Если вам нужно обрабатывать результирующие наборы больших баз данных из Java, вы можете выбрать JDBC, чтобы обеспечить необходимый контроль низкого уровня. С другой стороны, если вы уже используете ORM в своем приложении, возврат к JDBC может повлечь за собой дополнительную боль. Вы потеряете такие функции, как оптимистическая блокировка, кэширование, автоматическая выборка при навигации по модели домена и т. Д. К счастью, большинство ORM, таких как Hibernate, могут помочь вам с этим. Хотя эти методы не новы, есть несколько возможностей для выбора.
Упрощенный пример; давайте предположим, что у нас есть таблица (сопоставленная с классом ‘DemoEntity’) с 100 000 записей. Каждая запись состоит из одного столбца (сопоставленного со свойством ‘свойством’ в DemoEntity), содержащего некоторые случайные буквенно-цифровые данные размером ~ 2 КБ.
JVM работает с -Xmx250m. Предположим, что максимальный объем памяти, который может быть назначен JVM в нашей системе, составляет 250 МБ. Ваша задача — прочитать все записи, находящиеся в настоящий момент в таблице, выполнить некоторую необработанную обработку и, наконец, сохранить результат. Предположим, что объекты, полученные в результате нашей массовой операции, не изменены. Для начала попробуем очевидное, выполнив запрос, чтобы просто получить все данные:
|
01
02
03
04
05
06
07
08
09
10
11
|
new TransactionTemplate(txManager).execute(new TransactionCallback<Void>() { @Override public Void doInTransaction(TransactionStatus status) { Session session = sessionFactory.getCurrentSession(); List<DemoEntity> demoEntitities = (List<DemoEntity>) session.createQuery('from DemoEntity').list(); for(DemoEntity demoEntity : demoEntitities){ //Process and write result } return null; }}); |
Через пару секунд:
|
1
|
Exception in thread 'main' java.lang.OutOfMemoryError: GC overhead limit exceeded |
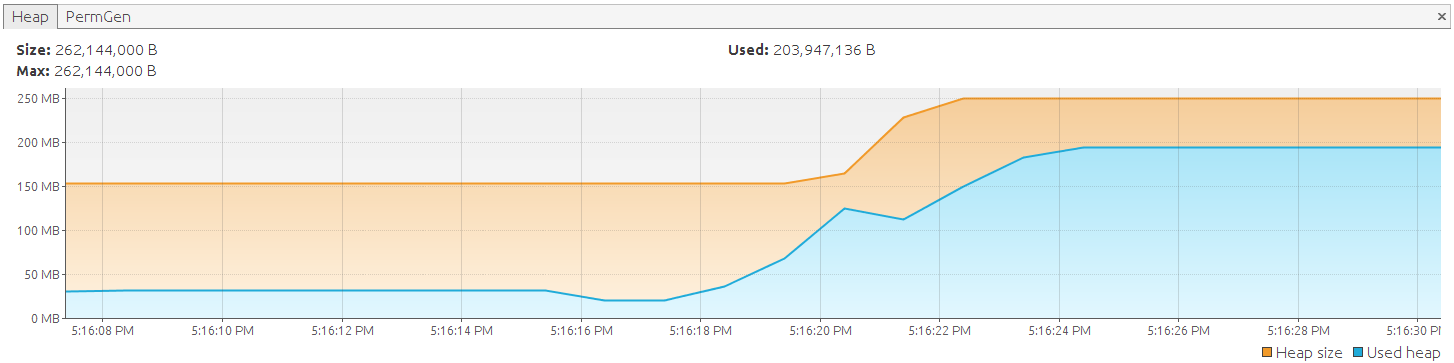
Понятно, что это не поможет. Чтобы исправить это, мы переключимся на наборы результатов прокрутки Hibernate, о которых, вероятно, большинство разработчиков знают. Приведенный выше пример инструктирует hibernate выполнить запрос, отобразить все результаты на объекты и вернуть их. При использовании прокручиваемых наборов результатов записи преобразуются в сущности по одному:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
new TransactionTemplate(txManager).execute(new TransactionCallback<Void>() { @Override public Void doInTransaction(TransactionStatus status) { Session session = sessionFactory.getCurrentSession(); ScrollableResults scrollableResults = session.createQuery('from DemoEntity').scroll(ScrollMode.FORWARD_ONLY); int count = 0; while (scrollableResults.next()) { if (++count > 0 && count % 100 == 0) { System.out.println('Fetched ' + count + ' entities'); } DemoEntity demoEntity = (DemoEntity) scrollableResults.get()[0]; //Process and write result } return null; }}); |
После запуска этого мы получаем:
|
1
2
3
4
5
|
...Fetched 49800 entitiesFetched 49900 entitiesFetched 50000 entitiesException in thread 'main' java.lang.OutOfMemoryError: GC overhead limit exceeded |
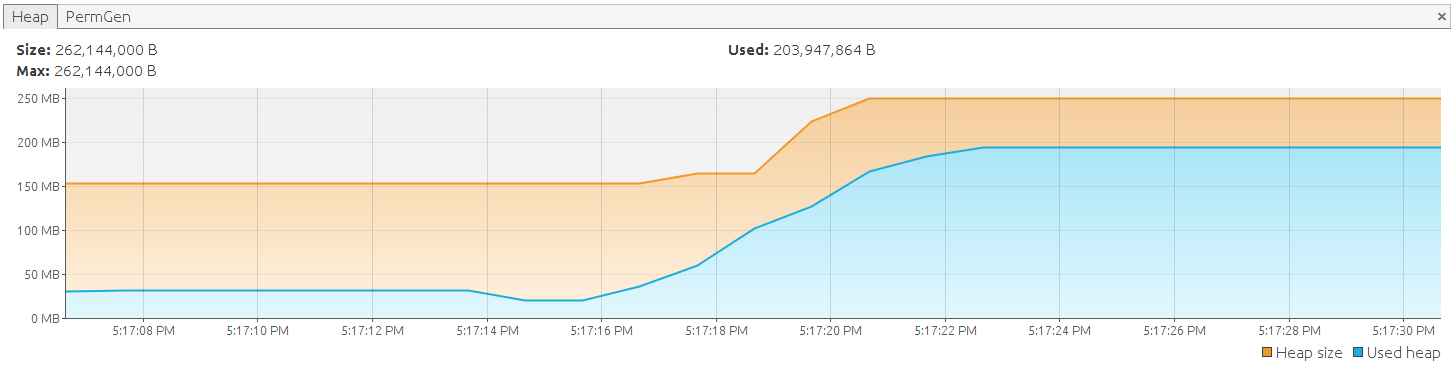
Хотя мы используем прокручиваемый набор результатов, каждый возвращаемый объект является прикрепленным объектом и становится частью контекста персистентности (или сеанса). Результат фактически такой же, как в нашем первом примере, в котором мы использовали ‘ session.createQuery (‘ from DemoEntity ‘). List () ‘. Однако с этим подходом мы не имели никакого контроля; все происходит за кулисами, и вы получаете список со всеми данными, если hibernate выполнил свою работу. использование прокручиваемого результирующего набора, с другой стороны, дает нам ловушку в процессе поиска и позволяет освободить память при необходимости. Как мы видели, он не освобождает память автоматически, вы должны указать Hibernate сделать это на самом деле. Существуют следующие варианты:
- Исключение объекта из постоянного контекста после его обработки
- Очистка всей сессии время от времени
Мы выберем первое. В приведенном выше примере в строке 13 ( // Обработка и запись результата ) мы добавим:
|
1
|
session.evict(demoEntity); |
Важный:
- Если вы хотите выполнить какое-либо изменение объекта (или объектов, с которыми у него есть ассоциации, и которые будут каскадно исключены), обязательно очистите сеанс PRIOR, исключив или очистив, иначе запросы, задержанные из-за обратной записи Hibernate, не будут отправлены база данных
- Удаление или очистка не удаляет объекты из кэша второго уровня. Если вы включили кэш второго уровня и используете его, а также хотите удалить их, используйте нужный метод sessionFactory.getCache (). EvictXxx ().
- С того момента, как вы выселите объект, он больше не будет привязан (больше не связан с сеансом). Любые изменения, внесенные в объект на этом этапе, больше не будут автоматически отражаться в базе данных. Если вы используете отложенную загрузку, доступ к любому свойству, которое не было загружено до выселения, приведет к известной исключительной ситуации org.hibernate.LazyInitializationException. Итак, в основном, убедитесь, что обработка для этой сущности выполнена (или, по крайней мере, инициализирована для дальнейших нужд), прежде чем выселить или очистить
После того, как мы снова запустим приложение, мы увидим, что оно теперь успешно выполняется:
|
1
2
3
4
|
...Fetched 99800 entitiesFetched 99900 entitiesFetched 100000 entities |
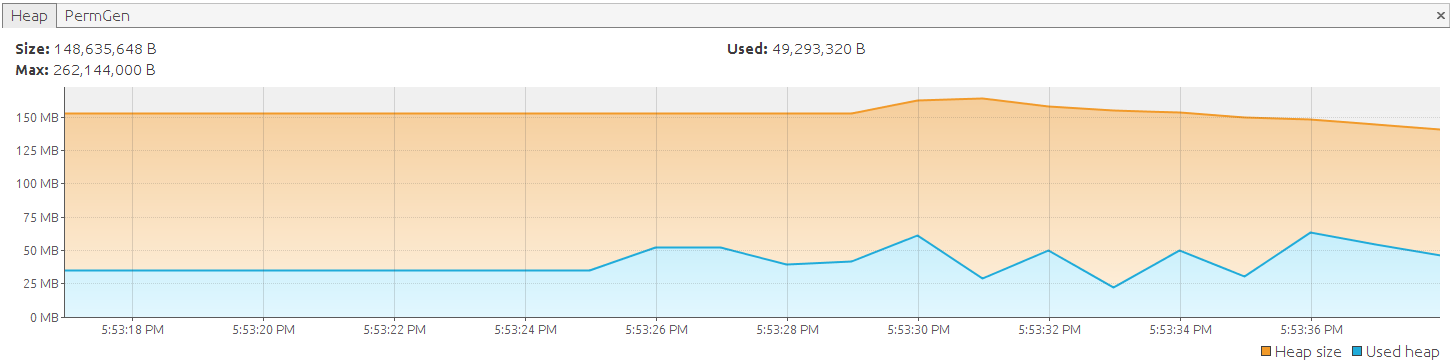
Btw; Вы также можете установить запрос только для чтения, позволяющий hibernate выполнять некоторые дополнительные оптимизации:
|
1
|
ScrollableResults scrollableResults = session.createQuery('from DemoEntity').setReadOnly(true).scroll(ScrollMode.FORWARD_ONLY); |
Это дает только очень незначительную разницу в использовании памяти, в этой конкретной тестовой настройке это позволило нам прочитать дополнительно около 300 объектов с заданным объемом памяти. Лично я бы не использовал эту функцию только для оптимизации памяти, но только если она подходит для вашей общей стратегии неизменности. В hibernate у вас есть различные варианты сделать объекты доступными только для чтения: для самой сущности, для всего сеанса только для чтения и так далее. Установка только для чтения false для запроса по отдельности, вероятно, является наименее предпочтительным подходом. (Например, объекты, загруженные в сеанс ранее, останутся неизменными, возможно, изменяемыми. Ленивые ассоциации будут загружены изменяемыми, даже если корневые объекты, возвращаемые запросом, доступны только для чтения).
Хорошо, мы смогли обработать наши 100.000 записей, жизнь прекрасна. Но, как оказалось, в Hibernate есть еще один вариант для массовых операций: сеанс без сохранения состояния. Вы можете получить прокручиваемый набор результатов из сеанса без сохранения состояния так же, как из обычного сеанса. Сеанс без сохранения состояния находится непосредственно над JDBC. Hibernate будет работать почти в режиме «все функции отключены». Это означает, что нет постоянного контекста, нет кэширования 2-го уровня, нет грязного обнаружения, нет отложенной загрузки, практически ничего. От Javadoc:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
/** * A command-oriented API for performing bulk operations against a database. * A stateless session does not implement a first-level cache nor interact with any * second-level cache, nor does it implement transactional write-behind or automatic * dirty checking, nor do operations cascade to associated instances. Collections are * ignored by a stateless session. Operations performed via a stateless session bypass * Hibernate's event model and interceptors. Stateless sessions are vulnerable to data * aliasing effects, due to the lack of a first-level cache. For certain kinds of * transactions, a stateless session may perform slightly faster than a stateful session. * * @author Gavin King */ |
Единственное, что он делает — это преобразовывает записи в объекты. Это может быть привлекательной альтернативой, потому что это поможет вам избавиться от этого ручного выселения / сброса:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
new TransactionTemplate(txManager).execute(new TransactionCallback<Void>() { @Override public Void doInTransaction(TransactionStatus status) { sessionFactory.getCurrentSession().doWork(new Work() { @Override public void execute(Connection connection) throws SQLException { StatelessSession statelessSession = sessionFactory.openStatelessSession(connection); try { ScrollableResults scrollableResults = statelessSession.createQuery('from DemoEntity').scroll(ScrollMode.FORWARD_ONLY); int count = 0; while (scrollableResults.next()) { if (++count > 0 && count % 100 == 0) { System.out.println('Fetched ' + count + ' entities'); } DemoEntity demoEntity = (DemoEntity) scrollableResults.get()[0]; //Process and write result } } finally { statelessSession.close(); } } }); return null; }}); |
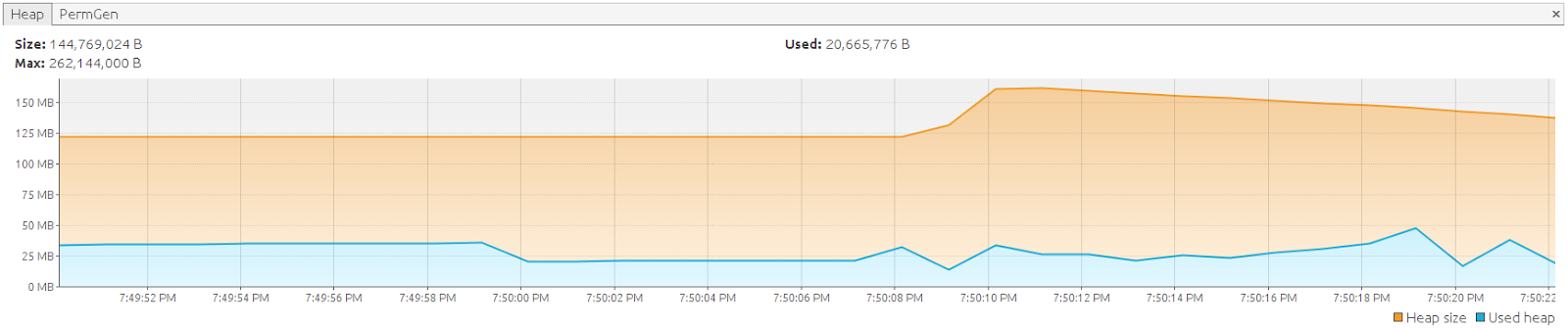
Помимо того, что сеанс без сохранения состояния имеет наиболее оптимальное использование памяти, использование его имеет некоторые побочные эффекты. Возможно, вы заметили, что мы открываем сеанс без сохранения состояния и закрываем его явно: нет ни sessionFactory.getCurrentStatelessSession (), ни (на момент написания) никакой интеграции Spring для управления сеансом без состояния. Открытие сеанса без состояния выделяет новую Java. sql.Connection по умолчанию (если вы используете openStatelessSession () ) для выполнения своей работы и, следовательно, косвенно порождает вторую транзакцию. Вы можете смягчить эти побочные эффекты, используя рабочий API Hibernate, как в примере, который предоставляет текущее соединение и передает его openStatelessSession (соединение соединения). Закрытие сеанса в finally не влияет на физическое соединение, поскольку оно перехватывается инфраструктурой Spring: закрывается только дескриптор логического соединения, и при открытии сеанса без состояния был создан новый дескриптор логического соединения.
Также обратите внимание, что вам приходится самостоятельно закрывать сеанс без сохранения состояния и что приведенный выше пример подходит только для операций только для чтения. С того момента, как вы собираетесь изменить сессию без сохранения состояния, есть еще несколько предостережений. Как было сказано ранее, hibernate работает в режиме «все функции отключены» и, как прямое следствие, объекты возвращаются в отключенном состоянии. Для каждой изменяемой сущности вам придется явно вызывать: statelessSession.update (entity) . Сначала я попробовал это для изменения сущности:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
new TransactionTemplate(txManager).execute(new TransactionCallback<Void>() { @Override public Void doInTransaction(TransactionStatus status) { sessionFactory.getCurrentSession().doWork(new Work() { @Override public void execute(Connection connection) throws SQLException { StatelessSession statelessSession = sessionFactory.openStatelessSession(connection); try { DemoEntity demoEntity = (DemoEntity) statelessSession.createQuery('from DemoEntity where id = 1').uniqueResult(); demoEntity.setProperty('test'); statelessSession.update(demoEntity); } finally { statelessSession.close(); } } }); return null; }}); |
Идея в том, что мы открываем сеанс без сохранения состояния с существующей базой данных Connection. Поскольку Javadoc StatelessSession указывает, что не происходит никакой обратной записи, я был убежден, что каждый оператор, выполняемый сеансом без состояния, будет отправляться непосредственно в базу данных. В конце концов, когда транзакция (запущенная TransactionTemplate) будет зафиксирована, результаты станут видимыми в базе данных. Однако hibernate делает операторы BATCH, используя сеанс без сохранения состояния. Я не уверен на 100%, в чем разница между пакетированием и записью, но результат тот же, что противоречит словарю с javadoc, поскольку операторы ставятся в очередь и сбрасываются позже. Итак, если вы не сделаете ничего особенного, операторы, которые являются пакетными, не будут сброшены, и это то, что произошло в моем случае: ‘statelessSession.update (demoEntity);’ был порцией и никогда не покраснел. Один из способов принудительной очистки — использовать API транзакций гибернации:
|
1
2
3
4
5
|
StatelessSession statelessSession = sessionFactory.openStatelessSession();statelessSession.beginTransaction();...statelessSession.getTransaction().commit();... |
Хотя это работает, вы, вероятно, не хотите начинать контролировать свои транзакции программно только потому, что используете сеанс без сохранения состояния. Кроме того, выполняя это, мы снова запускаем нашу работу сеанса без сохранения состояния во втором сценарии транзакции, так как мы не передали наше Соединение, и, таким образом, будет получено новое соединение с базой данных. Причина, по которой мы не можем передать внешнее соединение, заключается в том, что если мы зафиксируем внутреннюю транзакцию («транзакция сеанса без сохранения состояния»), и она будет использовать то же соединение, что и внешняя транзакция (запущенная TransactionTemplate), она разорвет внешнюю транзакцию. атомарность транзакции, поскольку операторы из внешней транзакции, отправленные в базу данных, будут зафиксированы вместе с внутренней транзакцией. Таким образом, отказ от прохождения соединений означает открытие нового соединения и, следовательно, создание второй транзакции. Лучшей альтернативой было бы просто запустить Hibernate для сброса сеанса без сохранения состояния. Тем не менее, statelessSession не имеет метода flush для ручного запуска сброса. Решение здесь заключается в том, чтобы немного зависеть от внутреннего API Hibernate. Это решение делает ручную обработку транзакций и вторую транзакцию устаревшей: все операторы становятся частью нашей (единственной) внешней транзакции:
|
1
2
3
4
5
6
7
8
9
|
StatelessSession statelessSession = sessionFactory.openStatelessSession(connection); try { DemoEntity demoEntity = (DemoEntity) statelessSession.createQuery('from DemoEntity where id = 1').uniqueResult(); demoEntity.setProperty('test'); statelessSession.update(demoEntity); ((TransactionContext) statelessSession).managedFlush(); } finally { statelessSession.close();} |
К счастью, есть еще лучшее решение, недавно опубликованное в Spring jira: https://jira.springsource.org/browse/SPR-2495 Это еще не часть Spring, но реализация фабричного компонента довольно проста: StatelessSessionFactoryBean. Java при использовании этого вы можете просто внедрить StatelessSession:
|
1
2
|
@Autowiredprivate StatelessSession statelessSession; |
Он внедрит прокси сеанса без сохранения состояния, который эквивалентен тому, как работает обычный «текущий» сеанс (с небольшим отличием в том, что вы внедряете SessionFactory и должны каждый раз получать currentSession). Когда прокси вызывается, он ищет сеанс без сохранения состояния, связанный с запущенной транзакцией. Если ничего не существует, он создаст соединение с тем же соединением, что и обычный сеанс (как мы это делали в примере), и зарегистрирует пользовательскую синхронизацию транзакций для сеанса без сохранения состояния. Когда транзакция зафиксирована, сеанс без сохранения состояния сбрасывается благодаря синхронизации и, наконец, закрывается. Используя это, вы можете внедрить сеанс без сохранения состояния напрямую и использовать его в качестве текущего сеанса (или так же, как вы бы добавили JPA PeristentContext в этом отношении). Это освобождает вас от необходимости открывать и закрывать сеанс без сохранения состояния, и вам приходится иметь дело с тем или иным способом, чтобы сделать его сброшенным. Реализация нацелена на JPA, но часть JPA ограничена получением физического соединения в receivePhysicalConnection (). Вы можете легко опустить EntityManagerFactory и получить физическое соединение непосредственно из сеанса Hibernate.
Очень осторожный вывод: ясно, что наилучший подход будет зависеть от вашей ситуации. Если вы используете обычный сеанс, вам придется иметь дело с выселением самостоятельно при чтении или сохранении сущностей. Помимо того, что вы должны сделать это вручную, это может также повлиять на дальнейшее использование сеанса, если у вас смешанная транзакция; Вы оба выполняете «массовые» и «обычные» операции в одной транзакции. Если вы продолжите обычные операции, у вас будут отключенные сущности в вашем сеансе, что может привести к неожиданным результатам (так как «грязное» обнаружение больше не будет работать и т. Д.). С другой стороны, у вас все еще будут основные преимущества гибернации (если объект не исключен), такие как ленивая загрузка, кэширование, грязное обнаружение и тому подобное. Использование сеанса без сохранения состояния во время написания требует некоторого дополнительного внимания к управлению им (открытие, закрытие и сброс), что также может быть подвержено ошибкам. В предположении, что вы можете продолжить работу с предлагаемым фабричным компонентом, у вас очень чистый сеанс кости, который отделен от вашего обычного сеанса, но все еще участвует в той же транзакции. Благодаря этому у вас есть мощный инструмент для выполнения массовых операций без необходимости думать об управлении памятью. Недостатком является то, что у вас нет других доступных функций гибернации.
Ссылка: массовая загрузка с помощью Hibernate от нашего партнера по JCG