В этой статье автор книги «Высокопроизводительные вычисления в памяти с помощью Apache Ignite» расскажет об обработке сложных событий с помощью Apache Strom и Apache Ignite. Часть этой статьи взята из главы, посвященной обработке сложных событий
книга
Не существует общепринятого или широко принятого определения термина «Комплексная обработка событий» или CEP. Что такое обработка сложных событий, можно кратко описать как следующую цитату из Википедии:
«Сложная обработка событий, или CEP, это прежде всего концепция обработки событий, которая имеет дело с задачей обработки нескольких событий с целью идентификации значимых событий в облаке событий. CEP использует такие методы, как обнаружение сложных паттернов многих событий, корреляция и абстракция событий, иерархии событий и взаимосвязи между событиями, такими как причинность, членство и время, а также процессы, управляемые событиями ».
Для простоты, комплексная обработка событий (CEP) — это технология фильтрации, агрегации и вычисления с малой задержкой в реальных условиях, никогда не заканчивающаяся или потоковая передача данных событий. Количество и скорость как исходной инфраструктуры, так и бизнес-событий в ИТ-средах экспоненциально растут. Кроме того, взрыв мобильных устройств и повсеместное распространение высокоскоростных соединений способствуют взрыву мобильных данных. В то же время спрос на оперативность и выполнение бизнес-процессов только вырос. Эти две тенденции оказывают давление на организации с целью расширения их возможностей по поддержке шаблонов реализации на основе событий. Для обработки событий в реальном времени требуются инфраструктура и среда разработки приложений для выполнения требований обработки событий. Эти требования часто включают необходимость масштабирования от повседневных сценариев использования до чрезвычайно высоких скоростей или разновидностей данных и пропускной способности событий, потенциально с задержками, измеряемыми в микросекундах, а не секундах времени отклика.
Apache Ignite позволяет обрабатывать непрерывные бесконечные потоки данных в масштабируемой и отказоустойчивой манере в памяти, а не анализировать данные после их поступления в базу данных. Это позволяет не только сопоставлять отношения и выявлять значимые шаблоны из значительно большего количества данных, но и быстрее и эффективнее. История событий может храниться в памяти в течение любого промежутка времени (критического для длительных последовательностей событий) или записываться как транзакции в хранимой базе данных.
Apache Ignite CEP может использоваться во многих отраслях промышленности. Ниже приведены примеры использования первого класса:
- Финансовые услуги: возможность выполнять анализ рисков в режиме реального времени, мониторинг и отчетность по финансовой торговле и обнаружению мошенничества.
- Телекоммуникации: возможность выполнять детальную запись разговоров в реальном времени, мониторинг SMS и DDoS-атаки.
- ИТ-системы и инфраструктура: возможность обнаружения сбойных или недоступных приложений или серверов в режиме реального времени.
- Логистика: возможность отслеживать отгрузки и обработку заказов в режиме реального времени и отчеты о потенциальных задержках по прибытии.
Существует еще несколько промышленных или функциональных областей, где вы можете использовать Apache Ignite для обработки потоковых данных о событиях, таких как страхование, транспорт и государственный сектор. Комплексная обработка событий или CEP содержит три основных части процесса:
- Захват событий или прием данных.
- Вычисление или расчет этих данных.
- Ответ или действие.
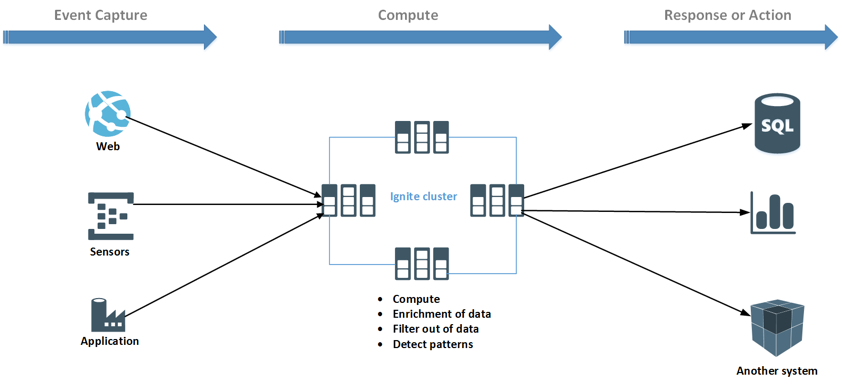
Как показано на рисунке выше, данные поступают из разностных источников. Источниками могут быть любые датчики (IoT), веб-приложения или отраслевые приложения. Потоковые данные могут одновременно обрабатываться непосредственно в кластере Ignite. Кроме того, данные могут быть обогащены из других источников или отфильтрованы. После вычисления данных вычисленные или агрегированные данные могут быть экспортированы в другие системы для визуализации или выполнения действий.
Модуль Apache Ignite Storm Streamer обеспечивает потоковую передачу через Storm в Ignite. Прежде чем начать использовать Ignite Streamer, давайте взглянем на Apache Storm, чтобы получить некоторые основы о Apache Storm.
Apache storm — распределенная отказоустойчивая вычислительная система реального времени. За короткое время Apache Storm стал стандартом для распределенной системы обработки в реальном времени, которая позволяет обрабатывать большие объемы данных. Проект Apache Storm имеет открытый исходный код и написан на Java и Clojure. Это стало первым выбором для аналитики в реальном времени. Модуль Apache Ignite Storm Streamer предоставляет удобный способ потоковой передачи данных через Storm в Ignite.
Ключевые понятия:
Apache Storm считывает необработанный поток данных с одного конца и пропускает его через последовательность небольших блоков обработки и выводит обработанную информацию на другом конце. Давайте подробно рассмотрим основные компоненты Apache Storm —
Кортежи — это основная структура данных Storm. Это упорядоченный список элементов. Как правило, кортеж поддерживает все типы данных примитивов.

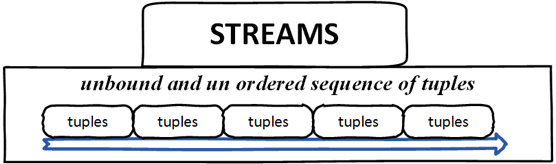
Потоки — это несвязанная и неупорядоченная последовательность кортежей.
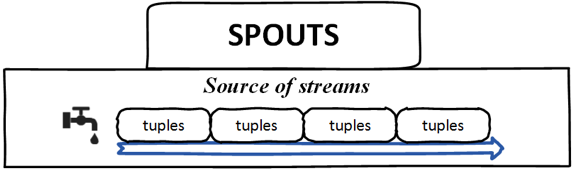
Носики — источник потоков, проще говоря, носик считывает данные из источника для использования в топологии. Носик может быть надежным или ненадежным. Носик может общаться с очередями, веб-журналами, данными о событиях и т. Д.
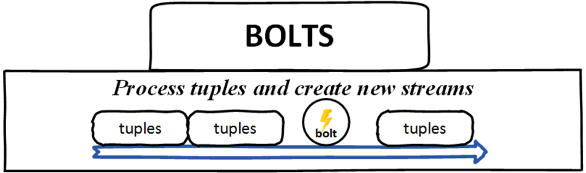
Болты — Болты являются логическими единицами обработки, они отвечают за обработку данных и создание новых потоков. Болты могут выполнять операции фильтрации, агрегирования, объединения, взаимодействия с файлами / базой данных и так далее. Болты получают данные из носика и испускают один или несколько болтов.
Топология — топология — это ориентированный граф носиков и болтов, каждый узел этого графа содержит логику обработки данных (болты), а соединительные ребра определяют поток данных (потоки).
В отличие от Hadoop, Storm поддерживает работу топологии до тех пор, пока вы ее не уничтожите. Простая топология начинается с носиков, испускающих поток из источников для обработки данных. Основная задача Apache Storm — запускать топологию и запускать любое количество топологий в данный момент времени.
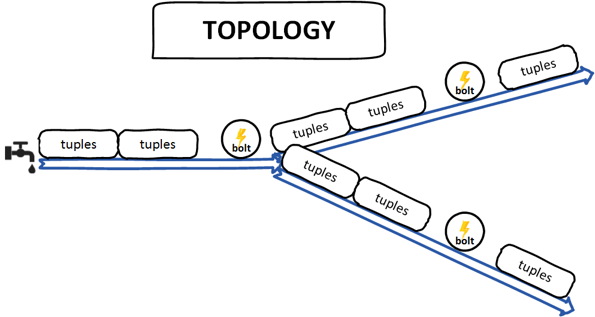
Ignite из коробки предоставляет реализацию Storm Bolt (StormStreamer) для потоковой передачи вычисленных данных в кэш Ignite. С другой стороны, вы можете записать свой собственный Strom Bolt для загрузки потоковых данных в Ignite. Чтобы разработать собственный Storm Bolt, вам просто нужно реализовать интерфейс * BaseBasicBolt * или * IRichBolt * Storm. Однако, если вы решите использовать StormStreamer, вам необходимо настроить несколько свойств для правильной работы болта зажигания. Все обязательные свойства указаны ниже:
| нет | Имя свойства | Описание |
|---|---|---|
| 1 | CacheName | Имя кэша Ignite, в котором будут храниться данные. |
| 2 | IgniteTupleField | Именует поле Ignite Tuple, по которому находятся данные кортежа, полученные в топологии. По умолчанию значение равно ignite. |
| 3 | IgniteConfigFile | Это свойство будет устанавливать конфигурацию пружины Ignite. файл. Позволяет отправлять и потреблять сообщения и от зажечь темы. |
| 4 | AllowOverwrite | Это позволит перезаписать существующие значения в кэше, значение по умолчанию — false. |
| 5 | AutoFlushFrequency | Частота автоматического сброса в миллисекундах. По сути, это время, после которого стример сделает попытаться отправить все данные, добавленные к удаленному узлы. По умолчанию 10 сек. |
Теперь, когда у нас есть основы, давайте создадим что-то полезное, чтобы проверить, как работает Ignite StormStreamer . Основная идея приложения заключается в разработке одной топологии излива и затвора, которая может обрабатывать огромное количество данных из файлов журнала трафика и запускать оповещение, когда конкретное значение пересекает предварительно определенный порог. Используя топологию, файл журнала читается построчно, а топология предназначена для мониторинга входящих данных. В нашем случае файл журнала будет содержать такие данные, как регистрационный номер транспортного средства, скорость и название шоссе с камеры дорожного движения. Если транспортное средство пересекает ограничение скорости (например, 120 км / ч), топология Storm отправит данные в кэш Ignite.
Следующий список покажет CSV-файл того типа, который мы собираемся использовать в нашем примере, который содержит информацию о транспортных средствах, такую как регистрационный номер транспортного средства, скорость, с которой транспортное средство движется, и местоположение шоссе.
|
01
02
03
04
05
06
07
08
09
10
11
12
|
AB 123, 160, North cityBC 123, 170, South cityCD 234, 40, South cityDE 123, 40, East cityEF 123, 190, South cityGH 123, 150, West cityXY 123, 110, North cityGF 123, 100, South cityPO 234, 140, South cityXX 123, 110, East cityYY 123, 120, South cityZQ 123, 100, West city |
Идея приведенного выше примера взята из журнала доктора Доббса. Поскольку эта книга не предназначена для изучения Apache Storm, я собираюсь сделать пример максимально простым. Кроме того, я добавил известный пример подсчета слов в Storm, который вводит значение подсчета слов в кэш Ignite через модуль StormStreamer. Если вам интересно узнать код, он доступен по адресу
глава CEP / шторм . Приведенный выше CSV-файл будет источником топологии Storm.
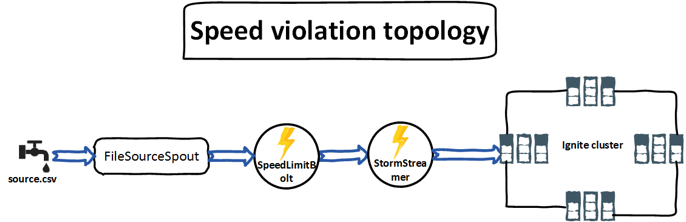
Как показано на рисунке выше, FileSourceSpout принимает входной файл журнала CSV, считывает данные построчно и передает данные в SpeedLimitBolt для дальнейшей обработки пороговых значений. Как только обработка завершена и найден любой автомобиль с превышением ограничения скорости, данные отправляются на болт Ignite StormStreamer, где они попадают в кэш. Давайте углубимся в подробное объяснение нашей топологии Storm.
Шаг 1:
Поскольку это топология Storm, необходимо добавить зависимость Storm и Ignite StormStreamer в проект maven.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
<dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-storm</artifactId> <version>1.6.0</version></dependency><dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-core</artifactId> <version>1.6.0</version></dependency><dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-spring</artifactId> <version>1.6.0</version></dependency><dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>0.10.0</version> <exclusions> <exclusion> <groupId>log4j</groupId> <artifactId>log4j</artifactId> </exclusion> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> <exclusion> <groupId>commons-logging</groupId> <artifactId>commons-logging</artifactId> </exclusion> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> </exclusion> <exclusion> <groupId>org.slf4j</groupId> <artifactId>log4j-over-slf4j</artifactId> </exclusion> <exclusion> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> </exclusion> </exclusions></dependency> |
На момент написания этой книги Apache Storm версии 0.10.0 поддерживается только. Обратите внимание, что вам не нужен какой-либо модуль Kafka для запуска или выполнения этого примера, как описано в документации Ignite.
Шаг 2:
Создайте файл конфигурации Ignite (см. Файл example-ignite.xml в /chapter-cep/storm/src/resources/example-ignite.xml ) и убедитесь, что он доступен из classpath. Содержимое конфигурации Ignite идентично предыдущему разделу этой главы.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
xsi:schemaLocation=" <bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration"> <!-- Enable client mode. --> <property name="clientMode" value="true"/> <!-- Cache accessed from IgniteSink. --> <property name="cacheConfiguration"> <list> <!-- Partitioned cache example configuration with configurations adjusted to server nodes'. --> <bean class="org.apache.ignite.configuration.CacheConfiguration"> <property name="atomicityMode" value="ATOMIC"/> <property name="name" value="testCache"/> </bean> </list> </property> <!-- Enable cache events. --> <property name="includeEventTypes"> <list> <!-- Cache events (only EVT_CACHE_OBJECT_PUT for tests). --> <util:constant static-field="org.apache.ignite.events.EventType.EVT_CACHE_OBJECT_PUT"/> </list> </property> <!-- Explicitly configure TCP discovery SPI to provide list of initial nodes. --> <property name="discoverySpi"> <bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi"> <property name="ipFinder"> <bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder"> <property name="addresses"> <list> <value>127.0.0.1:47500</value> </list> </property> </bean> </property> </bean> </property> </bean></beans> |
Шаг 3:
Создайте файл ignite-storm.properties, чтобы добавить имя кэша, имя кортежа и имя конфигурации Ignite, как показано ниже.
|
1
2
3
|
cache.name=testCachetuple.name=igniteignite.spring.xml=example-ignite.xml |
Шаг 4:
Затем создайте Java-класс FileSourceSpout, как показано ниже,
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
public class FileSourceSpout extends BaseRichSpout { private static final Logger LOGGER = LogManager.getLogger(FileSourceSpout.class); private SpoutOutputCollector outputCollector; @Override public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) { this.outputCollector = spoutOutputCollector; }@Override public void nextTuple() { try { Path filePath = Paths.get(this.getClass().getClassLoader().getResource("source.csv").toURI()); try(Stream<String> lines = Files.lines(filePath)){ lines.forEach(line ->{ outputCollector.emit(new Values(line)); }); } catch(IOException e){ LOGGER.error(e.getMessage()); } } catch (URISyntaxException e) { LOGGER.error(e.getMessage()); } } @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { outputFieldsDeclarer.declare(new Fields("trafficLog")); }} |
Код FileSourceSpout имеет три важных метода
- open (): этот метод вызывается в начале излива и выдаст вам контекстную информацию.
- nextTuple (): этот метод позволит вам передавать один кортеж в топологию Storm для обработки за один раз. В этом методе я построчно считываю файл CSV и отправляю строку в виде кортежа болту.
- DeclareOutputFields (): Этот метод объявляет имя выходного кортежа, в нашем случае, имя должно быть trafficLog.
Шаг 5:
Теперь создайте класс SpeedLimitBolt.java, который реализует интерфейс BaseBasicBolt .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public class SpeedLimitBolt extends BaseBasicBolt { private static final String IGNITE_FIELD = "ignite"; private static final int SPEED_THRESHOLD = 120; private static final Logger LOGGER = LogManager.getLogger(SpeedLimitBolt.class); @Override public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) { String line = (String)tuple.getValue(0); if(!line.isEmpty()){ String[] elements = line.split(","); // we are interested in speed and the car registration number int speed = Integer.valueOf((elements[1]).trim()); String car = elements[0]; if(speed > SPEED_THRESHOLD){ TreeMap<String, Integer> carValue = new TreeMap<String, Integer>(); carValue.put(car, speed); basicOutputCollector.emit(new Values(carValue)); LOGGER.info("Speed violation found:"+ car + " speed:" + speed); } } } @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { outputFieldsDeclarer.declare(new Fields(IGNITE_FIELD)); }} |
Давайте пройдемся по строке снова.
- execute (): это метод, в котором вы реализуете бизнес-логику своего болта, в этом случае я разделяю строку запятой и проверяю ограничение скорости автомобиля. Если ограничение скорости данного автомобиля выше порога, мы создаем новый тип данных древовидной карты из этого кортежа и отправляем кортеж на следующий болт, в нашем случае следующим болтом будет StormStreamer.
- DeclareOutputFields (): Этот метод аналогичен методу метод методе метод встроенного в FileSourceSpout, он объявляет, что он собирается вернуть кортеж Ignite для дальнейшей обработки.
Обратите внимание, что здесь важно имя кортежа IGNITE , StormStreamer будет обрабатывать кортеж только с именем Ignite.
Шаг 6:
Настало время создать нашу топологию, чтобы запустить наш пример. Топология связывает носики и болты вместе на графике, который определяет, как данные передаются между компонентами. Он также предоставляет подсказки параллелизма, которые Storm использует при создании экземпляров компонентов в кластере. Для реализации топологии создайте новый файл с именем SpeedViolationTopology.java в каталоге src \ main \ java \ com \ blu \ imdg \ storm \ topology. Используйте следующее как содержимое файла:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
public class SpeedViolationTopology { private static final int STORM_EXECUTORS = 2; public static void main(String[] args) throws Exception { if (getProperties() == null || getProperties().isEmpty()) { System.out.println("Property file <ignite-storm.property> is not found or empty"); return; } // Ignite Stream Ibolt final StormStreamer<String, String> stormStreamer = new StormStreamer<>(); stormStreamer.setAutoFlushFrequency(10L); stormStreamer.setAllowOverwrite(true); stormStreamer.setCacheName(getProperties().getProperty("cache.name")); stormStreamer.setIgniteTupleField(getProperties().getProperty("tuple.name")); stormStreamer.setIgniteConfigFile(getProperties().getProperty("ignite.spring.xml")); TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("spout", new FileSourceSpout(), 1); builder.setBolt("limit", new SpeedLimitBolt(), 1).fieldsGrouping("spout", new Fields("trafficLog")); // set ignite bolt builder.setBolt("ignite-bolt", stormStreamer, STORM_EXECUTORS).shuffleGrouping("limit"); Config conf = new Config(); conf.setDebug(false); conf.setMaxTaskParallelism(1); LocalCluster cluster = new LocalCluster(); cluster.submitTopology("speed-violation", conf, builder.createTopology()); Thread.sleep(10000); cluster.shutdown(); } private static Properties getProperties() { Properties properties = new Properties(); InputStream ins = SpeedViolationTopology.class.getClassLoader().getResourceAsStream("ignite-storm.properties"); try { properties.load(ins); } catch (IOException e) { e.printStackTrace(); properties = null; } return properties; }} |
Давайте пройдемся по строке снова. Сначала мы читаем файл ignite-strom.properties, чтобы получить все необходимые параметры для последующей настройки болта StormStreamer. Топология шторма — это в основном структура Thrift. Класс TopologyBuilder предоставляет простой и элегантный способ построения сложной топологии Storm. Класс TopologyBuilder имеет методы для setSpout и setBolt. Затем мы использовали построитель топологий для построения топологии Storm и добавили spout с именем spout и подсказкой параллелизма 1 исполнителя.
Мы также определяем SpeedLimitBolt для топологии с подсказкой параллелизма 1 исполнителя. Затем мы устанавливаем болт StormStreamer с произвольной группировкой , которая подписывается на болт и в равной степени распределяет кортежи (ограничения) по экземплярам болта StormStreamer.
В целях разработки мы создаем локальный кластер с использованием экземпляра LocalCluster и отправляем топологию с помощью метода submitTopology . Как только топология будет передана в кластер, мы подождем 10 секунд, пока кластер вычислит представленную топологию, а затем выключим кластер, используя метод shutdown LocalCluster .
Шаг 7:
Затем запустите локальный узел Apache Ignite или кластер. После построения проекта maven используйте следующую команду для локального запуска топологии.
|
1
|
mvn compile exec:java -Dstorm.topology=com.blu.imdg.storm.topology.SpeedViolationTopology |
Приложение будет производить много системных журналов следующим образом.
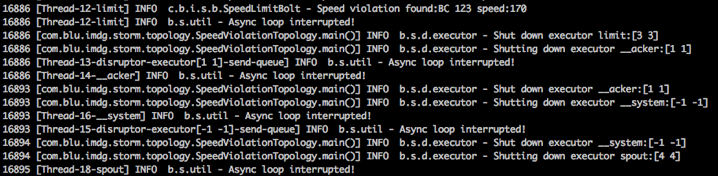
Теперь, если мы проверим кэш Ignite через ignitevisior , мы должны получить следующий вывод в консоль.

Результат показывает результат, который мы ожидали. Из нашего файла журнала source.csv только пять автомобилей превышают ограничение скорости в 120 км / ч.
Это в значительной степени подводит итог практического обзора Ignite Storm Streamer. Если вам интересны Ignite Camel или Ignite Flume streamer, обратитесь к книге «Высокопроизводительные вычисления в памяти с Apache Ignite» . Вы также можете связаться с автором для получения бесплатной копии книги, книга распространяется бесплатно для студентов и преподавателей.
| Ссылка: | Комплексная обработка событий (CEP) с помощью Apache Storm и Apache Ignite от нашего партнера по JCG Шамима Бхуияна в блоге My workspace . |