В этом посте я покажу, как поддерживать в БД текущее состояние процесса, управляемого событиями в реальном времени, в масштабируемом и свободном от блокировки виде, благодаря инфраструктуре Storm .
Storm — это механизм обработки данных на основе событий. Его модель опирается на базовые примитивы, такие как преобразование событий, фильтрация, агрегация …, которые мы собираем в топологии . Выполнение топологии обычно распределяется по нескольким узлам, и грозовой кластер также может выполнять несколько экземпляров данной топологии параллельно. Поэтому во время разработки важно иметь в виду, какие примитивы Storm выполняются с областью раздела , то есть на уровне одного узла кластера, а какие — для всего кластера (также называемые операциями перераспределения , поскольку они включают сетевой трафик, который перемещает события из раздел к разделу). В документации по Storm Trident API четко указывается, кто из них делает, что и с какой областью применения. Концепция разделения Storm согласуется с концепцией разделения очередей Kafka , которые являются обычным источником входящих событий.
Топологии обычно должны поддерживать некоторое текущее состояние выполнения. Это может быть, например, среднее скользящего окна для некоторых значений датчика, недавнее мнение, извлеченное из твитов, количество людей, присутствующих в разных местах,… Таким образом, модель масштабируемости здесь особенно важна, поскольку некоторые операции обновления состояния имеют область действия раздела (например, partitionAggregate ), в то время как другие имеют область действия кластера (например, комбинация groupby + perstitentAggregate ). Это позже иллюстрируется в этом посте.
Пример кода доступен на githup . Он основан на Storm 0.8.2, Cassandra 1.2.5 и JDK 1.7.0. Обратите внимание, что этот пример не включает надлежащую обработку ошибок: ни носик, ни болты не поддерживают воспроизведение неудачных кортежей, об этом я расскажу в следующем посте. Кроме того, я использую сериализацию Java для хранения данных в моих кортежах, поэтому даже если Storm поддерживает несколько языков, мой пример специфичен для Java.
Практический пример: присутствие событий
Мой пример — симуляция системы, которая отслеживает положение людей внутри здания. Датчик на входе в каждую комнату выдает событие, подобное приведенному ниже, каждый раз, когда пользователь входит или выходит из комнаты:
|
1
2
3
4
5
6
|
{"eventType": "ENTER", "userId": "John_5", "time": 1374922058918, "roomId": "Cafetaria", "id": "bf499c0bd09856e7e0f68271336103e0A", "corrId": "bf499c0bd09856e7e0f68271336103e0"}{"eventType": "ENTER", "userId": "Zoe_15", "time": 1374915978294, "roomId": "Conf1", "id": "3051649a933a5ca5aeff0d951aa44994A", "corrId": "3051649a933a5ca5aeff0d951aa44994"}{"eventType": "LEAVE", "userId": "Jenny_6", "time": 1374934783522, "roomId": "Conf1", "id": "6abb451d45061968d9ca01b984445ee8B", "corrId": "6abb451d45061968d9ca01b984445ee8"}{"eventType": "ENTER", "userId": "Zoe_12", "time": 1374921990623, "roomId": "Hall", "id": "86a691490fff3fd4d805dce39f832b31A", "corrId": "86a691490fff3fd4d805dce39f832b31"}{"eventType": "LEAVE", "userId": "Marie_11", "time": 1374927215277, "roomId": "Conf1", "id": "837e05916349b42bc4c5f65c0b2bca9dB", "corrId": "837e05916349b42bc4c5f65c0b2bca9d"}{"eventType": "ENTER", "userId": "Robert_8", "time": 1374911746598, "roomId": "Annex1", "id": "c461a50e236cb5b4d6b2f45d1de5cbb5A", "corrId": "c461a50e236cb5b4d6b2f45d1de5cbb5"} |
Каждое событие пары («ENTER» и «LEAVE»), соответствующее одному периоду занятости одного пользователя в одной комнате, имеет одинаковый идентификатор корреляции. Это может потребовать от сенсора много, но для целей этого примера это облегчает мою жизнь  ,
,
Чтобы было интересно, давайте представим, что события, поступающие на наш сервер, не гарантированно соответствуют хронологическому порядку (см. Вызов shuffle () в скрипте python, который генерирует события).
Мы собираемся построить топологию Storm, которая строит временную шкалу занятости каждую минуту, как показано графиком времени в конце этого поста. В базе данных временные шкалы комнаты разбиты на периоды в один час, которые хранятся и обновляются независимо. Вот пример 1 часа занятости Cafetaria:
|
1
2
|
{"roomId":"Cafetaria","sliceStartMillis":1374926400000,"occupancies":[11,12,12,12,13,15,15,14,17,18,18,19,20,22,22,22,21,22,23,25,25,25,28,28,33,32,31,31,29,28,27,27,25,22,22,21,20,19,19,19,17,17,16,16,15,15,16,15,14,13,13,12,11,10,9,11,10,9,11,10]} |
Чтобы произвести это, наша топология должна:
- перегруппировать события «ENTER» и «LEAVE» на основе correlationID и произвести соответствующий период присутствия для этого пользователя в этой комнате
- Примените влияние каждого периода присутствия на график занятости комнаты.
В качестве стороны, Cassandra предоставляет столбцы Counter, которые я здесь не использую, хотя они были бы хорошей альтернативой механизму, который я представляю. Моя цель, однако, состоит в том, чтобы проиллюстрировать функциональные возможности Storm, даже если этот подход немного надуманный
Группировка по / persistentAggregate / iBackingMap объяснила
Прежде чем смотреть на пример кода, давайте выясним, как эти примитивы Trident Storm работают вместе.
Представьте, что мы получили два события, описывающие присутствие пользователя в комнате A с 9:47 до 10:34. Обновление графика комнаты требует:
- загрузить из БД два затронутых фрагмента временной шкалы: [9:00, 10:00] и [10:00, 11:00]
- добавить присутствие этого пользователя в этих двух срезах шкалы времени
- сохранить их в БД
Реализация такой наивно, как это, однако, далека от оптимальной, во-первых, потому что она использует два запроса БД на событие, во-вторых, потому что эта последовательность «чтение-обновление-запись» обычно требует механизм блокировки, который обычно плохо масштабируется.
Для решения первого пункта мы хотим перегруппировать операции БД по нескольким событиям. В Storm события (или кортежи ) обрабатываются как пакеты. IBackingMap — это примитив, который мы можем реализовать и который позволяет нам просматривать целую партию кортежей одновременно. Мы собираемся использовать это для перегруппировки всех операций чтения из БД в начале пакета (multiget) и всех операций записи в DB в конце (multiput). Мультисет не позволяет нам смотреть на сами кортежи, а только на «ключи запроса», которые вычисляются из контента кортежей, как описано ниже.
Причина этого кроется во втором пункте, поднятом выше о наивной реализации: мы хотим выполнить несколько потоков [multiget + our update logic + multiput] параллельно, не полагаясь на блокировки. Это достигается благодаря тому, что эти параллельные подпроцессы обновляют непересекающиеся наборы данных. Это требует, чтобы элемент топологии, определяющий разбиение на параллельные потоки, также контролировал, какие данные загружаются и обновляются в БД в каждом потоке. Этот элемент является примитивом Storm groupBy: он определяет разбиение путем группировки кортежей по значению поля и контролирует, какие данные обновляются каждым параллельным потоком, предоставляя значения «groupedBy» в качестве ключа запроса для мультигетера.
Следующая картинка иллюстрирует это на примере занятости комнаты (упрощено, если хранить только одну временную шкалу на комнату, а не одну временную шкалу на один час):
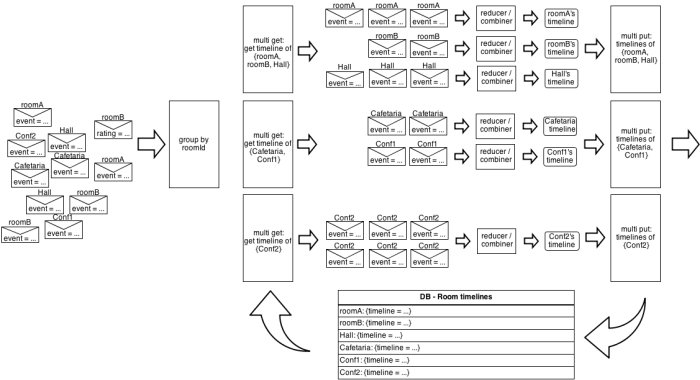
Параллелизм не происходит точно так же (например, текущая реализация Storm последовательно вызывает каждый редуктор / объединитель в сгруппированном потоке), но это хорошая модель, которую следует учитывать при проектировании топологий.
Интересно осознавать, что между groupBy и multiget происходит некое волшебство Storm. Напомним, что Storm предназначен для массового распределения, что подразумевает, что каждый поток выполняется параллельно на нескольких узлах, получая входные данные из распределенных источников данных, таких как Hadoop HDFS или распределенных очередей Kafka. Это означает, что groupBy () выполняется на нескольких узлах одновременно, все потенциально обрабатывающие события, которые должны быть сгруппированы вместе. groupBy — это операция перераспределения, которая гарантирует, что все события, которые должны быть сгруппированы вместе, будут отправлены на один и тот же узел и обработаны одним и тем же экземпляром IBackingMap + комбинатор или редуктор, поэтому условия гонки не возникают.
Кроме того, Storm требует, чтобы мы поместили нашу IBackingMap в один из доступных примитивов Storm MapState (или наш собственный …), обычно для обработки неудачных / воспроизводимых кортежей. Как уже упоминалось выше, я не обсуждаю этот аспект в этом посте.
При таком подходе мы должны реализовать наш IBackingMap, чтобы он учитывал следующее свойство:
- Строка (и) БД, читаемые multiget и записываемые многопользовательскими операциями IBackingMap для разных значений ключа, должны быть различны.
Я думаю, именно поэтому они назвали эти значения «ключом» (хотя все, что уважает это свойство, должно быть в порядке).
Вернуться к примеру
Посмотрим, как это работает на практике. Основная топология примера доступна здесь :
|
1
2
3
|
// reading events.newStream("occupancy", new SimpleFileStringSpout("data/events.json", "rawOccupancyEvent")).each(new Fields("rawOccupancyEvent"), new EventBuilder(), new Fields("occupancyEvent")) |
В этой первой части мы просто читаем входные события в формате JSON (я использую простой файл spout), десериализовываем их и помещаем в поле кортежа с именем «оккупация» с использованием сериализации java. Каждый из этих кортежей описывает событие «ENTER» или «LEAVE» для пользователя, входящего или выходящего из комнаты.
|
1
2
3
4
5
|
// gathering "enter" and "leave" events into "presence periods".each(new Fields("occupancyEvent"), new ExtractCorrelationId(), new Fields("correlationId")).groupBy(new Fields("correlationId")).persistentAggregate( PeriodBackingMap.FACTORY, new Fields("occupancyEvent"), new PeriodBuilder(), new Fields("presencePeriod")).newValuesStream() |
Примитив groupBy позволяет создавать столько групп кортежей, сколько мы встречаем с разными значениями correlationId (что может много значить, поскольку обычно не более двух событий имеют одинаковый correlationId). Все кортежи, имеющие одинаковый идентификатор корреляции в текущем пакете, будут перегруппированы вместе, и одна или несколько групп кортежей будут представлены вместе с элементами, определенными в persistentAggregate. PeriodBackingMap — это наша реализация IBackingMap, где мы реализуем метод multiget, который будет получать все идентификаторы корреляции группы групп кортежей, которые мы будем обрабатывать на следующих шагах (например: {«roomA», «roomB», «Hall»). ”}, На картинке выше).
|
1
2
3
|
public List<RoomPresencePeriod> multiGet(List<List<Object>> keys) { return CassandraDB.DB.getPresencePeriods(toCorrelationIdList(keys));} |
Этот код просто необходимо извлечь из БД потенциально существующие периоды для каждого идентификатора корреляции. Поскольку мы сделали groupBy для одного поля кортежа, каждый список содержит здесь одну строку: correlationId. Обратите внимание, что возвращаемый список должен иметь точно такой же размер, что и список ключей, чтобы Storm знал, какой период соответствует какому ключу. Поэтому для любого ключа, который не существует в БД, мы просто помещаем нуль в результирующий список.
Как только это будет загружено, Storm будет представлять кортежи с одинаковым идентификатором корреляции один за другим нашему редуктору PeriodBuilder . В нашем случае мы знаем, что в этом пакете он будет вызываться максимум дважды для каждого уникального корреляционного идентификатора, но это может быть больше в общем случае или только один раз, если другое событие ENTER / LEAVE отсутствует в текущем пакете. Прямо между вызовами muliget () / multiput () и нашим редуктором Storm позволяет нам вставлять соответствующую логику для повторов ранее неудачных кортежей благодаря реализации MapState по нашему выбору. Подробнее об этом позже.
Как только мы уменьшили каждую последовательность кортежей, Storm передаст наш результат в функцию mulitput () нашего IBackingMap, где мы просто «добавим» все в БД:
|
1
2
3
|
public void multiPut(List<List<Object>> keys, List<RoomPresencePeriod> newOrUpdatedPeriods) { CassandraDB.DB.upsertPeriods(newOrUpdatedPeriods);} |
Storm persistenceAggregate автоматически отправляет в последующие части кортежей топологии значения, которые наш редуктор предоставил функции multitput (). Это означает, что периоды присутствия, которые мы только что создали, легко доступны в виде полей кортежей, и мы можем использовать их для непосредственного обновления временных шкал комнаты:
|
1
2
3
4
5
|
// building room timeline.each(new Fields("presencePeriod"), new IsPeriodComplete()).each(new Fields("presencePeriod"), new BuildHourlyUpdateInfo(), new Fields("roomId", "roundStartTime")).groupBy(new Fields("roomId", "roundStartTime")).persistentAggregate( TimelineBackingMap.FACTORY, new Fields("presencePeriod","roomId", "roundStartTime"), new TimelineUpdater(), new Fields("hourlyTimeline")) |
Первая строка просто отфильтровывает любой период, еще не содержащий события «ENTER» и «LEAVE».
Затем BuildHourlyUpdateInfo реализует логику передачи кортежей « один ко многим»: для каждого периода занятости он просто генерирует один кортеж в «начальный час». Например, присутствие в комнате А с 9:47 до 10:34 могло бы вызвать выброс кортежа для фрагмента шкалы времени А в 9.00 и другого для 10.00.
Следующая часть реализует тот же подход groupBy / IBackingMap, что и раньше, просто на этот раз с двумя ключами группировки вместо одного (так что теперь List <Object> в мультиблоке будет содержать два значения: одно String и одно Long). Поскольку мы храним куски временной шкалы в течение одного часа, необходимо соблюдать указанное выше свойство IBackingMap. Мульти-гаджет получает фрагменты шкалы времени для каждой пары («roomId», «время начала»), затем TimelineUpdater (снова редуктор) обновляет фрагмент шкалы времени с каждым периодом присутствия, соответствующим этому фрагменту шкалы времени, найденному в текущем пакете (это является целью логика передачи кортежей один-ко-многим из BuildHourlyUpdateInfo) и multiput () просто сохраняют результат.
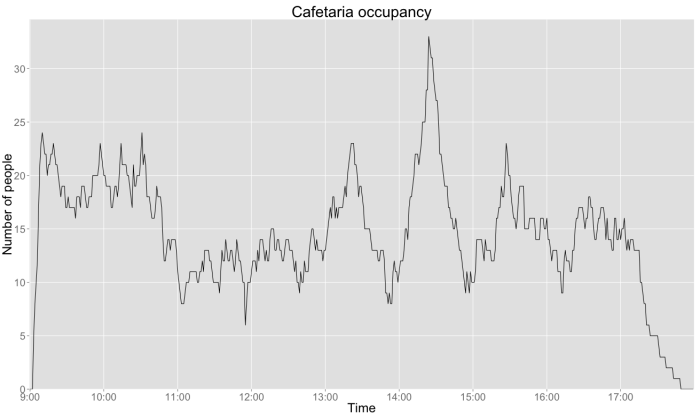
Результирующая заполняемость кафе
Все всегда красивее, когда мы можем смотреть на это, поэтому давайте наметим занятость комнаты , Немного кода R позже, у нас есть эта визуализация загрузки комнаты каждую минуту (что не так много значит, так как все данные случайные, но хорошо…):
Вывод
Надеемся, что этот пост представляет один полезный подход для поддержания состояния в топологиях Storm. Я также попытался проиллюстрировать реализацию логики обработки в небольших элементах топологии, подключенных друг к другу, в отличие от нескольких «мегамолков», объединяющих длинные и сложные кусочки логики.
Одним из важных аспектов Storm является его расширяемость, очень возможно пойти и подключить подклассы того или иного места, чтобы настроить его поведение. У него такое умное и забавное чувство, которое было у Весны 10 лет назад (о, черт, я чувствую себя старым сейчас… ^ __ ^)