Содержание
Java наделена тремя большими структурами ведения журналов Java: ведение журнала Java Util, Log4j 2 и Logback. Когда вы выбирали один для своего проекта, вы когда-нибудь задумывались об их производительности? В конце концов, было бы глупо замедлять работу приложения только потому, что вы выбрали вялую структуру ведения журналов или неоптимальную конфигурацию.
Всякий раз, когда тема входа в Java появляется в Твиттере, вы можете быть уверены, что вас ждет много разглагольствования. Это, пожалуй, лучше всего изложено в этом твите от Дэна Аллена:
На самом деле есть довольно много людей, которым «повезло», чтобы остаться изолированными от вопроса входа в систему Java:
- Младшие разработчики, как правило, не уполномочены делать такой выбор.
- Промежуточные разработчики часто работают над базой кода, где выбор уже сделан.
- У старших разработчиков может быть выбор перед их техническим директором или другим лицом, принимающим решения.
Однако рано или поздно вы дойдете до того момента, когда вам придется выбирать каркас ведения журналов. В 2017 году мы можем разбить выбор на 4 варианта:
- Отказаться от выбора и использовать шайбу
- Используйте Java Util Logging .
- Используйте Log4j 2.x
- Использовать Logback
Вход Шимс
Если ты…
- разработка API
- разработка общей библиотеки
- разработка приложения, которое будет развернуто в среде выполнения, которая не входит в ваши обязанности (например, файл
.warили.earкоторый развертывается в контейнере общего приложения)
… Тогда выбор структуры ведения журнала не является вашей ответственностью, и вам следует использовать прокладку для ведения журнала.
Вам было бы прощено думать, что есть выбор:
- Apache Commons Logging
- SLF4J
Но API ведения журнала Apache Commons настолько прост и ограничен, что единственная рекомендация — Не используйте, если вы не хотите писать свои операторы ведения журналов следующим образом:
if (log.isDebugEnabled()) { log.debug("Applying widget id " + id + " flange color " + color); }
Рекомендация: SLF4J
Фреймворки
Если вы разрабатываете микросервис или какое-либо другое приложение, в котором у вас есть контроль над средой выполнения, вы, вероятно, несете ответственность за выбор инфраструктуры ведения журнала. Могут быть случаи, когда вы решите отложить выбор, используя прокладку, но вам все равно придется сделать выбор.
Переход от одного каркаса ведения журнала к другому — это, как правило, простой поиск и замена, или в худшем случае более сложный «структурный» поиск и замена, доступные в более продвинутых IDE. Если для вас важна производительность ведения журнала, API идиоматического ведения журнала инфраструктуры ведения журнала всегда будет превосходить оболочку, и, учитывая, что стоимость переключения ниже, чем при использовании других API, вам, вероятно, лучше кодировать непосредственно в среду ведения журнала.
Я должен также упомянуть, что есть философское различие между структурами:
- Java Util Logging пришла из школы мысли, что регистрация должна быть исключением, а не нормой.
- Log4j 2.x и Logback показывают свое общее наследие и при регистрации делают упор на производительность
Все три структуры представляют собой иерархические структуры ведения журналов, которые позволяют изменять конфигурацию во время выполнения и различные выходные места назначения. Чтобы запутать пользователей, разные структуры иногда используют разные термины для одних и тех же вещей, хотя:
-
HandlervsAppender— это одно и то же, помещая сообщение журнала в файл журнала. -
FormattervsLayout— это одно и то же, отвечающее за форматирование сообщения журнала в определенный макет.
Мы могли бы сравнить функции, но, на мой взгляд, единственная особенность, на которую стоит дифференцировать, — это сопоставленные диагностические контексты (MDC), поскольку все другие различия функций можно относительно легко кодировать. Сопоставленные диагностические контексты предоставляют способ дополнить сообщения журнала информацией, которая не была бы доступна для кода, в котором фактически происходит ведение журнала. Например, веб-приложение может внедрить запрашивающего пользователя и некоторые другие детали запроса в MDC, что позволяет любым инструкциям журнала в потоке обработки запросов включать эти детали.
В некоторых случаях отсутствие поддержки MDC может быть не столь важным, например:
- В архитектуре микросервиса нет общей JVM, поэтому вам необходимо встроить эквивалентные функциональные возможности в API-интерфейсы служб, обычно путем явной передачи состояния, которое будет в MDC.
- В однопользовательском приложении обычно существует только один контекст и, как правило, не так много параллелизма, поэтому потребность в MDC меньше.
Мы могли бы сравнить на основе простоты конфигурации. К сожалению, все три одинаково плохо документируют, как настроить вывод журнала. Ни один из них не предоставляет пример файла конфигурации «передового опыта» для общих случаев использования:
- Отправка журнала в файл журнала, с ротацией
- Отправка журналов в системы журналирования на уровне операционной системы, например, системный журнал, журнал событий Windows и т. Д.
Информация, как правило, присутствует, но скрыта в JavaDocs и составлена таким образом, что инженеру-программисту или операционному инженеру остается только задуматься, не нарушает ли конфигурация приложения.
Это оставляет нас с производительностью.
Производительность каркаса логирования
Хорошо, давайте тогда протестируем различные каркасы логирования. Есть много вещей, которые вы можете испортить, пытаясь написать микро-тесты на Java. Мудрый Java-инженер знает, как использовать JMH для микро-бенчмаркинга.
Одна из вещей, которая часто пропускается в тестах регистрации, является стоимостью не регистрации. В идеальном случае оператор регистрации для регистратора, который не собирается регистрировать, должен быть полностью исключен из пути кода выполнения. Одной из особенностей хорошей среды ведения журналов является возможность изменять уровни ведения журнала работающего приложения. В действительности нам нужна, по крайней мере, периодическая проверка на изменение уровня регистратора, поэтому мы не можем полностью исключить оператор регистрации.
Другим аспектом регистрации тестов является выборочная настройка. Каждая из различных структур ведения журналов имеет свою собственную конфигурацию вывода по умолчанию. Если мы не настроим все регистраторы на использование одного и того же формата вывода, мы не будем сравнивать подобное с аналогичным. И наоборот, некоторые каркасы журналирования могут иметь особые оптимизации, которые работают для определенных форматов журналирования, которые могут исказить результаты.
Итак, вот случаи, которые мы хотим проверить:
- ведение журнала настроено на отсутствие входа
- ведение журнала настроено для вывода в стиле ведения журнала Java Util по умолчанию
- протоколирование настроено для вывода в стиле Log4j 2.x по умолчанию
- протоколирование настроено для вывода в стиле Logback по умолчанию
Мы просто посмотрим на производительность записи журналов в файл скользящего журнала. Мы могли бы протестировать производительность таких вещей, как обработчики / дополнения системного журнала или вход в консоль, но существует риск того, что внешние системы (syslogd или терминал) могут поставить под угрозу некоторые дополнительные побочные эффекты.
Исходный код для тестов доступен на GitHub .
Структура эталона
Каждый тест по сути следующий:
@State(Scope.Thread) public class LoggingBenchmark { private static final Logger LOGGER = ...; private int i; @Benchmark public void benchmark() { LOGGER.info("Simple {} Param String", new Integer(i++)); } }
- Ссылка на регистратор сохраняется как статическое конечное поле.
- Каждый поток имеет независимое состояние
i. Это необходимо для предотвращения ложного совместного доступа к полю состояния. - Чтобы предотвратить оптимизацию конкатенации строк, параметр мутирует при каждом вызове метода сравнения.
- Конструкция с
new Integer(i++)необходима для противодействия кешу автобоксов . Посколькуiочень редко-128..127в диапазоне-128..127, нам нужно использовать явный бокс, поскольку неявныйInteger.valueOf(int)будет загрязнять результаты тестов проверкой кеша, и мы ожидаем, что кеш пропустит.
JMH предоставляет несколько различных режимов, в которых мы больше всего заинтересованы:
- Режим пропускной способности — который измеряет, сколько вызовов к целевому методу может быть выполнено в секунду. Чем выше, тем лучше.
- Примерный режим — который показывает, сколько времени занимает выполнение каждого вызова (включая процентили). Ниже — лучше.
Точка Строумана
При сравнительном анализе и сравнении различий между поставщиками иногда полезно знать, насколько далеко может быть достигнута производительность. По этой причине мои тесты содержат ряд различных реализаций. На графиках ниже я выбрал лучшего соломника для каждого сценария. Моя цель заключается в том, чтобы не оказывать влияние на производительность решений различных поставщиков. Моя цель — предоставить контекст, в котором мы можем сравнить производительность различных каркасов журналирования.
Мой трубочист показывает настолько высокую производительность, насколько я мог достичь, чтобы выполнить эквивалентную операцию. Стоимость этой более высокой производительности — потеря общей полезности. Однако, предоставляя соломенного чина, мы можем видеть, на что способна тестовая машина.
В качестве примера, соломенный работник для входа в никуда делает следующее:
- Устанавливает фоновый поток демона, который просыпается раз в секунду, и устанавливает
enabledполе на основании наличия файла, который не существует. - Каждый оператор журнала проверяет
enabledполе, и только если он равенtrue, он переходит в журнал.
Было бы просто иметь пустой оператор журнала, который даже не проверял бы enabled поле, но JVM включила бы этот пустой метод и полностью удалила ведение журнала. Если у нас не было фонового потока, периодически пишущего в поле (тот факт, что он всегда будет писать false , неизвестен JVM), то JVM могла бы заключить, что никто никогда не будет писать в это поле и вставлять результирующее постоянное условие. В данном случае соломенный мастер может повысить производительность, отбросив иерархическую конфигурацию.
Все другие реализации strawman должны писать сообщения журнала одинакового формата, а выигрыш в производительности достигается за счет жесткого кодирования средства форматирования / разметки журнала для таких вещей, как форматирование даты и конкатенация строк. Солдаты все разбирают параметризованное сообщение регистрации и форматируют это на лету, но без некоторых проверок безопасности структур.

Результаты тестов
Следующие версии были протестированы:
- Java 8 build 121
- Apache Log4J версия 2.7
- Logback версия 1.2.1
Вход в никуда
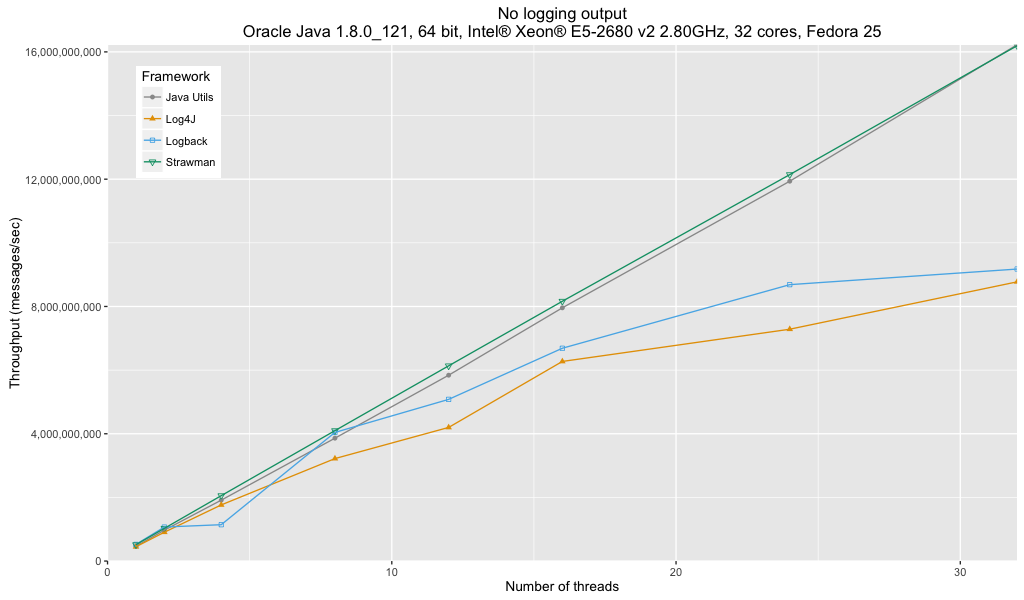
Глядя на график производительности, мы можем подумать, что нашли непосредственного победителя в Java Util Logging. Безусловно, пропускная способность, по-видимому, линейно масштабируется с количеством потоков, сразу за соломой, в то время как пропускная способность Log4J и Logback, похоже, падает с большим количеством потоков. Однако это является артефактом режима сравнительного анализа пропускной способности JMH.
Истинное сравнение фреймворков раскрывается при взгляде на количество времени, которое требуется для запуска метода тестирования, а не на количество операций в секунду.

Эти результаты практически не показывают различий в производительности всех трех платформ.
Выходной формат ведения журнала Java Util
Одним из интересных факторов формата по умолчанию Java Util Logging является то, что он включает в себя детали исходного класса и метода. Если вы хотите получить подробную информацию об исходном классе и методе, до Java 9 существует один и только один способ: создать исключение и выполнить трассировку стека. Будет интересно посмотреть, сможет ли новый API-интерфейс обходчика стека в Java 9 улучшить производительность.
Однако на момент написания этой статьи ни в Log4J, ни в Logback не был интегрирован предварительный API-интерфейс обходчика стека, поэтому было бы несправедливо сравнивать предварительные сборки Java 9 с другими платформами.
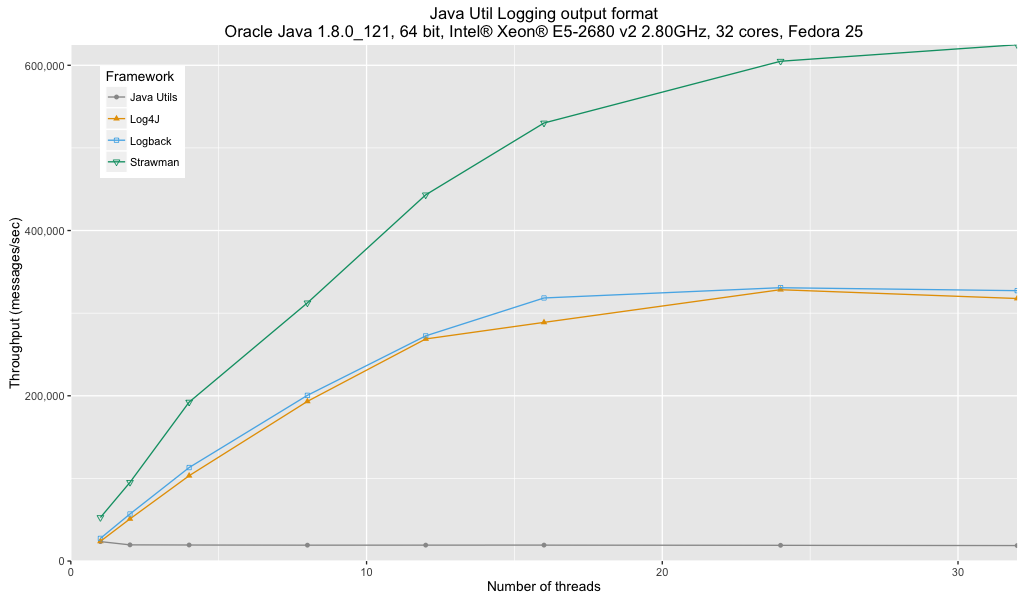
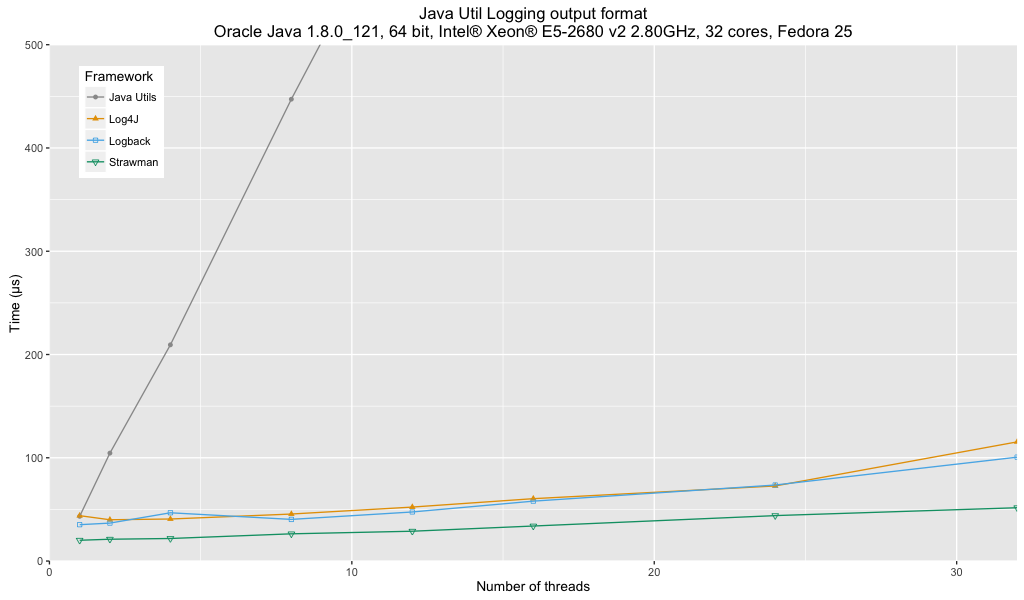
Анализ:
- На производительность ведения журнала Java Util существенное влияние оказывает отсутствие буферизованного обработчика.
- Нет большой разницы между Log4j и Logback.
- И Log4j, и Logback показывают около 50% производительности моего специального оптимизированного кейс-стомана.
Исходя из производительности, нельзя использовать Java Util Logging для этого выходного формата. Нет существенной разницы между Log4j и Logback с точки зрения производительности.
Потребуется тщательный анализ, чтобы определить, является ли разница в производительности по отношению к неработающему сотруднику результатом общей полезности структур ведения журналов или потенциальным источником дальнейшей оптимизации, которая была упущена.
Log4j 2.x Формат вывода по умолчанию
Log4j — это единственный формат, который можно легко настроить для всех каркасов журналирования. Мы используем его также для сравнения синхронных и асинхронных приложений.
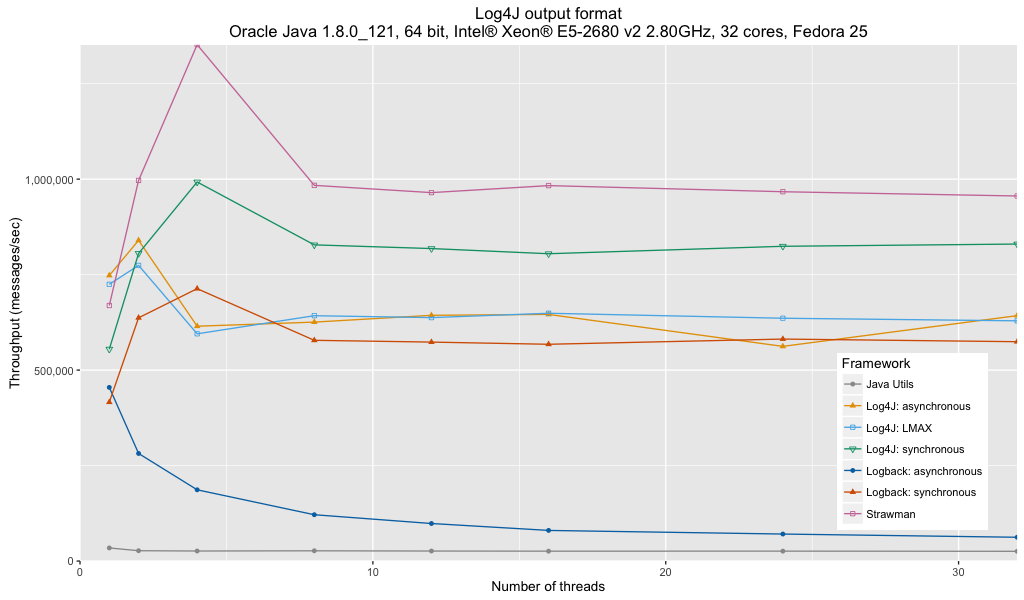

Анализ:
- На производительность ведения журнала Java Util существенное влияние оказывает отсутствие буферизованного обработчика.
- Асинхронное приложение Logback не рекомендуется для многопоточного ведения журнала из-за нерешенной ошибки в текущей реализации.
- Синхронный приложение Log4j является самым быстрым из всех фреймворков.
- Асинхронные приложения Log4j (с LMAX или без него) имеют примерно такую же пропускную способность, что и синхронные устройства Logback.
- Мой синхронный пользователь работает примерно на 10% быстрее синхронного приложения Log4j. Я подозреваю, что это стоимость общей полезности.
Выходной формат по умолчанию
Этот формат имеет тонкую причуду. Существует алгоритм аббревиатур, применяемый к имени регистратора. Только Logback имеет встроенную поддержку этого формата.
Это дает нам возможность использовать пользовательский форматер Java Util Logging, который позволит нам увидеть, откуда возникают некоторые проблемы с производительностью Java Util Logging. Чтобы максимизировать полезность сравнения, мы также включаем результаты других структур при использовании небуферизованного приложения.
Поскольку Log4J не поддерживает стиль сокращений имен регистратора в Logback, я заменил самые правые 36 символов имени регистратора в конфигурации Apache Log4J.
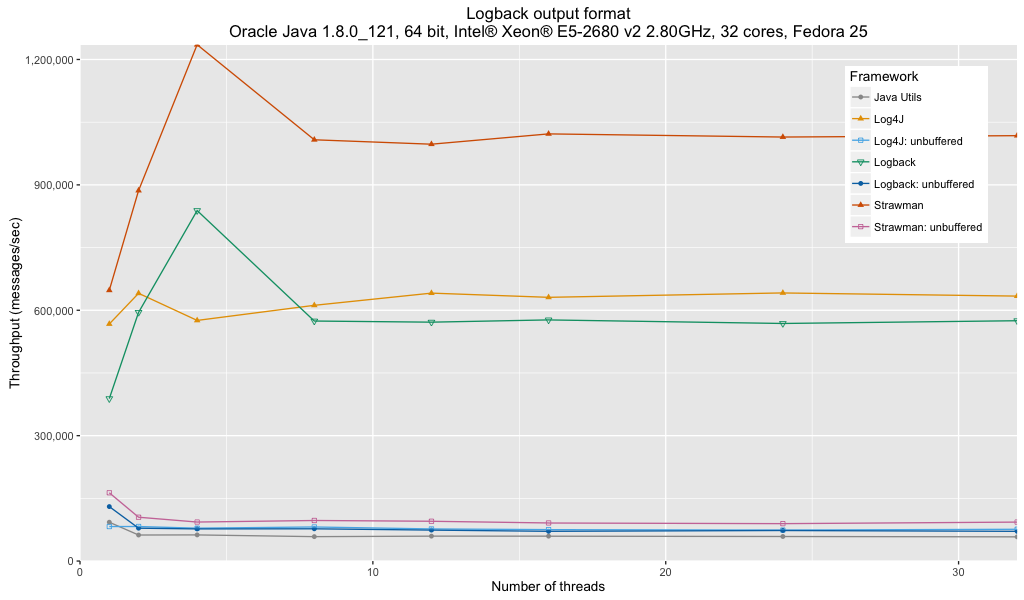
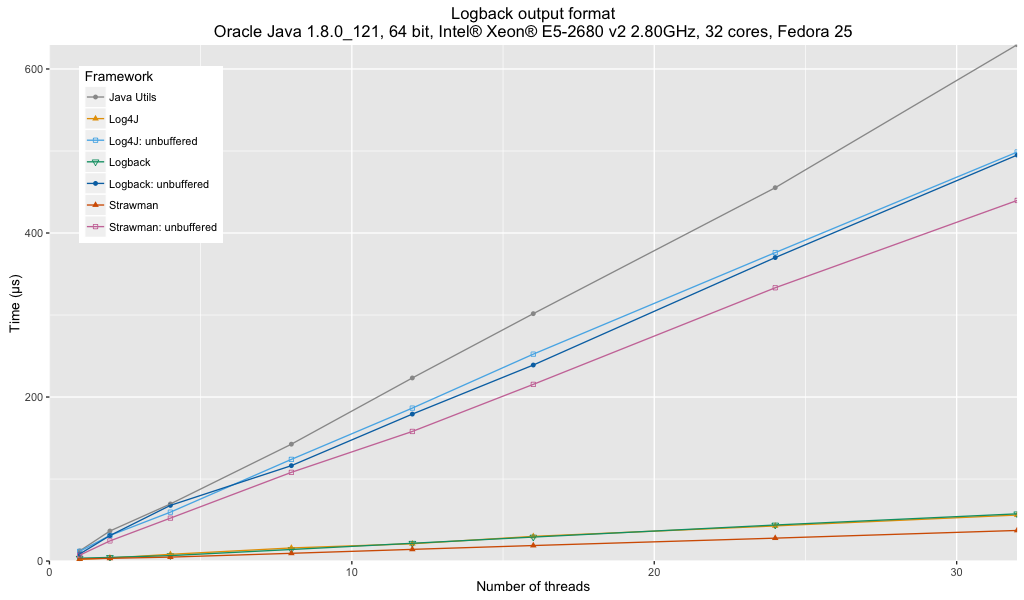
Анализ:
- В Java Util Logging используется пользовательский формат, который более оптимизирован и устраняет некоторые проблемы, связанные с Java Util Logging, приближая его к производительности других платформ при отсутствии буферизации. Производительность по-прежнему отстает от других систем.
- Использование небуферизованных обработчиков / добавщиков оказывает значительное влияние на пропускную способность логгера. Когда производительность журналирования критична, буферизованные регистраторы являются явным победителем.
- Производительность Log4j немного опережает Logback, но это может быть связано с более простым форматированием имени регистратора, с которым настроен Log4j.
- Производительность Log4j, Logback и буферизованных логгеров Strawman сопоставима с результатами формата Log4j.
Сообщение для разработчиков каркасов
Реальная проблема с регистрацией в Java заключается в настройке этих структур для вашего варианта использования. Потребовалось много копать, исследовать и экспериментировать, чтобы получить то, что я считаю эффективным и справедливым набором конфигураций для использования в качестве основы для сравнения. Я совершенно уверен, что некоторые разработчики каркасов журналирования будут не согласны с некоторыми аспектами моих конфигураций.
Если мы хотим продвинуть ведение журнала в Java, я бы рекомендовал в первую очередь совместные усилия по документированию. Помимо Java Util Logging, производительность достаточно близка к моим реализациям strawman, что либо указывает на то, что платформы ведения журналов Java очень производительны для общего служебного кода, либо я не могу написать быстрый одноцелевой код.
Каркасы журналирования должны предоставлять значительно лучшую документацию о том, как настроить регистрацию. В идеале они должны предоставлять примеры лучших конфигураций для входа в систему:
- консоль
- размер файла ограничен и будет катиться по крайней мере один раз в день
- системный журнал
Каждый из них имеет разные требования:
- Вход в консоль должен гарантировать, что журналы сбрасываются по крайней мере один раз каждые 100 мс, так что человек, наблюдающий журналы, воспринимает их в режиме реального времени. Кроме того, визуальное пространство должно быть максимально увеличено: опустить дату, сократить имена регистраторов и т. Д.
- Запись в файл должна гарантировать, что пространство, занимаемое журналами, ограничено. При поиске в файлах журналов определенного события с использованием инструментов командной строки может быть полезно, если указана дата. Точно так же визуальное пространство не совсем то же самое, поэтому сокращение имен регистраторов менее важно.
- Ведение журнала в системный журнал требует очень строгого формата, который может быть сложно настроить с использованием различных форматеров / макетов шаблонов.
Выводы
Ведение журнала Java Util не может быть рекомендовано в зависимости от производительности. Отсутствие реализации буферизованного обработчика оказывает существенное влияние на производительность ведения журнала.
При настройке ведения журнала возможность буферизовать файловый ввод-вывод является основным фактором, влияющим на производительность. Риск включения буферизации состоит в том, что операторы журнала непосредственно перед сбоем вашего процесса могут не записываться на диск, поэтому невозможно определить основную причину. Другая проблема, связанная с буферизацией, заключается в том, что из-за этого сложно создавать файлы журналов и следить за системой в режиме реального времени. Было бы неплохо, если бы различные структуры ведения журналов обеспечивали буферизацию с гарантированным максимальным временем до сброса. Обеспечение сброса один раз каждые 100 мсек не окажет такого же влияния на производительность системы, как сброс после каждого оператора журнала, и позволит людям следить за журналом с восприятием ведения журнала в реальном времени.
Эти тесты тестируют регистраторы под постоянной нагрузкой. Асинхронные регистраторы спроектированы так, чтобы обеспечить меньшую задержку для нечастого ведения журнала. При постоянной регистрации, где узким местом является файловый ввод-вывод, дополнительная работа по обмену событиями регистрации между различными потоками повлияет на общую пропускную способность. Таким образом, мы ожидаем и обнаруживаем, что асинхронные регистраторы показывают меньшую пропускную способность, чем синхронные регистраторы. Разработка эталонных тестов для демонстрации заявленных преимуществ асинхронных регистраторов не является тривиальной. Вы должны убедиться, что вывод журнала не ограничен файловым вводом / выводом, что потребует ограничения общей пропускной способности. JMH предназначен для измерения с максимальной пропускной способностью и, вероятно, не является подходящей платформой для сравнительного анализа, используемой для оценки заявленных преимуществ асинхронных регистраторов.
По сравнению с Java Util Logging, либо Logback, либо Log4j 2.x уничтожат слово, когда дело доходит до производительности. Синхронный регистратор Apache Log4J примерно на 25% быстрее, чем синхронный регистратор Logback, который в настоящее время дает ему небольшое преимущество. Я должен отметить, что версии Logback до 1.2.1 имеют значительно худшую производительность, так что это область конкуренции между фреймворками, и мои реализации, несомненно, определяют потенциальные возможности для улучшения в обеих фреймворках.