Некоторое время назад я писал, как реализовать реактивную очередь сообщений с помощью Akka Streams . Очередь поддерживает потоковые операции отправки и получения с обратным давлением, но имеет один недостаток: все сообщения хранятся в памяти и, следовательно, в случае перезапуска теряются.
Но это можно легко решить с помощью экспериментального akka-persistence , который только что получил обновление в Akka 2.3.4 .
Очередь актера-переподготовки
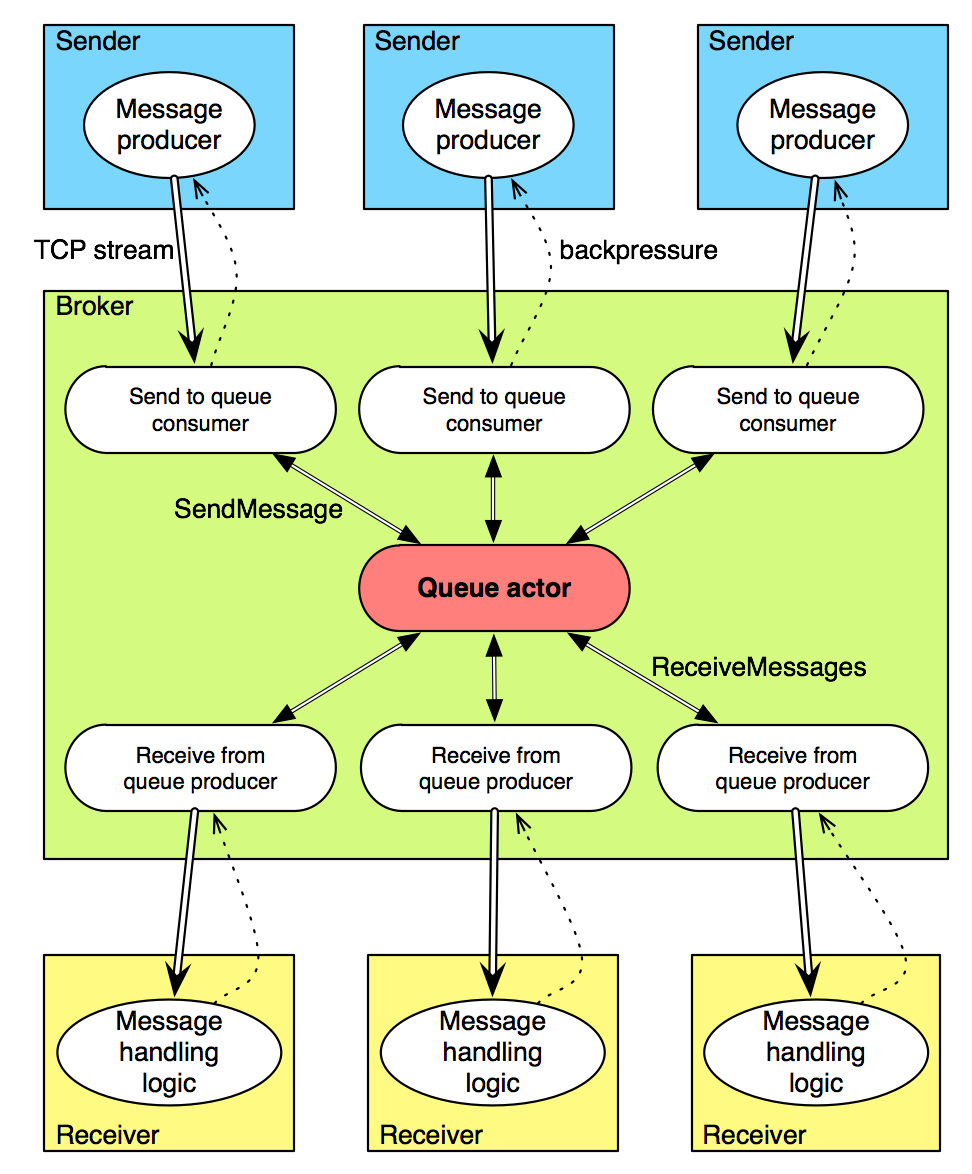
Чтобы сделать очередь долговечной, нам нужно только изменить действующего субъекта; реактивные / потоковые части остаются нетронутыми. Как напоминание, реактивная очередь состоит из:
- один субъект очереди , который содержит внутреннюю очередь сообщений, подлежащих доставке. Участник очереди принимает сообщения субъекта для отправки, получения и удаления сообщений очереди
- брокер , который создает субъект очереди, прослушивает соединения от отправителей и получателей и создает реактивные потоки, когда соединение установлено
- Отправитель , который отправляет сообщения в очередь (для тестирования — одно сообщение каждую секунду). Несколько отправителей могут быть запущены. Сообщения отправляются только в том случае, если они могут быть приняты (обратное давление со стороны брокера)
- получатель , который получает сообщения из очереди по мере их поступления и обработки (обратное давление со стороны получателя).
Идти настойчиво (оставаясь реактивным)
Необходимые изменения весьма минимальны.
Прежде всего, QueueActor должен расширить PersistentActor и определить два метода:
-
receiveCommand, который определяет «нормальное» поведение, когда поступают сообщения актера (команды) -
receiveRecover, который используется только во время восстановления и куда отправляются события воспроизведения
Но для того, чтобы выздороветь, сначала нужно сохранить некоторые события! Это, конечно, должно быть сделано при обработке операций очереди сообщений.
Например, при отправке сообщения событие MessageAdded сохраняется с использованием persistAsync :
|
01
02
03
04
05
06
07
08
09
10
|
def handleQueueMsg: Receive = { case SendMessage(content) => val msg = sendMessage(content) persistAsync(msg.toMessageAdded) { msgAdded => sender() ! SentMessage(msgAdded.id) tryReply() } // ...} |
persistAsync — это один из способов сохранения событий с использованием akka-persistence. Другой, persist (который также является значением по умолчанию), буферизует последующие команды (сообщения актера), пока событие не будет сохранено; это немного медленнее, но также легче рассуждать и оставаться последовательным. Однако в случае очереди сообщений такое поведение не является необходимым. Единственная гарантия, что нам нужно, это то, что отправка сообщения подтверждается только после того, как событие сохраняется; и именно поэтому ответ отправляется в обработчик событий after-persist. Вы можете прочитать больше о persistAsync в документации .
Аналогично, события сохраняются для других команд (сообщения- QueueActorReceive , см. QueueActorReceive ). И для удаления, и для получения мы используем persistAsync , так как цель состоит в том, чтобы обеспечить как минимум однократную гарантию доставки.
Последний компонент — это обработчик восстановления, который определяется в QueueActorRecover (а затем используется в QueueActor ). Восстановление довольно просто: события соответствуют добавлению нового сообщения, обновлению временной метки «следующая доставка» или удалению.
Внутреннее представление использует как очередь с приоритетами, так и карту по идентификатору для эффективности, поэтому, когда события обрабатываются во время повторного преобразования, мы только строим карту и используем специальное событие RecoveryCompleted для построения очереди. Специальное событие отправляется akka-persistence автоматически.
И это все! Если вы сейчас запустите посредника, отправите несколько сообщений, остановите посредника, запустите его снова, вы увидите, что сообщения восстановлены, и, действительно, они будут получены, если получатель запущен.
Конечно, код не готов к работе. Журнал событий будет постоянно расти, поэтому было бы целесообразно использовать моментальные снимки , а также удалять старые события / моментальные снимки, чтобы уменьшить размер хранилища и ускорить восстановление.
копирование
Теперь, когда очередь долговечна, мы также можем иметь реплицированную постоянную очередь почти бесплатно: нам просто нужно использовать другой плагин журнала ! По умолчанию используется LevelDB и записывает данные на локальный диск. Доступны другие реализации: для Cassandra , HBase и Mongo .
Делая простое переключение бэкэнда персистентности, мы можем реплицировать наши сообщения в кластере.
Резюме
С помощью двух экспериментальных модулей Akka, реактивных потоков и персистентности , мы смогли создать долговременную реактивную очередь с минимальным количеством кода. И это только начало, так как две технологии только начинают развиваться!
- Если вы хотите изменить / разветвить код, он доступен на Github .
| Ссылка: | Создание долговременной Реактивной очереди с помощью Akka Persistence от нашего партнера по JCG Адама Варски в |