Эта статья также дает вам возможность улучшить свои навыки анализа дампа потоков и понять условия гонки потоков.
Спецификации окружающей среды
- Сервер Java EE: Oracle Weblogic Portal 10.0
- ОС: солярис 10
- JDK: Oracle / Sun HotSpot JVM 1.5
- Логирование API: Apache Log4j 1.2.15
- СУБД: Oracle 10g
- Тип платформы: веб-портал
Инструменты для устранения неполадок
- Quest Foglight for Java (мониторинг и оповещение)
- Java VM Thread Dump (анализ гонки потоков)
Обзор проблемы
Значительное снижение производительности наблюдалось в одной из наших производственных сред Weblogic Portal. Также были отправлены оповещения от агентов Foglight, указывающие на значительный рост использования потоков Weblogic до верхнего предела по умолчанию 400.
Сбор и проверка фактов
Как обычно, исследование проблемы Java EE требует сбора технических и нетехнических фактов, чтобы мы могли либо получить другие факты и / или сделать вывод о первопричине. Перед применением корректирующих мер факты, приведенные ниже, были проверены, чтобы сделать вывод о первопричине:
- Какое влияние оказывает клиент? ВЫСОКИЙ
- Недавнее изменение затронутой платформы? Да, недавно было выполнено развертывание, включающее незначительные изменения содержимого, а также некоторые изменения в библиотеках Java и рефакторинг
- Недавнее увеличение трафика на уязвимую платформу? нет
- С каких пор эта проблема наблюдается? Новая проблема наблюдается после развертывания
- Решил ли перезапуск сервера Weblogic проблему? Нет, любая попытка перезапуска привела к немедленному увеличению потока
- Решил ли откат изменений развертывания проблему? да
Вывод № 1: Проблема, по-видимому, связана с недавними изменениями. Тем не менее, команда изначально не смогла определить причину. Это то, что мы будем обсуждать до конца статьи.
Отчет о потоке веблогов
Первоначальная проблема помпажа была сообщена Foglight. Как вы можете видеть ниже, использование потоков было значительным (до 400), что привело к большому количеству ожидающих запросов клиентов и в конечном итоге к значительному снижению производительности.
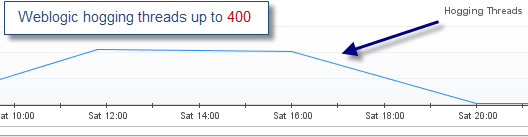
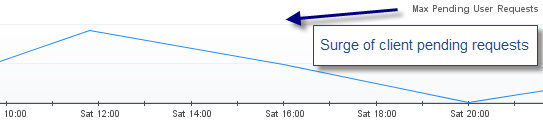
Как обычно, проблемы с потоками требуют надлежащего анализа дампа потоков, чтобы точно определить источник конфликта потоков. Отсутствие этого критического навыка анализа не позволит вам идти дальше в анализе первопричин.
В нашем примере с наших серверов Weblogic было сгенерировано несколько моментальных снимков дампа потока с помощью простой команды Solaris kill kill -3 <Java PID>. Затем данные дампа потоков были извлечены из стандартных файлов вывода Weblogic.
Анализ дампа потока
Первым шагом анализа было быстрое сканирование всех застрявших потоков и выявление проблемного «паттерна». Мы нашли 250 потоков, застрявших в следующем пути выполнения:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
"[ACTIVE] ExecuteThread: '20' for queue: 'weblogic.kernel.Default (self-tuning)'" daemon prio=10 tid=0x03c4fc38 nid=0xe6 waiting for monitor entry [0x3f99e000..0x3f99f970] at org.apache.log4j.Category.callAppenders(Category.java:186) - waiting to lock <0x8b3c4c68> (a org.apache.log4j.spi.RootCategory) at org.apache.log4j.Category.forcedLog(Category.java:372) at org.apache.log4j.Category.log(Category.java:864) at org.apache.commons.logging.impl.Log4JLogger.debug(Log4JLogger.java:110) at org.apache.beehive.netui.util.logging.Logger.debug(Logger.java:119) at org.apache.beehive.netui.pageflow.DefaultPageFlowEventReporter.beginPageRequest(DefaultPageFlowEventReporter.java:164) at com.bea.wlw.netui.pageflow.internal.WeblogicPageFlowEventReporter.beginPageRequest(WeblogicPageFlowEventReporter.java:248) at org.apache.beehive.netui.pageflow.PageFlowPageFilter.doFilter(PageFlowPageFilter.java:154) at weblogic.servlet.internal.FilterChainImpl.doFilter(FilterChainImpl.java:42) at com.bea.p13n.servlets.PortalServletFilter.doFilter(PortalServletFilter.java:336) at weblogic.servlet.internal.FilterChainImpl.doFilter(FilterChainImpl.java:42) at weblogic.servlet.internal.RequestDispatcherImpl.invokeServlet(RequestDispatcherImpl.java:526) at weblogic.servlet.internal.RequestDispatcherImpl.forward(RequestDispatcherImpl.java:261) at <App>.AppRedirectFilter.doFilter(RedirectFilter.java:83) at weblogic.servlet.internal.FilterChainImpl.doFilter(FilterChainImpl.java:42) at <App>.AppServletFilter.doFilter(PortalServletFilter.java:336) at weblogic.servlet.internal.FilterChainImpl.doFilter(FilterChainImpl.java:42) at weblogic.servlet.internal.WebAppServletContext$ServletInvocationAction.run(WebAppServletContext.java:3393) at weblogic.security.acl.internal.AuthenticatedSubject.doAs(AuthenticatedSubject.java:321) at weblogic.security.service.SecurityManager.runAs(Unknown Source) at weblogic.servlet.internal.WebAppServletContext.securedExecute(WebAppServletContext.java:2140) at weblogic.servlet.internal.WebAppServletContext.execute(WebAppServletContext.java:2046) at weblogic.servlet.internal.ServletRequestImpl.run(Unknown Source) at weblogic.work.ExecuteThread.execute(ExecuteThread.java:200) at weblogic.work.ExecuteThread.run(ExecuteThread.java:172) |
Как вы можете видеть, кажется, что все потоки ожидают получения блокировки на мониторе объекта Apache Log4j (org.apache.log4j.spi.RootCategory) при попытке записать отладочную информацию в настроенное приложение и файл журнала. Как мы поняли это из этой трассировки стека потоков? Давайте разберем эту трассировку стека потоков, чтобы вы лучше поняли условие состязания потоков, например, 250 потоков пытаются одновременно получить один и тот же объектный монитор.

На этом этапе главный вопрос: почему мы видим эту проблему внезапно? Повышение уровня регистрации или нагрузки также было исключено на этом этапе после надлежащей проверки. Тот факт, что откат предыдущих изменений действительно решил проблему, естественно, побудил нас провести более глубокий анализ продвигаемых изменений. Прежде чем перейти к последнему разделу о первопричинах, мы выполним проверку кода затронутого кода Log4j, например, подверженного условиям состязания потоков.
Apache Log4j 1.2.15 обзор кода
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
## org.apache.log4j.Category/** * Call the appenders in the hierrachy starting at <code>this</code>. If no * appenders could be found, emit a warning. * * <p> * This method calls all the appenders inherited from the hierarchy * circumventing any evaluation of whether to log or not to log the * particular log request. * * @param event * the event to log. */ public void callAppenders(LoggingEvent event) { int writes = 0; for (Category c = this; c != null; c = c.parent) { // Protected against simultaneous call to addAppender, // removeAppender,... synchronized (c) { if (c.aai != null) { writes += c.aai.appendLoopOnAppenders(event); } if (!c.additive) { break; } } } if (writes == 0) { repository.emitNoAppenderWarning(this); } |
Как вы можете видеть, Catelogry.callAppenders () использует синхронизированный блок на уровне категории, что может привести к серьезному состоянию потока при высокой параллельной нагрузке. В этом сценарии использование повторной входящей блокировки чтения-записи было бы более уместным (например, такая стратегия блокировки допускает одновременное «чтение», но одну «запись»). Вы можете найти ссылку на это известное ограничение Apache Log4j ниже вместе с некоторыми возможными решениями.
https://issues.apache.org/bugzilla/show_bug.cgi?id=41214
Является ли приведенное выше поведение Log4j фактической основной причиной нашей проблемы? Не так быстро … Давайте вспомним, что эта проблема была обнаружена только после недавнего развертывания. На самом деле вопрос в том, какое изменение приложения вызвало эту проблему и побочный эффект от API ведения журнала Apache Log4j?
Основная причина: идеальный шторм!
Глубокий анализ последних развернутых изменений показал, что некоторые библиотеки Log4j на уровне дочернего загрузчика классов были удалены вместе со связанной политикой «сначала дочерний». Это упражнение по рефакторингу привело к переносу делегирования журналов Commons и Log4j на родительский уровень загрузчика классов. В чем проблема?
До этого изменения события журналирования были разделены между вызовами Weblogic Beehive Log4j в родительском загрузчике классов и событиями журналирования веб-приложения в загрузчике дочерних классов. Поскольку у каждого загрузчика классов была своя собственная копия объектов Log4j, проблема состояния гонки потоков была разделена пополам и не отображалась (маскировалась) в текущих условиях загрузки. После рефакторинга все вызовы Log4j были перемещены в родительский загрузчик классов (приложение Java EE); добавление значительного уровня параллелизма к компонентам Log4j, таким как Category. Это повышение уровня параллелизма наряду с известным поведением гонки / тупика потока Category.java стало идеальным штормом для нашей производственной среды.
В другом, чтобы смягчить эту проблему, 2 непосредственных решения были применены к окружающей среде:
- Откат рефакторинга и разделение вызовов Log4j между родительским и дочерним загрузчиком классов.
- Уменьшите уровень регистрации для некоторых приложений от DEBUG до WARNING
Этот проблемный случай вновь подтверждает важность проведения надлежащего тестирования и оценки воздействия при применении таких изменений, как изменения, связанные с библиотекой и загрузчиком классов. Такие изменения могут показаться простыми на «поверхности», но могут вызвать некоторые глубокие изменения в шаблоне выполнения, подвергая ваше приложение (приложения) известным условиям состязания потоков.
Будущее обновление до Apache Log4j 2 (или других API-интерфейсов ведения журналов) также будет рассмотрено, так как ожидается, что оно принесет некоторые улучшения производительности, которые могут решить некоторые из этих проблем гонки и масштабируемости потоков.
Пожалуйста, предоставьте любой комментарий или поделитесь своим опытом по проблемам, связанным с гонкой потоков, с помощью API-интерфейсов регистрации.
Приятного кодирования и не забудьте поделиться!
Ссылка: Log4j Thread Deadlock — пример из практики нашего партнера по JCG Пьера-Хьюга Шарбонно в блоге, посвященном шаблонам поддержки Java EE и учебному пособию по Java .