Системы с низкой задержкой требуют высокопроизводительной обработки и передачи сообщений. Поскольку в большинстве случаев данные должны передаваться по проводам или сериализироваться для сохранения, сообщения кодирования и декодирования становятся важной частью конвейера обработки. Наилучшие результаты при высокопроизводительном кодировании данных обычно включают применение знаний о специфике данных приложения. Методика, представленная в этой статье, является хорошим примером того, как использование некоторых аспектов кодирования данных дает преимущества как в задержке, так и в сложности пространства.
Обычно самые большие сообщения, передаваемые по высокочастотным торговым системам, представляют некоторое состояние обмена в форме выдержки из книги заказов. То есть типичное сообщение рыночных данных (тик) содержит информацию, идентифицирующую инструмент, и набор значений, представляющих верхнюю часть книги ордеров. Обязательным элементом набора данных является информация о цене / обменном курсе, выраженная в действительных числах (для сторон покупки и продажи).
Что делает этот набор данных очень интересным с точки зрения оптимизации, так это то, что он:
- монотонный
- низкий разброс
- неотрицательное *
Таким образом, на практике мы имеем дело с наборами чисел с плавающей запятой, которые не только сортируются (по возрастанию для предложения и по убыванию для запроса), но также имеют соседние значения, относительно «близкие» друг к другу. Помня о том, что задержка обработки сообщений имеет решающее значение для большинства торговых систем, рыночные тики, поскольку один из ключевых объектов должен пройти максимально эффективно.
Позвольте мне продемонстрировать, как все эти функции могут быть использованы для кодирования числовых данных в очень компактную двоичную форму. Во-первых, два тизера, демонстрирующих разницу между различными подходами сериализации:
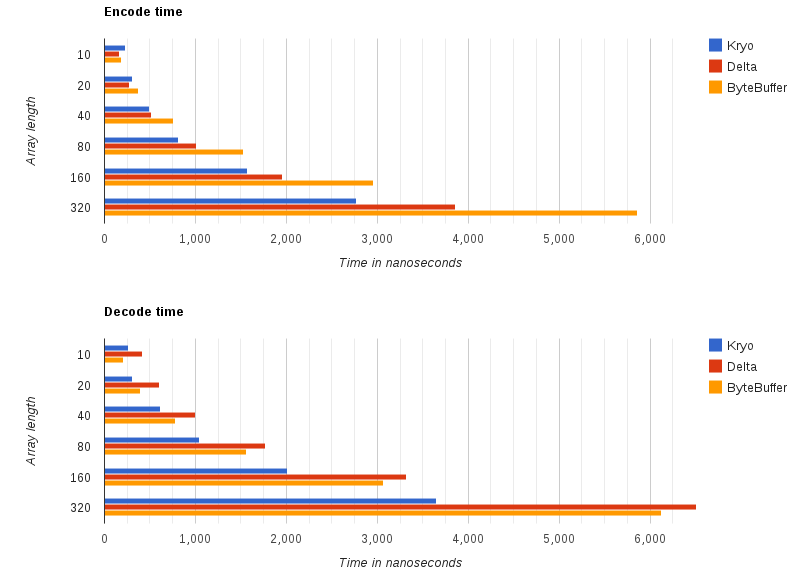
До сих пор мы видим, что дельта-кодирование дает лучшие результаты для времени кодирования по сравнению со стандартной сериализацией на основе ByteBuffer, но становится хуже, чем Kryo (одна из самых популярных высокопроизводительных библиотек сериализации), как только мы достигаем длины массива выше 40. здесь важен типичный сценарий использования, который для сообщений рынка высокочастотной торговли вписывается в диапазон 10-40 длин массивов
Это становится намного интереснее, когда мы исследуем размеры получаемых сообщений (как функцию длины массива):
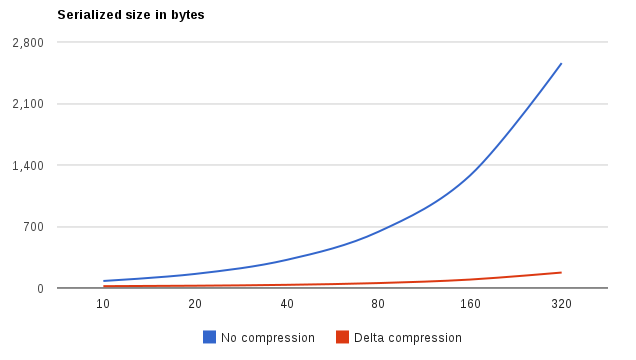
На этом этапе преимущества применения дельта-кодирования должны стать очевидными (эта синяя кривая в равной степени относится к сериализации байтового буфера и Kryo). Здесь происходит следующее: с некоторыми знаниями о специфике обрабатываемых данных можно с уверенностью сделать предположения, которые приведут к тому, что сериализация будет более ресурсоемкой, но смехотворно намного более эффективной в пространстве. Идея дельта-сжатия очень проста. Начнем с произвольного массива целых чисел:
- [85103, 85111, 85122, 85129, 85142, 85144, 85150, 85165, 85177]
Если бы это были целые числа, без какого-либо сжатия нам пришлось бы использовать 4 * 9 = 36 байт для хранения данных. Что особенно интересно в этом наборе чисел, так это то, что они сгруппированы относительно близко друг к другу. Мы могли бы легко уменьшить количество байтов, необходимых для хранения данных, ссылаясь на первое значение, а затем создать массив соответствующих дельт:
- Ссылка: 85103, [8, 19, 26, 39, 41, 47, 62, 74].
Вот Это Да! Теперь мы можем уменьшить массив байтов. Давайте сделаем расчеты снова. Нам нужно 4 байта для ссылочного значения (которое по-прежнему int) и 8 * 1 байт на дельту = 12 байтов.
Это довольно значительное улучшение по сравнению с первоначальными 36 байтами, но есть место для некоторой оптимизации. Вместо того, чтобы вычислять дельты по эталонному значению, давайте последовательно хранить различия для каждого предшественника:
- Ссылка: 85103, [8, 11, 7, 13, 2, 6, 15, 12]
В результате получается немонотонный набор чисел, характеризующийся низкой дисперсией и стандартным отклонением. Я надеюсь, что уже стало ясно, к чему это ведет. Тем не менее, стоит немного поработать.
На этом мы, по сути, и остановились на этом этапе — это набор, который является идеальным кандидатом для двоичного кодирования. Для нашего примера это просто означает, что можно разместить 2 дельты в одном байте. Нам нужен только клочок (4 бита) для размещения значений в диапазоне от 0 до 15, поэтому мы можем легко избежать конечного сжатия исходного массива в 4 (для справки) + 8 * 1/2 = 8 байтов.
Поскольку цены выражаются десятичными числами, применение дельта-сжатия с двоичным кодированием будет включать установление максимальной поддерживаемой точности и обработку десятичных чисел как интегралов (умножение их на точность 10 ^), делая 1.12345678 с точностью 6 целым числом 1123456. Пока что все это было чисто теоретическим предположением с некоторыми сюжетами в начале этой статьи. Я думаю, что сейчас подходящий момент, чтобы продемонстрировать, как эти идеи могут быть реализованы в Java с помощью двух очень простых классов.
Начнем со стороны кодирования:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
package eu.codearte.encoder;import java.nio.ByteBuffer;import static eu.codearte.encoder.Constants.*;public class BinaryDeltaEncoder { public static final int MAX_LENGTH_MASK = ~(1 << (LENGTH_BITS - 1)); public ByteBuffer buffer; public double[] doubles; public int[] deltas; public int deltaSize, multiplier, idx; public void encode(final double[] values, final int[] temp, final int precision, final ByteBuffer buf) { if (precision >= 1 << PRECISION_BITS) throw new IllegalArgumentException(); if ((values.length & MAX_LENGTH_MASK) != values.length) throw new IllegalArgumentException(); doubles = values; deltas = temp; buffer = buf; multiplier = Utils.pow(10, precision); calculateDeltaVector(); if (deltaSize > DELTA_SIZE_BITS) throw new IllegalArgumentException(); buffer.putLong((long) precision << (LENGTH_BITS + DELTA_SIZE_BITS) | (long) deltaSize << LENGTH_BITS | values.length); buffer.putLong(roundAndPromote(values[0])); idx = 1; encodeDeltas(); } private void calculateDeltaVector() { long maxDelta = 0, currentValue = roundAndPromote(doubles[0]); for (int i = 1; i < doubles.length; i++) { deltas[i] = (int) (-currentValue + (currentValue = roundAndPromote(doubles[i]))); if (deltas[i] > maxDelta) maxDelta = deltas[i]; } deltaSize = Long.SIZE - Long.numberOfLeadingZeros(maxDelta); } private void encodeDeltas() { if (idx >= doubles.length) return; final int remainingBits = (doubles.length - idx) * deltaSize; if (remainingBits >= Long.SIZE || deltaSize > Integer.SIZE) buffer.putLong(encodeBits(Long.SIZE)); else if (remainingBits >= Integer.SIZE || deltaSize > Short.SIZE) buffer.putInt((int) encodeBits(Integer.SIZE)); else if (remainingBits >= Short.SIZE || deltaSize > Byte.SIZE) buffer.putShort((short) encodeBits(Short.SIZE)); else buffer.put((byte) encodeBits(Byte.SIZE)); encodeDeltas(); } private long encodeBits(final int typeSize) { long bits = 0L; for (int pos = typeSize - deltaSize; pos >= 0 && idx < deltas.length; pos -= deltaSize) bits |= (long) deltas[idx++] << pos; return bits; } private long roundAndPromote(final double value) { return (long) (value * multiplier + .5d); }} |
Несколько слов вступительного объяснения, прежде чем углубляться в детали. Этот код не является полным, полностью продуманным решением; Его единственная цель — продемонстрировать, насколько легко улучшить некоторые биты протокола сериализации приложения. Так как он подвергается микробенчмаркингу, он также не вызывает давления gc только потому, что воздействие даже самого быстрого второстепенного gc может серьезно исказить конечные результаты, а следовательно, и уродливые API. Реализация также крайне неоптимальна, особенно в отношении процессора, но демонстрация микрооптимизации не является целью этой статьи. Сказав это, давайте посмотрим, что он делает (номера строк в фигурных скобках).
Метод Encode сначала выполняет некоторые фундаментальные проверки работоспособности {17,18}, вычисляет множитель, используемый при преобразовании десятичных чисел в интегралы {20}, и делегаты для вычисленияDeltaVector (). Это в свою очередь имеет два эффекта.
- Вычисляет скользящую дельту для всего набора путем преобразования десятичных дробей в интегралы, вычитания из предшественников и, наконец, сохранения результатов во временном массиве {33}
- В качестве побочного эффекта вырабатывается максимальное количество бит, необходимое для представления дельты {34,36}
Затем метод encode () сохраняет некоторые метаданные, необходимые для правильной десериализации. Он упаковывает точность, размер дельты в битах и длину массива в первые 64 бита {24}. Затем он сохраняет эталонное значение {25} и инициирует двоичное кодирование {27}.
Кодирование дельт делает следующее:
- Проверяет, обработал ли он уже все записи массива, и завершает работу, если так {40}
- Вычисляет количество оставшихся битов для кодирования {41}
- Выбирает наиболее подходящий тип (учитывая его размер в битах), кодирует оставшиеся биты и записывает биты в буфер {43-46}
- Рекурсы {47}
Последний бит, который, вероятно, требует некоторой проработки, — это сам метод encodeBits (). На основе размера типа (в битах), переданного в аргументе, он зацикливается на временном длинном, единственная цель которого состоит в том, чтобы служить набором битов, и записывает биты, представляющие последовательные дельты, перемещающиеся от самой младшей к младшей части длинного значения (определяется размер шрифта).
Декодирование, как и ожидалось, является полной противоположностью кодирования и главным образом связано с использованием метаданных для восстановления исходного массива удваивается до заданной точности:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
package eu.codearte.encoder;import java.nio.ByteBuffer;import static eu.codearte.encoder.Constants.DELTA_SIZE_BITS;import static eu.codearte.encoder.Constants.LENGTH_BITS;public class BinaryDeltaDecoder { private ByteBuffer buffer; private double[] doubles; private long current; private double divisor; private int deltaSize, length, mask; public void decode(final ByteBuffer buffer, final double[] doubles) { this.buffer = buffer; this.doubles = doubles; final long bits = this.buffer.getLong(); divisor = Math.pow(10, bits >>> (LENGTH_BITS + DELTA_SIZE_BITS)); deltaSize = (int) (bits >>> LENGTH_BITS) & 0x3FFFFFF; length = (int) (bits & 0xFFFFFFFF); doubles[0] = (current = this.buffer.getLong()) / divisor; mask = (1 << deltaSize) - 1; decodeDeltas(1); } private void decodeDeltas(final int idx) { if (idx == length) return; final int remainingBits = (length - idx) * deltaSize; if (remainingBits >= Long.SIZE) decodeBits(idx, buffer.getLong(), Long.SIZE); else if (remainingBits >= Integer.SIZE) decodeBits(idx, buffer.getInt(), Integer.SIZE); else if (remainingBits >= Short.SIZE) decodeBits(idx, buffer.getShort(), Short.SIZE); else decodeBits(idx, buffer.get(), Byte.SIZE); } private void decodeBits(int idx, final long bits, final int typeSize) { for (int offset = typeSize - deltaSize; offset >= 0 && idx < length; offset -= deltaSize) doubles[idx++] = (current += ((bits >>> offset) & mask)) / divisor; decodeDeltas(idx); }} |
Исходный код с некоторыми тестовыми классами можно найти здесь . Пожалуйста, имейте в виду, несмотря на то, что доказано, что этот код, безусловно, не готов к работе. Вы определенно можете заставить его работать, не требуя временного массива, заменив полное сканирование массива при вычислении максимального размера дельты чем-то умным, или уйдите без этого тяжелого деления, выполнив деление по обратной аппроксимации. Не стесняйтесь подбирать эти подсказки или применять различные микрооптимизации и создавать собственный проприетарный протокол дельта-кодирования. Это имеет огромное значение для чувствительных к латентности торговых приложений, уменьшая размер сообщений рыночных данных для ликвидных инструментов в 20-30 раз. Конечно, вы должны выяснить сами, если переключение на двоичное кодирование с дельта-сжатием приносит какую-то ценность для вашей прикладной экосистемы. Не стесняйтесь оставлять комментарии со своими результатами!