В этом блоге обсуждается сравнительный анализ производительности веб-службы под нагрузкой. Чтобы узнать больше о теории производительности веб-сервисов, прочитайте Закон Литтла, Масштабируемость и Отказоустойчивость .
Сравнительный анализ веб-службы с блокировкой и асинхронным вводом-выводом
То, как веб-приложение (или веб-служба) ведет себя под нагрузкой, перед лицом различных сбоев и при их сочетании, является наиболее важным свойством нашего кода — конечно, после его корректности. Поскольку веб-службы обычно выполняют очень распространенные операции — опрашивают кеши, базы данных или другие веб-службы для сбора данных, собирают их и возвращают вызывающей стороне — такое поведение в основном определяется выбором веб-инфраструктуры / сервера и его архитектуры. В предыдущем сообщении в блоге мы обсудили закон Литтла и применили его для анализа теоретических ограничений различных архитектурных подходов, применяемых веб-серверами. Этот пост, который дополняет этот, вновь затрагивает ту же тему, только на этот раз мы измерим эффективность на практике.
Веб-фреймворки (и я использую этот термин для обозначения любой программной среды, которая отвечает на HTTP-запросы путем запуска пользовательского кода, называется ли она фреймворком, сервером приложений, веб-контейнером или просто частью стандартных библиотек языка), выберите один из следующих вариантов: две архитектуры. Первый — это назначение одного потока ОС, который будет выполнять весь наш код до тех пор, пока запрос не будет завершен. Это подход, принятый стандартными сервлетами Java, Ruby , PHP и другими средами. Некоторые из этих серверов запускают весь пользовательский код в одном потоке, поэтому они могут обрабатывать только один запрос за раз; другие запускают параллельные запросы в разных параллельных потоках. Этот подход, называемый поток-на-запрос, требует очень простого кода.
Другой подход заключается в использовании асинхронного ввода-вывода и планировании кода обработки запросов для многих одновременных запросов — настолько умно, насколько это возможно — в один или несколько потоков ОС (предположительно, с использованием меньшего количества потоков ОС, чем количество одновременных запросов). Это подход, используемый Node.js , асинхронными сервлетами Java и средами JVM, такими как Vert.x и Play . Сила этого подхода, предположительно (это именно то, что мы будем измерять), в большей масштабируемости и устойчивости (перед лицом скачков использования, сбоев и т. Д.), Но написание кода для таких асинхронных серверов сложнее, чем для потоковых. по запросу. Насколько сложнее код, зависит от использования различных техник «обратного вызова-смягчения ада», таких как обещания и / или другие подходы функционального программирования, обычно с использованием монад.
Другие среды стремятся объединить лучшее из обоих подходов. Под прикрытием они используют асинхронный ввод-вывод, но вместо того, чтобы программисты использовали обратные вызовы или монады, они предоставляют программисту волокна (так называемые легкие потоки или потоки пользовательского уровня), которые потребляют очень мало оперативной памяти и имеют незначительные накладные расходы на блокировку. Таким образом, эти среды достигают тех же преимуществ масштабируемости / производительности / надежности асинхронного подхода, сохраняя при этом простоту и привычность синхронного (блокирующего) кода. К таким средам относятся Erlang , Go и Quasar (которые добавляют волокна в JVM).
Бенчмарк
- Полный тестовый проект можно найти здесь .
Чтобы проверить относительную производительность двух подходов, мы будем использовать простой веб-сервис, написанный на Java с использованием API JAX-RS. Тестовый код будет имитировать общую современную архитектуру микросервисов , но результаты никоим образом не ограничиваются использованием микросервисов. В архитектуре микросервиса клиент (веб-браузер, мобильный телефон, телевизионная приставка) отправляет запрос в одну конечную точку HTTP. Этот запрос затем разбивается сервером на несколько (часто множество) других подзапросов, которые отправляются различным внутренним HTTP-сервисам, каждый из которых отвечает за предоставление одного типа данных или за выполнение одного типа операции (например, один микросервис может отвечать за возврат профиля пользователя, а другой — их круг друзей).
Мы будем сравнивать один основной сервис, который выдает вызовы одному или двум другим микросервисам, и исследуем поведение основного сервиса, когда микросервисы работают нормально и когда они выходят из строя.
Микросервисы будут симулироваться этим простым сервисом, установленным по адресу http://ourserver:8080/internal/foo :
|
01
02
03
04
05
06
07
08
09
10
11
12
|
@Singleton@Path("/foo")public class SimulatedMicroservice { @GET @Produces("text/plain") public String get(@QueryParam("sleep") Integer sleep) throws IOException, SuspendExecution, InterruptedException { if (sleep == null || sleep == 0) sleep = 10; Strand.sleep(sleep); // <-- Why we use Strand.sleep rather than Thread.sleep will be made clear later return "slept for " + sleep + ": " + new Date().getTime(); }} |
Все, что он делает, — это принимает параметр запроса sleep который определяет количество времени (в миллисекундах), в течение которого служба должна находиться в спящем режиме до завершения (с минимум 10 мс). Это может имитировать удаленный микросервис, выполнение которого может занять много или мало времени.
Для имитации нагрузки мы использовали Photon , очень простой инструмент генерации нагрузки, который использует волокна Quasar для выдачи очень большого количества одновременных запросов и измерения их задержек способом, который относительно менее склонен к скоординированному пропуску : каждый запрос отправляется вновь порожденным волокна, а волокна, в свою очередь, порождаются с постоянной скоростью.
Мы протестировали сервис на трех различных встроенных веб-серверах Java: Jetty , Tomcat (встроенный) и Undertow (веб-сервер, на котором работает сервер приложений JBoss Wildfly). Теперь, поскольку все три сервера соответствуют стандартам Java, мы повторно используем один и тот же сервисный код для всех трех. К сожалению, нет стандартного API для программной настройки веб-сервера, поэтому большая часть кода в тестовом проекте просто абстрагирует три API-интерфейса конфигурации трех серверов (в классах JettyServer , TomcatServer и UndertowServer ). Класс Main просто анализирует аргументы командной строки, настраивает встроенный сервер и устанавливает Jersey в качестве контейнера JAX-RS.
Мы запустили генератор нагрузки и сервер на каждом экземпляре EC3 c3.8xlarge, работающем под управлением Ubunto Server 14.04 64 bit и JDK 8. Если вы хотите сами поиграть с тестами, следуйте приведенным здесь инструкциям.
Представленные здесь результаты получены при выполнении наших тестов на Jetty. Tomcat реагировал аналогично простому коду блокировки, но намного хуже, чем Jetty, когда использовались волокна (это требует дальнейшего изучения). Undertow вел себя противоположным образом: при использовании волокон он работал аналогично Jetty, но быстро падал, когда код блокировки потоков сталкивался с высокой нагрузкой.
Конфигурирование ОС
Поскольку мы будем тестировать наш сервис под большой нагрузкой, для его поддержки на уровне операционной системы потребуется некоторая конфигурация.
Наш /etc/sysctl.conf будет содержать
|
1
2
3
4
5
6
|
net.ipv4.tcp_tw_recycle = 1net.ipv4.tcp_tw_reuse = 1net.ipv4.tcp_fin_timeout = 1net.ipv4.tcp_timestamps = 1net.ipv4.tcp_syncookies = 0net.ipv4.ip_local_port_range = 1024 65535 |
и будет загружен таким образом:
|
1
|
sudo sysctl -p /etc/sysctl.conf |
/etc/security/limits.conf будет содержать
|
1
2
|
* hard nofile 200000* soft nofile 200000 |
Настройка сборки мусора
Большинство сборщиков мусора Java работают в соответствии с гипотезой поколений, которая предполагает, что у большинства объектов будет очень короткая продолжительность жизни. Однако, когда мы начинаем тестировать систему с (имитируемой) неисправной микросервисной службой, она генерирует открытые соединения, которые длятся много секунд и только потом умирают. Этот тип «средней продолжительности жизни» (то есть не короткий, но и не слишком длинный) является наихудшим видом мусора. Увидев, что GC по умолчанию приводит к недопустимым паузам и не желая тратить слишком много времени на тонкую настройку GC, мы решили попробовать новый (ish) G1 сборщик мусора в HotSpot. Все, что мы должны были сделать, это выбрать максимальную цель времени паузы (мы выбрали 200 мс). G1 вел себя потрясающе (1), поэтому мы больше не тратили время на настройку коллектора.
- Вероятно, потому, что объекты были распределены по группам, которые все умерли в одном возрасте. Эта модель, вероятно, играет в сильные стороны G1.
Бенчмаркинг синхронного подхода
Это код нашего тестируемого сервиса, смонтированный в /api/service , начиная с синхронного подхода. (полный класс, который также включает в себя конфигурацию HTTP-клиента, можно найти здесь ):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
@Singleton@Path("/service")public class Service extends HttpServlet { private final CloseableHttpClient httpClient; private static final BasicResponseHandler basicResponseHandler = new BasicResponseHandler(); public Service() { httpClient = HttpClientBuilder.create() ... // configure .build(); } @GET @Produces("text/plain") public String get(@QueryParam("sleep") int sleep) throws IOException { // simulate a call to a service that always completes in 10 ms - service A String res1 = httpClient.execute(new HttpGet(Main.SERVICE_URL + 10), basicResponseHandler); // simulate a call to a service that might fail and cause a delay - service B String res2 = sleep > 0 ? httpClient.execute(new HttpGet(Main.SERVICE_URL + sleep), basicResponseHandler) : "skipped"; return "call response res1: " + res1 + " res2: " + res2; }} |
Затем наш сервис вызывает один или два других микросервиса, которые мы можем назвать A и B (оба они, конечно, моделируются нашим SimulatedMicroservice ). В то время как служба A всегда занимает 10 мс, служба B может быть смоделирована для отображения различных задержек.
Предположим, что служба B работает нормально и возвращает свой результат через 10 мс работы. Вот как наш сервис со временем отвечает на 1000 запросов в секунду (сервер использует пул из 2000 потоков). Красная линия — это задержка для запросов, требующих обоих микросервисов, а зеленая линия — это задержка для тех запросов, которые вызывают только вызовы к микросервису A:
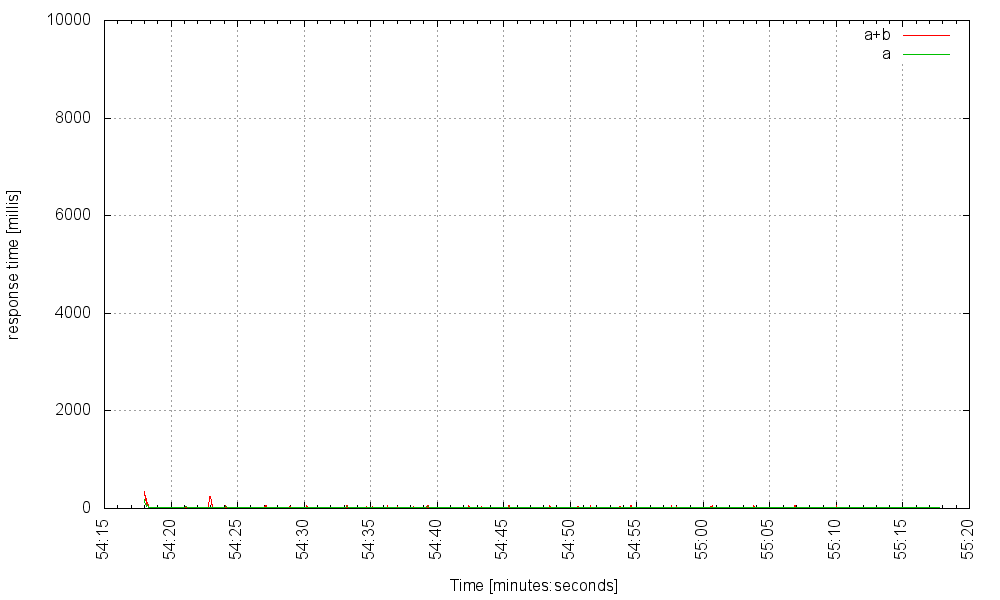
Мы можем даже поднять частоту до 3000 Гц:
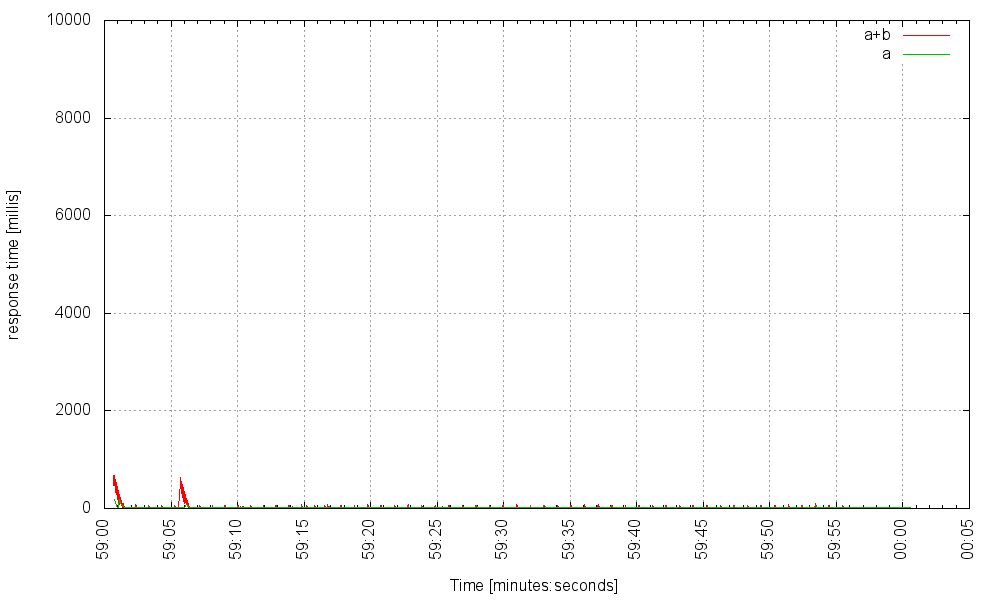
За пределами 3000 Гц сервер испытывает серьезные трудности.
Теперь давайте предположим, что в какой-то момент служба B испытывает сбой, который заставляет B отвечать со значительно увеличенной задержкой; скажем, 5000 мс Если каждую секунду мы обращаемся к серверу с 300 запросами, которые запускают службы A и B, и дополнительными 10 запросами, которые запускают только A (это контрольная группа), служба работает как следует: эти запросы, инициирующие B, имеют увеличенную задержку, но те, кто обходит его, остаются без изменений.
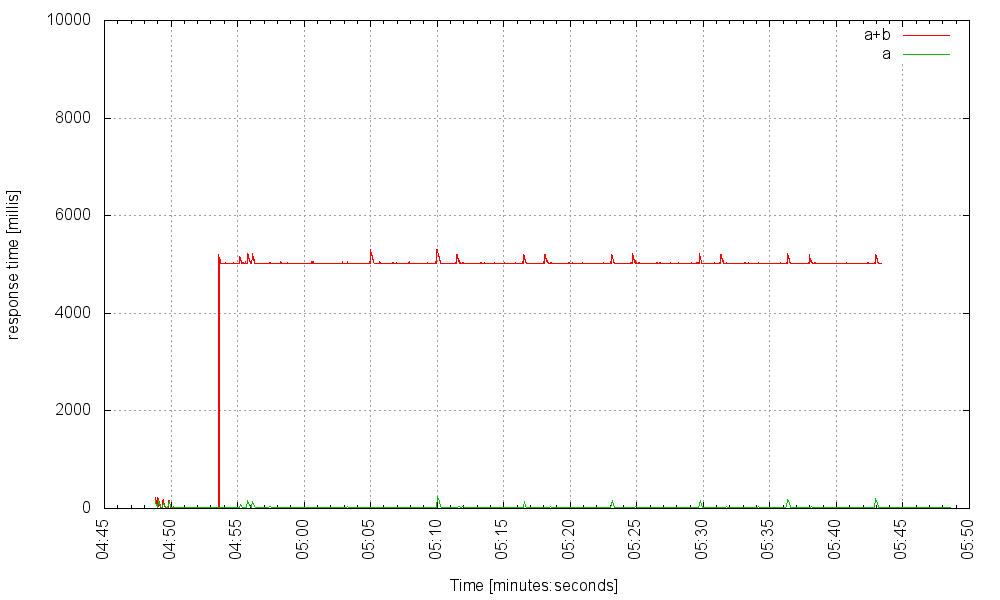
Но если мы затем увеличим частоту запросов до 400 Гц, произойдет что-то плохое:
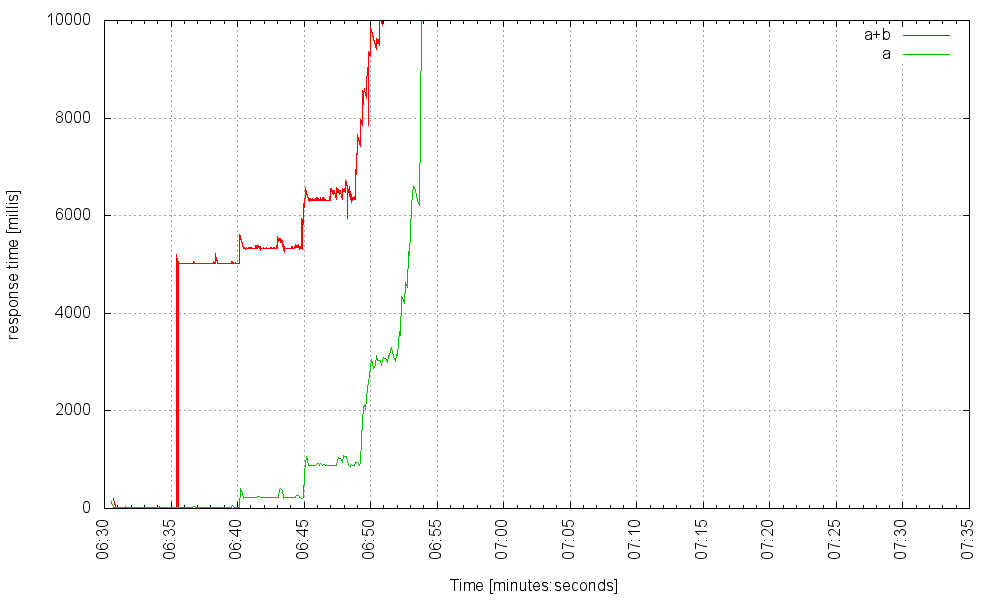
Что тут происходит? Когда происходит сбой службы B, те запросы к основной службе, которые запускают ее в течение длительного времени, блокируют каждый из них, удерживая поток, который не может быть возвращен в пул потоков сервера, пока запрос не завершится. Потоки начинают накапливаться до тех пор, пока не исчерпают пул потоков сервера, и в этот момент ни один запрос — даже тот, который не пытается использовать отказавший сервис — не может пройти, и сервер по существу выходит из строя. Это известно как каскадный сбой . Один сбойный микросервис может разрушить все приложение. Что мы можем сделать, чтобы смягчить такие неудачи?
Мы можем попытаться увеличить максимальный размер пула потоков, но до (довольно низкого) предела. Потоки ОС накладывают на систему два типа нагрузки: во-первых, их стеки потребляют относительно большой объем оперативной памяти; адаптивным приложениям гораздо лучше использовать эту оперативную память для хранения кэша данных. Во-вторых, планирование многих потоков на относительно небольшом количестве процессорных ядер добавляет немаловажные накладные расходы. Если сервер выполняет очень мало вычислений, интенсивно использующих процессор (как это часто бывает; сервер обычно просто собирает данные из других источников), затраты на планирование могут стать существенными.
Когда мы увеличиваем размер пула потоков до 5000, наш сервер работает лучше. На частоте 500 Гц он все еще функционирует хорошо:
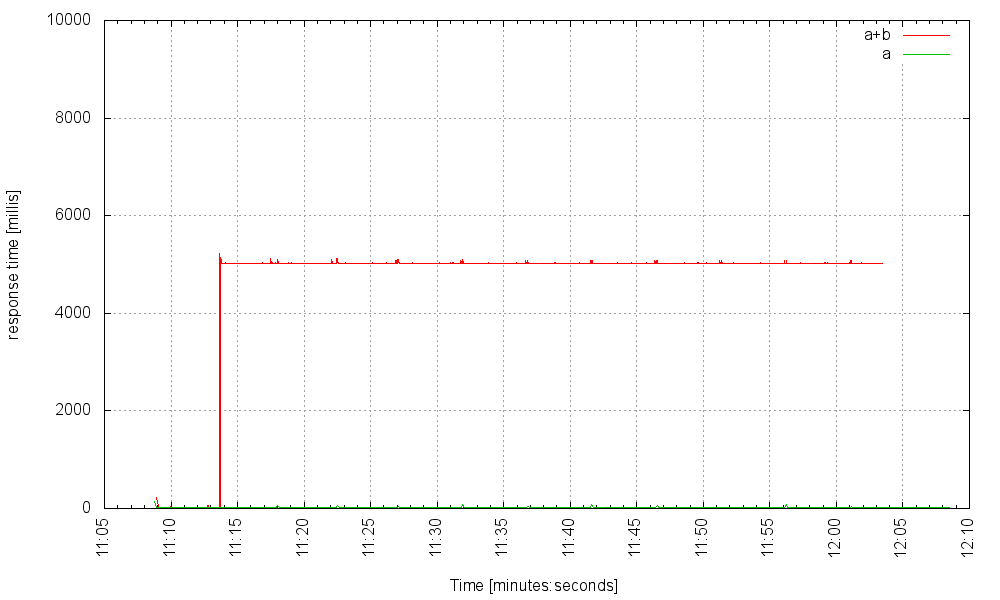
На частоте 700 Гц она колеблется на грани:
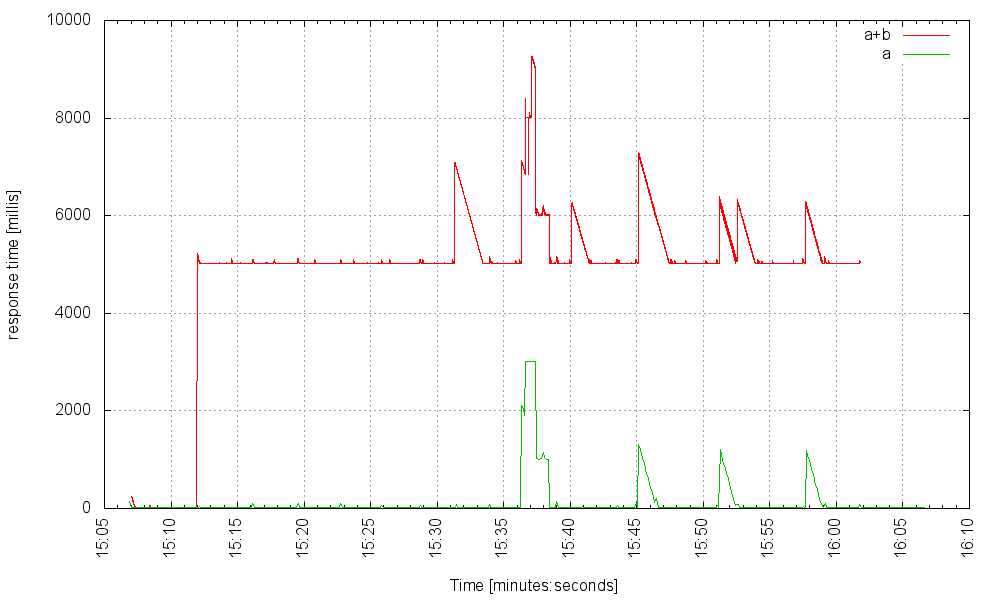
… и падает, когда мы увеличиваем скорость. Но как только мы увеличим размер пула потоков до 6000, дополнительные потоки не помогут. Вот сервер с 6000 потоков на 1100 Гц:
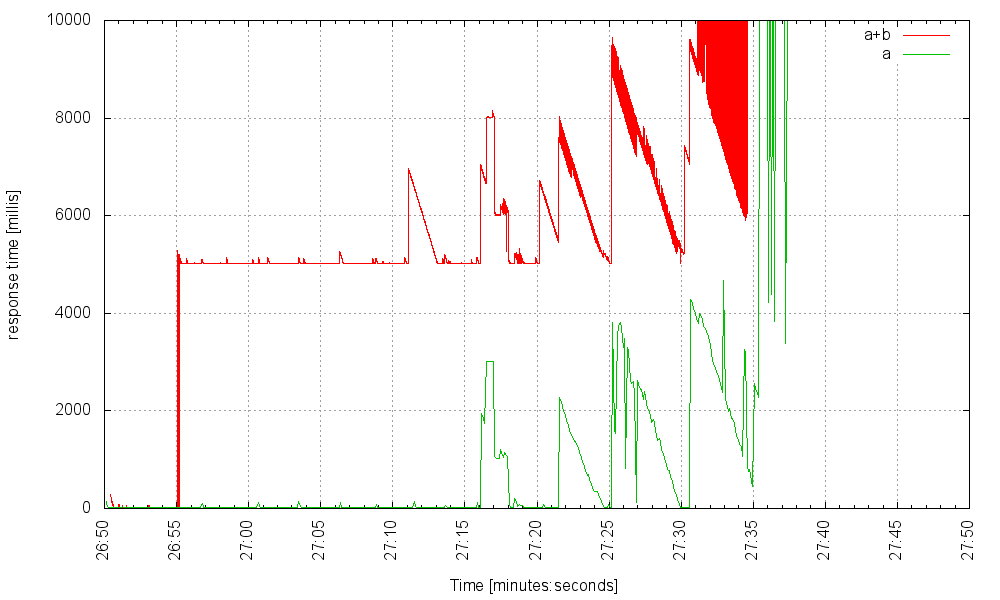
И вот он с 7000 потоков, обрабатывающих ту же нагрузку:
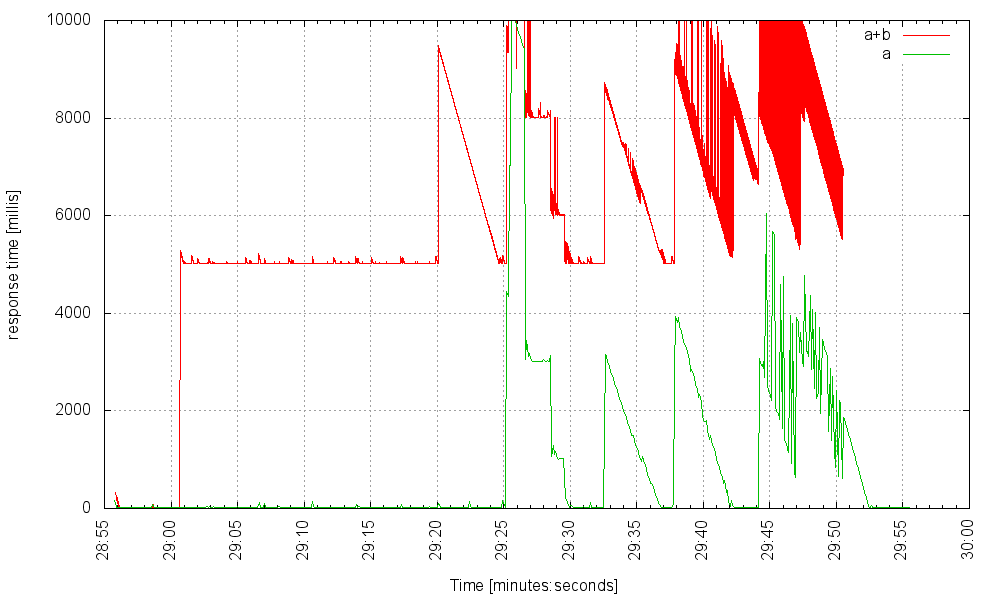
Мы можем попытаться установить тайм-аут на вызовы микросервиса. Тайм-ауты всегда хорошая идея, но какое значение тайм-аута выбрать? Слишком низко, и мы могли бы сделать наше приложение менее доступным, чем могло бы быть; слишком высоко, и мы действительно не решили проблему.
Мы также можем установить автоматический выключатель, такой как Hystrix от Netfilx, который попытается быстро заметить проблему и изолировать неисправный микросервис. Автоматические выключатели, такие как тайм-ауты, всегда хорошая идея, но если мы можем значительно увеличить мощность нашей цепи, мы, вероятно, должны это сделать (и все же установить автоматический выключатель, просто чтобы быть в безопасности).
Теперь посмотрим, как работает асинхронный подход.
Бенчмаркинг асинхронного подхода
Асинхронный подход не назначает поток для каждого соединения, но использует небольшое количество потоков для обработки большого количества событий ввода-вывода. Стандарт Servlet теперь использует асинхронный API в дополнение к блокирующему API, но поскольку никто не любит обратные вызовы (особенно в многопоточной среде с общим изменяемым состоянием), очень немногие используют его. Платформа Play также имеет асинхронный API, и для облегчения некоторых проблем, неизменно связанных с асинхронным кодом, Play заменяет простые обратные вызовы на монадические композиции функционального программирования. API-интерфейс Play не только нестандартен, но и очень чувствителен для разработчиков Java. Это также не помогает уменьшить проблемы, связанные с выполнением асинхронного кода в среде, которая не защищает от условий гонки. Короче говоря, асинхронный код — боль в заднице.
Но мы все еще можем протестировать поведение этого подхода, оставляя наш код красивым, простым и блокирующим, используя волокна. Мы все еще будем использовать асинхронный ввод-вывод, но уродство будет скрыто от нас.
Сравнительный анализ асинхронного волоконного подхода
Comsat — это проект с открытым исходным кодом, объединяющий стандартные или популярные веб-интерфейсы API с волокнами Quasar. Вот наш сервис, теперь использующий Comsat (полный класс здесь ):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
@Singleton@Path("/service")public class Service extends HttpServlet { private final CloseableHttpClient httpClient; private static final BasicResponseHandler basicResponseHandler = new BasicResponseHandler(); public Service() { httpClient = FiberHttpClientBuilder.create() // <---------- FIBER ... .build(); } @GET @Produces("text/plain") @Suspendable // <------------- FIBER public String get(@QueryParam("sleep") int sleep) throws IOException { // simulate a call to a service that always completes in 10 ms - service A String res1 = httpClient.execute(new HttpGet(Main.SERVICE_URL + 10), basicResponseHandler); // simulate a call to a service that might fail and cause a delay - service B String res2 = sleep > 0 ? httpClient.execute(new HttpGet(Main.SERVICE_URL + sleep), basicResponseHandler) : "skipped"; return "call response res1: " + res1 + " res2: " + res2; }} |
Код идентичен нашему сервису блокировки потоков, за исключением пары строк, отмеченных стрелками, и одной строки в классе Main .
Когда B работает правильно, все хорошо (когда сервер обслуживает эти первые несколько запросов, вы увидите несколько предупреждений, выведенных на консоль, о том, что волокна занимают слишком много процессорного времени. Это нормально. Это просто код инициализации, который выполняется):
Без лишних слов, вот наш сервис по волокнам (с использованием 40 потоков ОС, что является минимальным размером пула потоков Jetty) на частоте 3000 Гц:
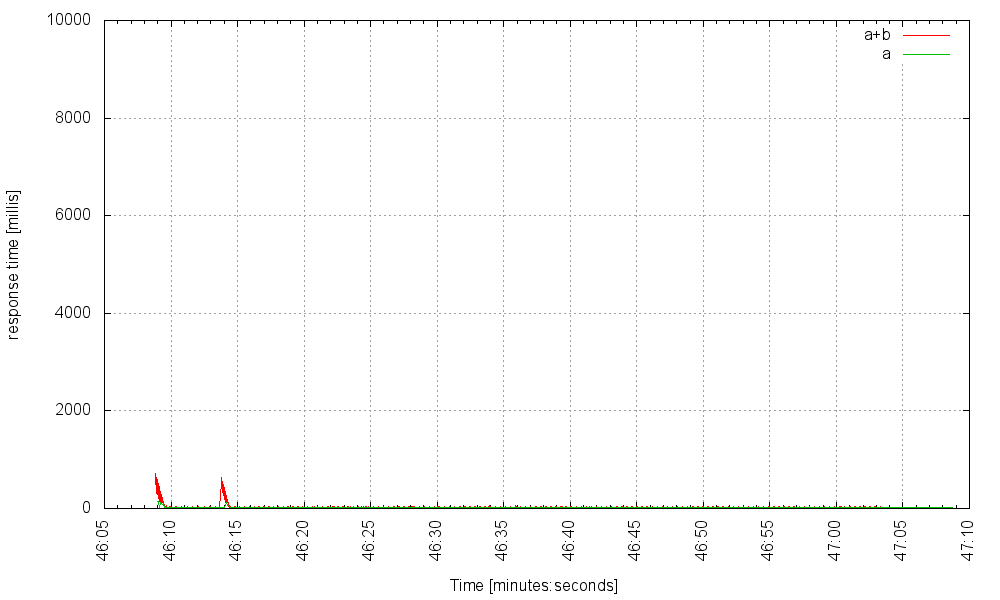
при 5000Гц:
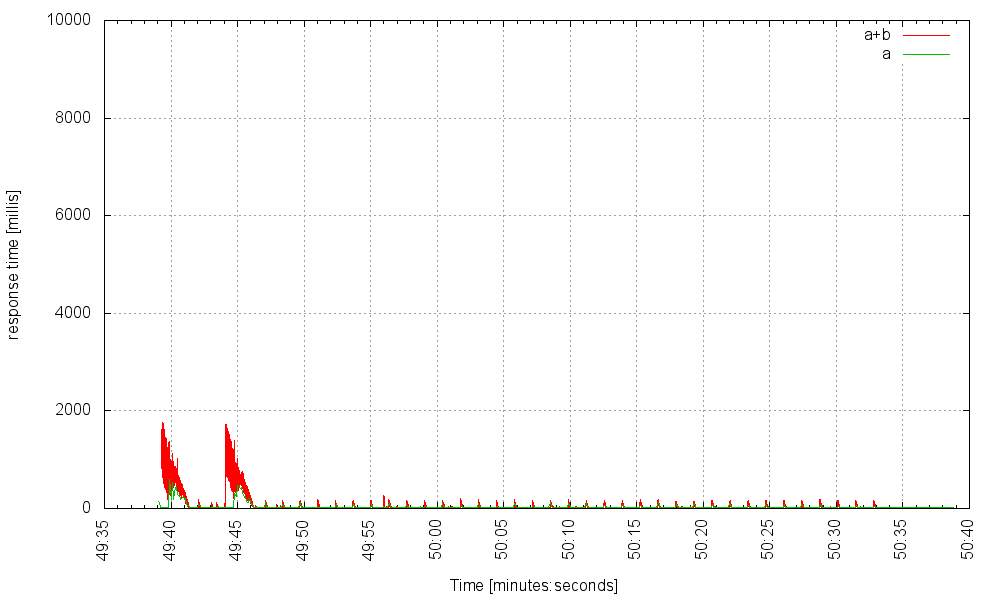
на 6000 Гц требуется некоторое время, чтобы полностью прогреться, но затем сходится:
Теперь давайте пнем наш проблемный микросервис, наш дорогой сервис B, чтобы он имел задержку в 5 секунд. Вот наш сервер на 1000 Гц:
и при 2000 Гц:
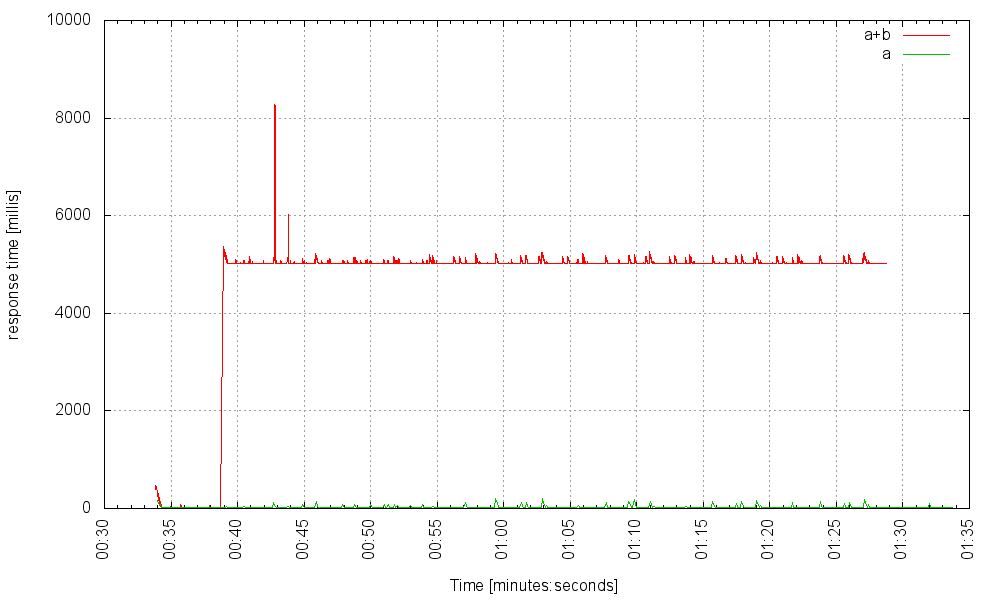
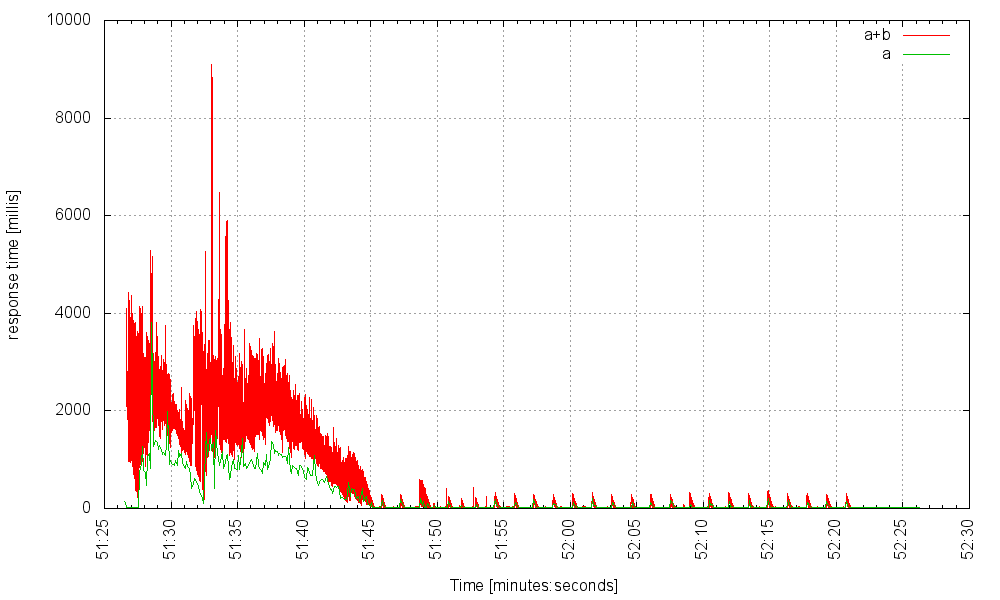
Все еще плавный ход, за исключением очень редкого всплеска при ответе на запрос с использованием неисправного сервиса B, но те, кто бьют по одному, ничего не испытывают. На частоте 4000 Гц начинает проявляться заметный, но не катастрофический джиттер:
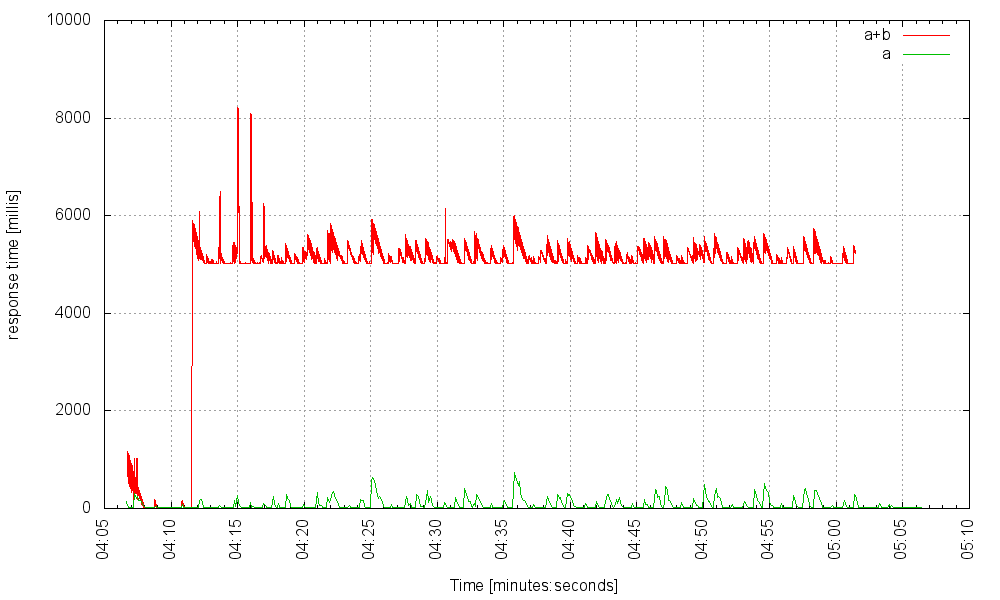
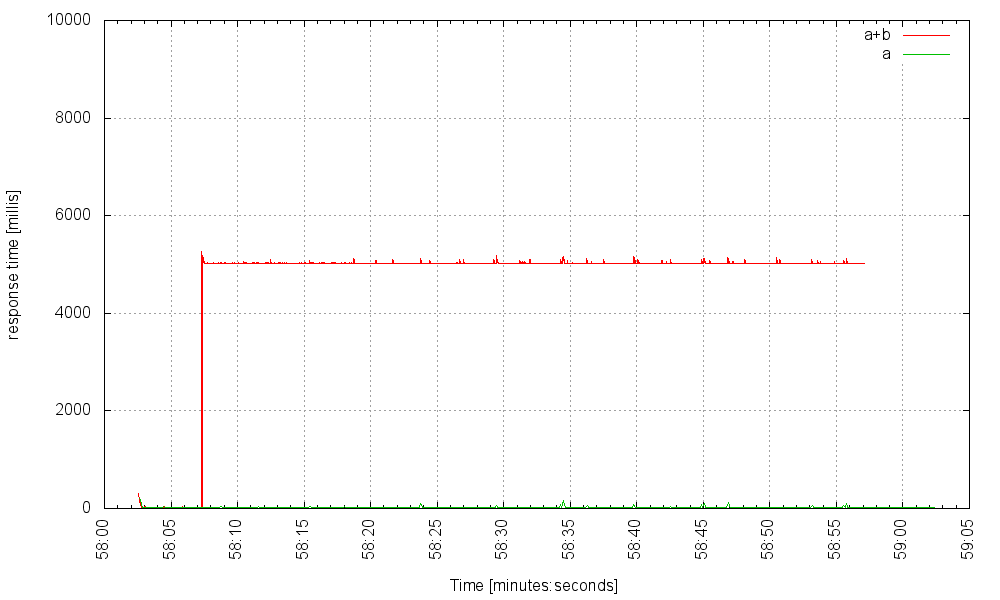
Требуется 5000 запросов в секунду (в условиях сбоя!), Чтобы сервер не отвечал. Черт, служба B может вызвать задержку в 20 секунд, и все же наш сервер может обрабатывать 1500 запросов, которые вызывают сбой службы в секунду, и эти запросы не обращаются к неисправной службе, даже не заметят:
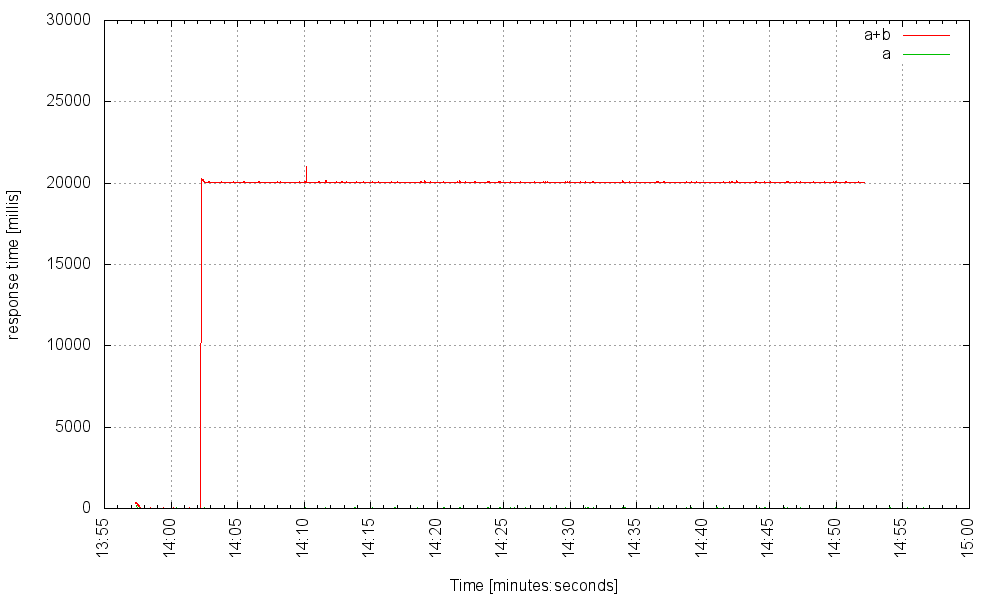
Итак, что здесь происходит? Когда служба B начинает отображать очень большие задержки, волокна, обслуживающие запросы, которые вызывают B, накапливаются на некоторое время, но, поскольку у нас может быть так много волокон, а их служебная нагрузка очень мала, система быстро достигает нового устойчивого состояния — с десятки тысяч заблокированных волокон, но это совершенно нормально!
Расширяем наши возможности
Поскольку наш веб-сервис отправляет исходящие запросы на микросервисы, и поскольку теперь мы можем обслуживать много-много одновременных запросов, наш сервис может в конечном итоге достигнуть другого предела ОС. Каждый исходящий TCP-сокет захватывает эфемерный порт . Мы настроили net.ipv4.ip_local_port_range равным 1024 65535 для общего количества 65535 — 1024 = 64511 исходящих соединений, но наш сервис может обрабатывать намного больше. К сожалению, мы не можем поднять этот предел выше, но поскольку этот предел относится к сетевому интерфейсу, мы можем определить виртуальные интерфейсы и заставить исходящие запросы выбирать интерфейс случайным образом или на основе некоторой логики.
В заключении
Волокна позволяют использовать асинхронный ввод-вывод при сохранении простого и стандартного кода. Таким образом, мы получаем с асинхронным вводом-выводом не уменьшенную задержку (которую мы не тестировали, но нет оснований полагать, что она намного лучше, чем простой ввод-блокирующий поток), а значительно увеличенную емкость. Устойчивое состояние системы поддерживает гораздо более высокую нагрузку. Асинхронный ввод-вывод приводит к лучшему использованию аппаратных ресурсов.
Естественно, у этого подхода есть и недостатки. Главным из них (на самом деле, я думаю, что это единственный) является интеграция библиотек. Каждый API блокировки, который мы вызываем для волокна, должен специально поддерживать волокна. Между прочим, это не является уникальным для подхода с легкими потоками: для использования асинхронного подхода все используемые библиотеки ввода-вывода также должны быть асинхронными. Фактически, если у библиотеки есть асинхронный API, он может быть легко превращен в блокирующий волокно. Проект Comsat представляет собой набор модулей, интегрирующих стандартные или популярные IO API с волокнами Quasar. Последний выпуск Comsat поддерживает сервлеты, серверы и клиенты JAX-RS и JDBC. В следующем выпуске (и используемом в тесте) будет добавлена поддержка HTTP-клиента Apache, Dropwizard, JDBI, Retrofit и, возможно, jOOQ.
| Ссылка: | Масштабируемые, надежные и стандартные веб-сервисы Java с помощью волокон от нашего партнера по JCG Рона Пресслера в блоге Parallel Universe . |