Что такое редактор?
Для меня редактор — это основной инструмент, который я использую для работы. Как инженер по языкам, я создаю новые языки, использую существующие и мне нужны разные инструменты для работы с ними. Я хотел бы иметь возможность взломать их все вместе, в индивидуальной среде разработки, которую я могу вырастить для себя. Вот почему я работаю над канвасом, взломанным редактором. Который на GitHub , конечно.
Во многих случаях мне нужен простой текстовый редактор для моих DSL, и я стараюсь создавать их с помощью ANTLR. Мне понадобятся другие вещи, такие как табличные или графические проекции, симуляторы и многое другое, но мне нужно где-то начать, верно? Кроме того, я думаю, что сейчас нет простого способа получить автономный редактор для DSL с минимальными зависимостями и простой структурой . В меню нет подсветки. Время добавить один.
Быстро получить редактор из вашей грамматики
Как только вы определили грамматику вашего языка, вы можете извлечь из нее много информации. Я думаю, что вы должны быть в состоянии получить как можно больше выгоды от него бесплатно, с возможностью его дальнейшей настройки, если это необходимо. Это похоже на идею Xtext (за исключением 400 страниц, которые вам нужно прочитать, чтобы понять EMF).
Как быстро вы можете получить редактор для вашей грамматики ANTLR? Вы создаете новый проект для своего редактора, добавляете Kanvas в качестве зависимости и регистрируете, какие языки вы намереваетесь поддерживать:
|
1
2
3
4
5
6
7
|
fun main(args: Array<String>) { languageSupportRegistry.register("sm", smLangSupport) val kanvas = Kanvas() SwingUtilities.invokeLater { kanvas.createAndShowKanvasGUI() kanvas.addTab("My SM", languageSupport = smLangSupport) } |
и добавьте эти строки для поддержки вашего языка:
|
1
2
3
4
5
6
7
8
|
object smLangSupport : BaseLanguageSupport() { override val antlrLexerFactory: AntlrLexerFactory get() = object : AntlrLexerFactory { override fun create(code: String): Lexer = SMLexer(org.antlr.v4.runtime.ANTLRInputStream(code)) } override val parserData: ParserData? get() = ParserData(SMParser.ruleNames, SMParser.VOCABULARY, SMParser._ATN)} |
Это быстро. Менее 10 строк кода. Нам просто нужно указать классы Lexer и Parser (в этом примере SMLexer и SMParser ).
Если вам интересно, что это за язык, то это Kotlin: краткий статический язык для JVM, легко взаимодействующий с Java.
Давайте немного его улучшим: подсветка синтаксиса
Итак, у меня есть простой язык, я получаю редактор в основном бесплатно, и я начинаю его использовать. Прежде всего я хочу определить стиль для различных типов токенов. Мы делаем что-то простое, просто устанавливая цвета:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
object smLangSyntaxScheme : SyntaxScheme(true) { override fun getStyle(index: Int): Style { val style = Style() val color = when (index) { // Types SMLexer.STRING, SMLexer.INT, SMLexer.DECIMAL -> Color(42, 53, 114) // Literals SMLexer.STRINGLIT -> Color(21, 175, 36) SMLexer.INTLIT, SMLexer.DECLIT -> Color.BLUE // Comments SMLexer.COMMENT -> Color(170, 181, 171) // Operators SMLexer.ASTERISK, SMLexer.DIVISION, SMLexer.PLUS, SMLexer.MINUS -> Color.WHITE // Keywords SMLexer.VAR -> Color.GREEN SMLexer.INPUT -> Color(200, 250, 200) SMLexer.SM -> Color(200, 250, 200) SMLexer.EVENT -> Color(200, 250, 200) SMLexer.AS -> Color(50, 12, 96) // Identifiers SMLexer.ID -> Color.MAGENTA // Separators SMLexer.ARROW -> Color(50, 12, 96) SMLexer.COLON -> Color(50, 12, 96) SMLexer.ASSIGN -> Color(50, 12, 96) SMLexer.LPAREN, SMLexer.RPAREN -> Color.WHITE // Rest SMLexer.UNMATCHED -> Color.RED else -> null } if (color != null) { style.foreground = color } return style }} |
Мы не устанавливаем определенные токены жирным шрифтом или курсивом, потому что мы хотим, чтобы все было просто. Кстати, если вам интересно, как работает подсветка синтаксиса в Kanvas, я описал это в этом посте .
И тогда приходит автозаполнение
Теперь мы получаем ограниченное автозаполнение бесплатно. В основном мы получаем автозаполнение в зависимости от структуры языка, поэтому наш алгоритм может сказать нам, какие ключевые слова могут быть вставлены в текущую позицию или что в определенной позиции может быть принят идентификатор. То, что алгоритм не может не определить бесплатно, это то, какие идентификаторы должны предложить. Давайте реализуем очень простую логику: когда мы можем вставить идентификатор, мы смотрим на предыдущие токены и используем их, чтобы определить, какое предложение сделать. Например, при определении ввода мы могли бы предложить «anInput», а при определении переменной мы могли бы предложить «aVar»:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
override val propositionProvider: PropositionProvider get() = object : PropositionProvider { override fun fromTokenType(completionProvider: CompletionProvider, preecedingTokens: List<Token>, tokenType: Int): List<Completion> { val res = LinkedList<Completion>() var proposition : String? = this@smLangSupport.parserData!!.vocabulary.getLiteralName(tokenType) if (proposition != null) { if (proposition.startsWith("'") && proposition.endsWith("'")) { proposition = proposition.substring(1, proposition.length - 1) } res.add(BasicCompletion(completionProvider, proposition)) } else { when (tokenType) { SMParser.ID -> { val determiningToken = preecedingTokens.findLast { setOf(SMLexer.SM, SMLexer.VAR, SMLexer.EVENT, SMLexer.INPUT).contains(it.type) } val text = when (determiningToken?.type) { SMLexer.SM -> "aStateMachine" SMLexer.EVENT -> "anEvent" SMLexer.INPUT -> "aInput" SMLexer.VAR -> "aVar" else -> "someID" } res.add(BasicCompletion(completionProvider, text)) } } } return res } } |
Вот код Этого достаточно? Я не знаю, но я знаю, что эта система достаточно мала, чтобы быть понятной и достаточно простой, чтобы ее можно было легко расширять и настраивать. Поэтому я планирую использовать его для этого небольшого языка и по мере необходимости улучшать автозаполнение, особенно для этого языка. Органически и итеративно расти инструмент поддержки — это название игры.
Цели дизайна: что-то похожее на Sublime Text, но с открытым исходным кодом
Мы все любим Sublime Text. Я хотел бы, чтобы что-то вдохновило на это, но с открытым исходным кодом. Почему с открытым исходным кодом? Так что я могу настроить его так, как я хочу.
Вот как это выглядит сейчас:
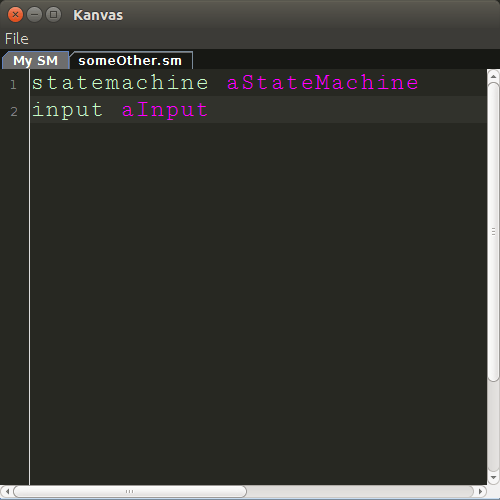
Да, это еще не так красиво, как Sublime Text. Но это значит, что у меня есть пространство для совершенствования.
Для Language Workbench или не для Language Workbench?
Я регулярно работаю с такими языковыми инструментами, как Jetbrains MPS и Xtext. Они великолепны, потому что позволяют очень быстро получить очень хорошую поддержку инструмента. Во многих ситуациях они являются вашим лучшим вариантом. Однако, как и у каждого инженерного решения, есть свои аспекты. Jetbrains MPS и Xtext — очень большие и сложные части программного обеспечения, такие, которые весят сотни МБ. Чтобы изучить внутренности этих платформ, требуется много работы и больших усилий. Вы можете получить огромную выгоду, просто используя эти платформы. Однако они не являются лучшим решением во всех ситуациях, потому что в некоторых ситуациях вам необходимо интегрировать свой язык с существующими системами, и, таким образом, вы должны согнуть эти языковые инструментальные средства так, как они не предназначены. Может быть, вы хотите встроить свой редактор или инструменты в существующую платформу, может быть, вам нужен простой редактор для использования на планшете, может быть, вы хотите использовать инструменты из командной строки. Может быть, вы хотите собрать систему вместе, чтобы она соответствовала вашим конкретным потребностям каким-то особым образом. В этих случаях использование Language Workbench — неправильный выбор. Вам нужно что-то простое, что-то взломанное. Это подход, который я экспериментирую. Для этого я работаю над несколькими проектами с открытым исходным кодом и пишу книгу .
Выводы
Будет ли это летать? Не знаю. Я с удовольствием провожу немного времени на этом проекте. И я чувствую, что это может быть хорошим подходом для получения простых автономных редакторов для DSL, созданных с помощью ANTLR. Я также хотел бы использовать его как своего рода Vim на базе Kotlin, VIM для нового тысячелетия. С супер-проекционной силой. Посмотрим, как это будет расти.
И да, я знаю, что Atom описывает себя как взломанный редактор. Но это не достаточно взломано с моей точки зрения.
| Ссылка: | Kanvas: создание простой IDE из вашей грамматики ANTLR от нашего партнера по JCG |