
Что такое Lucene?
Apache LuceneTM — это высокопроизводительная, полнофункциональная библиотека для текстового поиска, полностью написанная на Java. Это технология, подходящая практически для любого приложения, требующего полнотекстового поиска, особенно кросс-платформенного.
Lucene может простой текст, целые числа, индекс PDF, офисные документы. и т.д.,
Как Lucene включает более быстрый поиск?
Lucence создает нечто, называемое Inverted Index. Обычно мы отображаем документ -> условия в документе. Но Lucene делает наоборот. Создает индексный термин -> список документов, содержащих этот термин, что ускоряет поиск.
Установить Lucene
Maven Dependency
|
1
2
3
4
5
6
7
|
<span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left"><pre class='brush:xml'><dependency></span> <pre class = 'brush: xml'> <зависимость></span> <span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left"><groupid>org.apache.lucene</groupid></span> <GroupID> org.apache.lucene </ GroupID></span> <span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left"><artifactid>lucene-core</artifactid></span> <Артефакт> Lucene-ядро </ артефакт></span> <span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left"><version>3.0.2</version></span> <Версия> 3.0.2 </ версия></span> <span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left"><type>jar</type></span> <Тип> банку </ тип></span> <span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left"><scope>compile</scope></span> <Сфера> компиляции </ сфера></span><span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left"></dependency></span> </ Зависимость></span> |
Скачать зависимость
Загрузите Lucene с http://lucene.apache.org/ и добавьте lucene-core.jar в путь к классам.
Как работает Lucene?
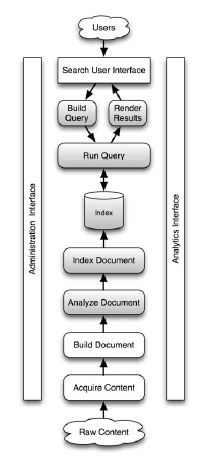
Давайте разберемся с картиной сначала снизу — Центр. Необработанный текст используется для создания Lucene ‘Document’, который анализируется с использованием указанного анализатора, и Document добавляется в индекс на основе свойств Store, TermVector и Analzed полей.
Далее поиск сверху вниз. Пользователи указывают запрос в текстовом формате. Объект запроса строится на основе текста запроса, и результат выполненного запроса возвращается как TopDocs.
Основные классы Lucene
| Каталог, FSDirectory, RAMDirectory | Каталог, содержащий индекс
Файловая система на основе индекса dir Основанный на памяти индекс dir |
каталог
indexDirectory = FSDirectory.open (новый файл (‘c: // lucene // узлы’)); |
| IndexWriter | Обработка записи в индекс — addDocument, updateDocument, deleteDocuments, слияние и т. Д. | IndexWriter writer = новый IndexWriter (indexDirectory,
новый StandardAnalyzer (Version.LUCENE_30), новый MaxFieldLength (1010101)); |
| IndexSearcher | Поиск с использованием indexReader — search (query, int) | IndexSearcher searcher = new IndexSearcher (indexDirectory); |
| Документ | DTO используется для индексации и поиска | Документ документа = новый документ (); |
| поле | Каждый документ содержит несколько полей. Имеет 2 части, имя, значение. | новое поле (‘id’, ‘1’, Store.YES, Index.NOT_ANALYZED) |
| Срок | Слово из теста. Используется в search.2 parts.Field для поиска и значение для поиска | Термин термин = новый термин («id», «1»); |
| запрос | База всех типов запросов — TermQuery, BooleanQuery, PrefixQuery, RangeQuery, WildcardQuery, PhraseQuery и т. Д. | Query query = new TermQuery (term); |
| анализатор | Создает токены из текста и помогает в создании терминов индекса из текста | новый стандартный анализатор () |
Справочник Lucene
Каталог — это пространство данных, в котором работает lucene. Это может быть файловая система или память.
Ниже приведены часто используемые каталоги
| каталог | Описание | пример |
| FSDirectory | Каталог на основе файловой системы | Directory = FSDirectory.open (файл файла); // Файл -> Путь к каталогу |
| RAMDirectory | Директория Lucene на основе памяти | Directory = новый MemoryDirectory ()
Directory = новый MemoryDirectory (каталог dir) // загрузить файловый каталог в память |
Создать запись в индексе
Lucene ‘Document’ — это основной объект, используемый при индексации. Документы содержат несколько полей. Анализаторы работают с полями документа, разбивая их на токены, а затем записывают Справочник с помощью Index Writer.
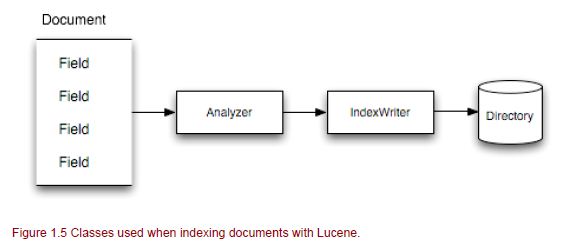
IndexWriter
|
1
|
<span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">IndexWriter writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_30), true, MaxFieldLength.UNLIMITED);</span> IndexWriter writer = new IndexWriter (indexDirectory, новый StandardAnalyzer (Version.LUCENE_30), true, MaxFieldLength.UNLIMITED);</span> |
Анализаторы
Работа по анализу текста в токены или ключевые слова для поиска. Есть несколько стандартных анализаторов, предоставляемых Lucene. Выбор Analyzer определил, как индексированный текст маркируется и ищется.
Ниже приведены некоторые стандартные анализаторы.
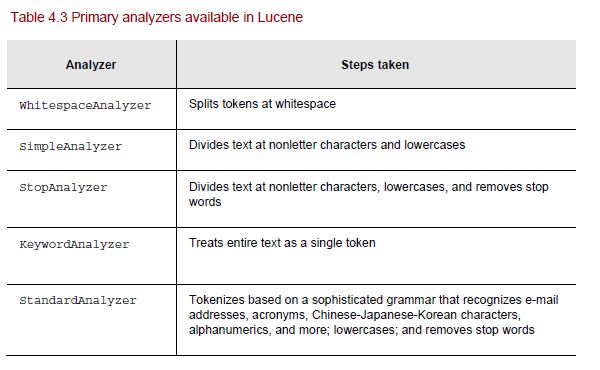
Пример — как анализаторы работают с образцом текста

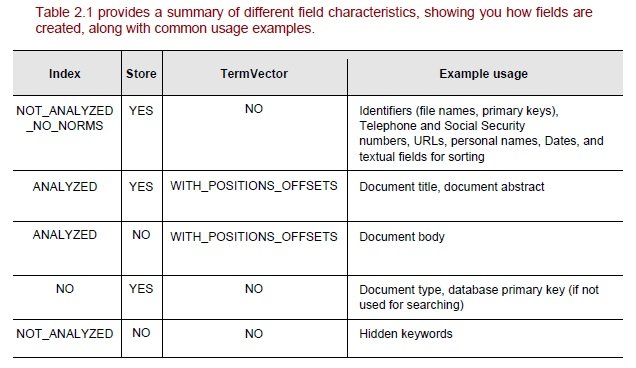
Свойства, которые определяют индексирование полей
- Store — если поле будет сохранено для извлечения в будущем
- ANALYZED — Должно ли содержимое быть разбито на токены
- TermVECTOR — основанные на сроке детали, которые будут сохранены или нет
Хранить :
Если поле будет сохранено, чтобы получить позже
| STORE.YES | Сохранить значение, может быть получено позже из индекса |
| ХРАНИТЬ НЕТ | Не хранить. Используется вместе с Index.ANALYZED. Когда токены используются только для поиска |
Анализируются:
Как анализировать текст
| Index.ANALYZED | Разбейте текст на токены, индексируйте каждый токен, чтобы сделать его доступным для поиска |
| Index.NOT_ANALYZED | Индексируйте весь текст как один токен, но не анализируйте (разбивайте их) |
| Index.ANALYZED_NO_NORMS | То же, что и ANALYZED, но не хранит норм |
| Index.NOT_ANALYZED_NO_NORMS | То же, что NOT_ANALYZED, но без норм |
| Index.NO | не сделать это поле полностью доступным для поиска |
Термин вектор
Нужны детали термина для аналога, выделения
| TermVector.YES | запись УНИКАЛЬНЫЕ УСЛОВИЯ + СЧЕТА + НЕТ ПОЗИЦИЙ + НЕТ СМЕЩЕНИЙ в каждом документе |
| TermVector.WITH_POSITIONS | запись УНИКАЛЬНЫЕ УСЛОВИЯ + СЧЕТА + ПОЗИЦИИ + НЕТ СМЕЩЕНИЙ в каждом документе |
| TermVector.WITH_OFFSETS | запись УНИКАЛЬНЫЕ УСЛОВИЯ + СЧЕТА + НЕТ ПОЗИЦИЙ + СМЕЩЕНИЯ в каждом документе |
| TermVector.WITH_POSITIONS_OFFSETS | запись УНИКАЛЬНЫЕ УСЛОВИЯ + СЧЕТА + ПОЗИЦИИ + СМЕЩЕНИЯ в каждом документе |
| TermVector.NO | Не записывать информацию вектора терминов |
Пример создания индекса
|
1
2
3
4
5
6
7
|
<span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">IndexWriter writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_30), true,MaxFieldLength.UNLIMITED);</span> IndexWriter writer = new IndexWriter (indexDirectory, новый StandardAnalyzer (Version.LUCENE_30), true, MaxFieldLength.UNLIMITED);</span><span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">Document document = new Document();</span> Документ документа = новый документ ();</span><span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">document.add(new Field('id', '1', Store.YES, Index.NOT_ANALYZED));</span> document.add (новое поле ('id', '1', Store.YES, Index.NOT_ANALYZED));</span><span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">document.add(new Field('name', 'user1', Store.YES, Index.NOT_ANALYZED));</span> document.add (новое поле ('name', 'user1', Store.YES, Index.NOT_ANALYZED));</span><span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">document.add(new Field('age', '20', Store.YES, Index.NOT_ANALYZED));</span> document.add (новое поле ('age', '20', Store.YES, Index.NOT_ANALYZED));</span><span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">writer.addDocument(document);</span> writer.addDocument (документ);</span> |
Пример обновления индекса
|
1
2
3
4
5
6
7
|
<span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">IndexWriter writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_30), true,MaxFieldLength.UNLIMITED);</span> IndexWriter writer = new IndexWriter (indexDirectory, новый StandardAnalyzer (Version.LUCENE_30), true, MaxFieldLength.UNLIMITED);</span> <span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">Document document = new Document();</span> Документ документа = новый документ ();</span><span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">document.add(new Field("id", "1", Store.YES, Index.NOT_ANALYZED));</span> document.add (новое поле («id», «1», Store.YES, Index.NOT_ANALYZED));</span><span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">document.add(new Field("name", "user1", Store.YES, Index.NOT_ANALYZED));</span> document.add (новое поле («имя», «пользователь1», Store.YES, Index.NOT_ANALYZED));</span><span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">document.add(new Field("age", "20", Store.YES, Index.NOT_ANALYZED));</span> document.add (новое поле ("age", "20", Store.YES, Index.NOT_ANALYZED));</span><span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">writer.addDocument(document);</span> writer.addDocument (документ);</span> |
Пример удаления индекса
|
1
2
3
4
|
<span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">IndexWriter writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_30), MaxFieldLength.UNLIMITED);</span> IndexWriter writer = new IndexWriter (indexDirectory, новый StandardAnalyzer (Version.LUCENE_30), MaxFieldLength.UNLIMITED);</span><span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">Term term = new Term('id', '1');</span> Термин термин = новый термин («id», «1»);</span><span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">writer.deleteDocuments(term);</span> writer.deleteDocuments (срок);</span> |
Поиск по индексу: 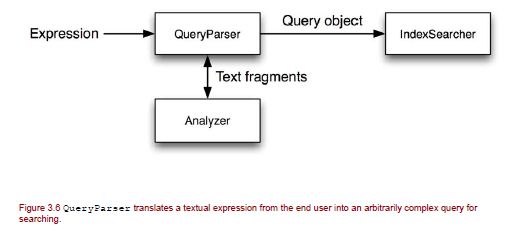 Пользователи указывают запрос в текстовом формате. Объект запроса строится на основе текста запроса, анализируется, и результат выполненного запроса возвращается как TopDocs.
Пользователи указывают запрос в текстовом формате. Объект запроса строится на основе текста запроса, анализируется, и результат выполненного запроса возвращается как TopDocs.
Запросы являются основным входом для поиска.
| TermQuery | |
| BooleanQuery | И или нет (объединить несколько запросов) |
| PrefixQuery | Начинается с |
| WildcardQuery | ? И * — * не допускается в начале |
| PhraseQuery | Точная фраза |
| RangeQuery | Термин диапазон или числовой диапазон |
| FuzzyQuery | Поиск похожих слов |
Примеры запросов
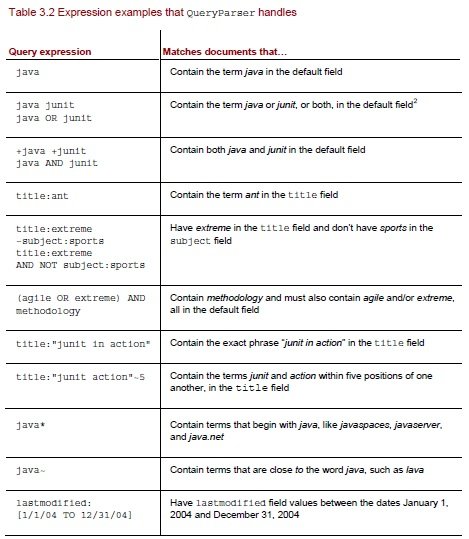
Пример по поиску:
|
1
2
3
4
5
6
7
8
|
<span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">IndexSearcher searcher = new IndexSearcher(indexDirectory);</span> IndexSearcher searcher = new IndexSearcher (indexDirectory);</span><span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">Term term = new Term('id', '1');</span> Термин термин = новый термин («id», «1»);</span><span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">Query query = new TermQuery(term);</span> Query query = new TermQuery (term);</span><span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">TopDocs docs = searcher.search(query, 3);</span> TopDocs docs = searcher.search (query, 3);</span><span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">for (int i = 1; i <= docs.totalHits; i++)</span> for (int i = 1; i <= docs.totalHits; i ++)</span><span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">{</span> {</span> <span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">System.out.println(searcher.doc(i));</span> System.out.println (searcher.doc (я));</span><span class="notranslate" onmouseover="_tipon(this)" onmouseout="_tipoff()"><span class="google-src-text" style="direction: ltr; text-align: left">}</span> }</span> |
Диагностические инструменты Lucene:
- Люк — http://code.google.com/p/luke/
Luke — это удобный инструмент для разработки и диагностики, который обращается к уже существующим индексам Lucene и позволяет отображать и изменять их содержимое несколькими способами: - Лимузин — http://limo.sourceforge.net/
Идея состоит в том, чтобы иметь небольшой инструмент, работающий как веб-приложение, которое дает основную информацию об индексах, используемых поисковой системой Lucene.
Полный пример:
Скачать здесь: LuceneTester.java
Ресурсы
- http://lucene.apache.org/core/
- http://www.amazon.com/Lucene-Action-Second-Edition-Covers/dp/1933988177/ref=dp_ob_title_bk
Ссылка: Lucene — быстро добавьте возможности индексации и поиска от нашего партнера JCG Шривидхьи Умашанкера в блоге « Мысли о технаре» .