, чтобы не писать вложенные представления, но даже это не оправдывает отказ от их гипотетического существования, потому что, делая это, вы снижаете свой уровень настройки производительности и полагаетесь на предположение, что это не станет проблемой в будущем. Более того, если вы исследуете проблемы с производительностью базы данных и не знаете, мешают ли вложенные представления вашей базе данных, то, возможно, стоит потратить ваше время, чтобы хотя бы взглянуть, чтобы проверить, является ли эта проблема той, которую вы должны распутать или нет. ,
Но как ты мог сделать это? Помимо ручного щелчка правой кнопкой мыши по каждому представлению в проводнике объектов и просмотра определений, почему бы не создать хранимую процедуру метаданных, которая использует динамический SQL, чтобы дать вам ответ?
Я написал две хранимые процедуры, на которые ссылаются позже в этой статье, которые помогут вам начать решать эту проблему. Оказывается, есть системная функция с именем «sys.dm_sql_referenced_entities», которая принимает два входных параметра: квалифицированное имя представления (т. Е. «Schema.view» или «[schema]. [View]») и «ссылающийся класс».
Для целей этой статьи просто знайте, что нас интересуют только объекты базы данных, а это значит, что нам нужно использовать строку «объект» во втором параметре. Если вам интересно, вы можете просмотреть ссылки на триггеры, если используете другой ссылочный класс. Для получения дополнительной информации см. Эту ссылку .
Теперь, когда я упомянул «динамический sql», я должен рассмотреть две категории возможных проблем: безопасность и производительность.
Затраты на динамический SQL: безопасность и производительность

Динамический SQL — это в основном «SQL, который пишет SQL». Хотя это невероятно полезно для хранимых процедур, оно сопряжено с некоторыми затратами. Прежде чем подробно остановиться на этих затратах, я должен заявить, что они незначительны по сравнению с долгосрочным эффектом, который вложенные представления могут оказать на базу данных.
Мне хорошо известно, что SQL-инъекция представляет собой серьезную угрозу безопасности, которая становится возможной, когда разработчики пишут динамический SQL. К счастью для меня, «родительская» хранимая процедура не принимает вводимые пользователем данные и не предназначена для использования в любых клиентских приложениях. В частности, динамический SQL не принимает пользовательский ввод из внешнего интерфейса приложения для получения значений его параметров.
Если, с другой стороны, вас беспокоит производительность динамического SQL, у меня есть два ответа для вас:
Прежде всего, целью этого упражнения «вложенных представлений» является повышение общей производительности базы данных путем решения потенциально серьезной проблемы, которая должна возникать очень редко (то есть, если у вас нет команды разработчиков, которые продолжают регулярно вкладывать представления, в этом случае у вас возникает гораздо большая проблема).
Поскольку проблема (теоретически) возникает нечасто, вы должны запускать код только нечасто, а это означает, что низкая производительность кода будет беспокоить только несколько раз, когда вы ее запускаете. Другими словами, вы полностью упускаете контекст проблемы, если сосредоточены на производительности этих процедур за счет производительности всей базы данных, поэтому не стоит слишком критически относиться к производительности этого кода (но не стесняйтесь настраивать это больше, если вы можете).
Во-вторых, вы также можете быть обеспокоены тем, что производительность страдает из-за очень нереляционной природы динамического SQL. Я полностью согласен с мнением о том, что любой, кто пишет SQL, должен стремиться делать это реляционно (т. Е. Писать в соответствии с принципами теории множеств), когда это возможно. К сожалению, нет альтернативного подхода к решению этой проблемы, который бы соответствовал реляционной модели больше, чем эта. Если вы не согласны или нашли какой-либо способ улучшить мой код, сделав его более реляционным, немедленно свяжитесь со мной. Я должен также упомянуть, что я написал целую статью на эту тему .
Чтобы быстро обобщить критические замечания: риски безопасности и проблемы с производительностью незначительны по сравнению с долгосрочными и совокупными, снижающими производительность эффектами, которые вложенные представления могут оказывать на растущую базу данных. Сам код может быть не оптимизирован для масштабируемости и производительности, но при правильном использовании он поможет вам обеспечить работоспособность ваших баз данных.
Создание динамических метаданных
Итак, стоит ли динамический SQL этих рисков? Лучший ответ, который я могу вам дать, это то, что это зависит от ценности проблемы, которую вы пытаетесь решить. Динамический SQL — это дополнительный инструмент в наборе инструментов разработчика SQL, который значительно увеличивает количество способов решения проблем. Первым шагом в автоматизации этого поиска мусора с вложенным представлением является написание динамического оператора SQL с использованием sys.dm_sql_referenced_entities (для краткости я буду использовать «ссылочные объекты»), чтобы возвращать имена всех ссылочных представлений и частоту ссылок:
[DBO]. [CountObjectReferences]
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
use [AdventureWorks2014]gocreate procedure [dbo].[CountObjectReferences] ( @QualifiedView as varchar(255), @RefCount as int output) as/*******************************************************************************************************************Author: Alex FlemingCreate Date: 11-05-2017This stored procedure accepts a string that contains a qualified view or table and returns the number of references.Examples of valid parameters: 'Sales.vStoreWithContacts' or '[Sales].[vStoreWithContacts]'*******************************************************************************************************************/set nocount on;begindeclare @DynamicSQL varchar(3000) = ( 'select count(*) from sys.dm_sql_referenced_entities(' + '''' + @QualifiedView + '''' + ',''object'') as RefEnt inner join sys.all_views as AllViews on RefEnt.referenced_id = AllViews.object_id where RefEnt.referenced_class = 1 and RefEnt.referenced_minor_name is null;');exec (@DynamicSQL);end;/********************************Test*********************************************Note: AdventureWorks2014 does not contain any nested views out-of-the-box.Consequently, I have created several for testing. Here's the definition of two (one of them is nested by two levels):create view [HumanResources].[DuplicateEmployeeView] as (select *from HumanResources.vEmployee ------standard view in AdventureWorks2014------);create view [HumanResources].[DuplicateEmployeeView3] as (select *from HumanResources.DuplicateEmployeeView);declare @RefCount int;exec dbo.CountObjectReferences @QualifiedView = 'HumanResources.DuplicateEmployeeView3', @RefCount = @RefCount output;*********************************************************************************/ |
[DBO]. [FindNestedViews_v3]
|
001
002
003
004
005
006
007
008
009
010
011
012
013
014
015
016
017
018
019
020
021
022
023
024
025
026
027
028
029
030
031
032
033
034
035
036
037
038
039
040
041
042
043
044
045
046
047
048
049
050
051
052
053
054
055
056
057
058
059
060
061
062
063
064
065
066
067
068
069
070
071
072
073
074
075
076
077
078
079
080
081
082
083
084
085
086
087
088
089
090
091
092
093
094
095
096
097
098
099
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
|
use AdventureWorks2014gocreate procedure dbo.FindNestedViews_v3 (@ViewRefCount as int output) as/*******************************************************************************************************************Author: Alex FlemingCreate Date: 11-05-2017This stored procedure finds all of the views in the current database, stores them in a temp table, then passes them as parameters into the dbo.GetViewReferences stored procedure and stores the results in a new temp table, which isthen queried for all views containing one or more views in their definitions.*******************************************************************************************************************/set nocount on;begin if object_id ('[tempdb]..[#SchemaViewTemp]') is not null drop table #SchemaViewTemp; create table #SchemaViewTemp ( SVID int identity(1,1) NOT NULL primary key, SchemaViewString varchar(2000) NULL, RefCount int null ); insert into #SchemaViewTemp (SchemaViewString) select s.name + '.' + v.name as 'SchemaViewString' from sys.all_views as v inner join sys.schemas as s on v.schema_id = s.schema_id where v.object_id > 0 order by SchemaViewString; if object_id ('[tempdb]..[#ViewReferences]') is not null drop table #ViewReferences;--this table stores the output of the insert/exec statement--(can't use the same table because there is no way of updating based on an exec statement) create table #ViewReferences ( RefID int identity(1,1) not null primary key, RefCount int null ); declare @UpdateStmt varchar(500); declare @cnt as int = 0; declare @ViewString as nvarchar(255); declare NestedViewReader cursor for select SchemaViewString from #SchemaViewTemp; open NestedViewReader; fetch next from NestedViewReader into @ViewString while @@FETCH_STATUS = 0 begin insert into #ViewReferences (RefCount) exec @ViewRefCount = dbo.CountObjectReferences @QualifiedView = @ViewString, @RefCount = @ViewRefCount output; set @UpdateStmt = ( 'update #SchemaViewTemp set RefCount = ' + cast((select RefCount from #ViewReferences where RefID = @cnt + 1) as varchar(3)) + ' where SVID = 1 + ' + cast(@cnt as varchar(2)) + ';'); print @UpdateStmt;--for troubleshooting exec (@UpdateStmt); set @cnt = @cnt + 1; fetch next from NestedViewReader into @ViewString end close NestedViewReader; deallocate NestedViewReader; drop table #ViewReferences; select * from #SchemaViewTemp where RefCount > 0 order by RefCount desc;end;go/********************************Test***********************************declare @ViewRefCount as int;exec dbo.FindNestedViews_v3 @ViewRefCount = @ViewRefCount output;************************************************************************/ |
Между динамическим SQL и курсорами есть некоторые особенности T-SQL, которые являются просто неизбежными частями этого решения. Насколько я знаю, единственный способ реализовать эту идею — использовать динамический SQL для выполнения системной функции, на которую ссылаются объекты.
Кроме того, единственный способ запустить динамический SQL несколько раз — это использовать курсор (если вы не хотите попробовать что-то с расширенными хранимыми процедурами, но это выходит за рамки этой статьи). Помимо динамического SQL и курсоров у вас есть несколько важных дизайнерских решений.
После того, как у вас есть хранимая процедура, которая выполняет динамический оператор SQL, который передается в базу данных, схему и имена представлений, вы можете захотеть замедлиться и подумать о дизайне, в частности, ответив на вопрос о дизайне: «Хочу ли я сломаться? это в другую хранимую процедуру и вызывать ее, или инкапсулировать всю логику внутри одной гигантской хранимой процедуры? »
Тот факт, что я содержал динамический SQL в отдельной хранимой процедуре, а не включал его в качестве первой части одной огромной хранимой процедуры, был осознанным конструктивным решением с моей стороны. В то время я думал, что будет легче читать и поддерживать. Кроме того, я хотел убедиться, что план выполнения для динамического SQL был согласованным (одно из преимуществ хранимых процедур заключается в том, что оптимизатор может иногда генерировать разные планы выполнения). Я также обнаружил, что было легче писать и тестировать.
Решив, как сохранить квалифицированные представления, передайте их хранимой процедуре [dbo]. [CountObjectReferences], сохраните результаты курсора и затем отобразите окончательный вывод — одна из наиболее сложных частей этой проблемы. Мы можем использовать табличные переменные, временные таблицы, пользовательские таблицы или представления.
Насколько иронично было бы, если бы вы использовали вложенное представление в этой хранимой процедуре? Технически, это было бы иронично, только если база данных, в которой вы написали хранимую процедуру, не имела вложенных представлений, кроме той, что в процедуре. Это ирония!
Я выбрал временные таблицы, потому что я не так хорошо знаком с табличными переменными; Я не хочу поддерживать пользовательскую таблицу как часть этого процесса, и нет проблем с безопасностью, которые мешают мне получить прямой доступ к данным (таким образом исключая представления). Возможность добавлять индексы позже и легко изменять область действия временных таблиц между локальными и глобальными также является привлекательной характеристикой, которая повлияла на мое первоначальное решение.
С самого начала я не уточнил, хотел ли я получить более подробный набор результатов, который предоставил бы пользователю как можно больше релевантных метаданных, или включить минимальный объем данных в обмен на повышение производительности, удобства обслуживания и простоты.
Последнее оказалось моим предпочтением после размышления об исходной проблеме и размышления о том, что я хочу иметь возможность запускать эти хранимые процедуры на разовой основе, и мне нужен только простой набор результатов, чтобы найти вложенные представления. По сути, вы хотите вернуть как можно меньше информации, чтобы ответить на ваш вопрос. В нашем случае это означает возвращение всех имен представлений, которые содержат другие представления, и, в идеале, сколько уровней вложенных представлений существует между исходным представлением и таблицей.
Прежде чем двигаться дальше, я должен отметить, что я знал, что использование курсора ограничит масштабируемость такого подхода. С другой стороны, вложение представлений в базу данных не совсем масштабируемый подход к проектированию базы данных, поэтому, пожалуйста, имейте это в виду.
Ключевые моменты для дальнейшего рассмотрения
Эти хранимые процедуры были бы невозможны, если бы я не знал о [sys]. [Views] или функции ссылочных сущностей. На самом деле я изначально присоединился к [sys]. [All_objects] в [sys]. [Schemas] и [sys]. [All_columns], что оказалось хуже, чем версия, на которую есть ссылки в этой статье. Также важно указать на проблемы безопасности, связанные с привилегиями метаданных и динамическим SQL.
Поскольку политики безопасности различаются в зависимости от размера организации и ее отрасли, всякий раз, когда вы беретесь за работу, связанную с разработкой SQL Server, используйте эти факторы, чтобы ваши ожидания не выходили за рамки того же уровня, что и администраторы баз данных, с которыми вы будете работать. Дополнительную информацию о безопасности метаданных SQL Server можно найти в этой статье Kalen Delaney . На самом деле, я бы также предложил почитать больше от Делани на тему метаданных SQL Server.
Во-вторых, доступ к метаданным требует одобрения вашего администратора баз данных. Несмотря на то, что существует небольшая угроза безопасности, предоставляя любому пользователю доступ к системным метаданным, на самом деле все зависит от того, насколько ваш администратор базы данных или компания доверяет разработчикам. Если вы не работаете в строго регулируемой отрасли, вряд ли это станет для вас проблемой.
Изучение других способов использования метаданных

При использовании термина метаданные, я был специально ориентирован на системные метаданные. Я должен также указать на полезность DMV, поскольку они активно используются и полагаются на администраторов баз данных, и предложить, чтобы любой разработчик был знаком со всей вышеупомянутой информацией.
Что мне показалось самым сложным, так это быстрый поиск правильных DMV или системных метаданных — проблема, которая наверняка уменьшится, если я воспользуюсь своим собственным советом из предыдущего абзаца. На этой ноте я призываю всех, кто сталкивается с той же проблемой, использовать мой первый пример и изменять его в зависимости от того, что вы ищете (то есть изменить его, чтобы искать интересующие DMV или системные представления на основе поиска по ключевым словам).
Благодаря дополнительной практике метаданные и DMV станут для вас невероятно ценными, поскольку вы сможете максимально эффективно решать проблемы в SQL Server без помощи стороннего программного обеспечения. Более того, большая часть кода, основанного на метаданных SQL Server, будет по-прежнему функционировать в Microsoft Azure, что делает применение метаданных еще более переносимым навыком.
Принимая во внимание хаос растущих и падающих технологий, передаваемые навыки становятся все труднее идентифицировать и полагаться на них, что делает жизнь разработчиков (порой) излишне трудной. Таким образом, ценность метаданных SQL Server является свидетельством приверженности Microsoft расширению прав и возможностей пользователей, что, как и любой другой пример, является показателем того, что они создают продукты, задуманные вами, разработчиком .
| Опубликовано на Java Code Geeks с разрешения Алекса Флеминга, партнера нашей программы JCG . См. Оригинальную статью здесь: Метаданные Microsoft SQL Server для разработчиков.
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |