Вы когда-нибудь слышали: «Нам действительно нравится ваш продукт … за исключением нескольких мелких деталей».? А затем ИТ-директор выдает список дополнительных «обязательных» требований, сотни из которых, чтобы добавить к вашему удивительному продукту. Вы когда-нибудь слышали или даже говорили: «Команда, мы собираемся подписать очень выгодный контракт, но…»? И тогда список пожеланий заказчика для дополнительной функциональности становится головной болью для разработчиков.
 Итак, как сохранить продукт в шаге от потенциально опасных идей ваших клиентов, но при этом удовлетворить их? Как можно поддерживать наивысший уровень производительности для продукта, технически предназначенного для работы определенным образом, но теперь со слоем многочисленных надстроек? Какую сложность вызовет фундаментальная необходимость обеспечить надежную и выдающуюся поддержку разработанного решения?
Итак, как сохранить продукт в шаге от потенциально опасных идей ваших клиентов, но при этом удовлетворить их? Как можно поддерживать наивысший уровень производительности для продукта, технически предназначенного для работы определенным образом, но теперь со слоем многочисленных надстроек? Какую сложность вызовет фундаментальная необходимость обеспечить надежную и выдающуюся поддержку разработанного решения?
В коммерческом мире настройка продукта становится все более желательным требованием, и ряд общепринятых практик развился в ответ на эту потребность клиента. Ниже вы можете найти обзор типичных подходов; если вы уже знакомы с ними, тогда вы можете прокрутить страницу « Подход к расширениям » и узнать, как мы решаем эти проблемы более эффективно.
Все в одном
Наиболее простое и очевидное решение для настройки состоит в том, чтобы реализовать все необходимое в одном базовом продукте, а затем использовать технику « переключения функций » для соответствия требованиям каждого конкретного клиента.
Основным преимуществом подхода «все в одном» является сохранение монолитного продукта, который, по-видимому, является хорошим способом для определенных типов продуктов, которые обычно соответствуют бизнес-требованиям без необходимости обширной настройки.
Естественное ограничение этого подхода скрыто в предположении «не требуется много настроек». Зачастую разработка продукта начинается с этого убеждения, но после ряда поставок вы понимаете истинный масштаб того, сколько требуется для конкретного клиента. Нередко быть пойманным на рогах дилеммы; отказаться от пользовательской разработки и потенциально потерять клиентов или превратить исходный код в мусорное ведро с функциями, специфичными для одного клиента, которые, вероятно, будут бесполезны для большинства конечных пользователей.
Какой вариант вы бы выбрали? Очевидно, что выбор между камнем и наковальней — не путь к успеху.
Резюме: подход «все в одном» может быть подходящим выбором, только если вы уверены, что потребуются редкие и ограниченные настройки. В противном случае вы столкнетесь с выбором между управляемым и поддерживаемым продуктом и удовлетворенностью клиентов. Позвольте мне процитировать Джерри Гарсиа, который сказал: «Постоянный выбор меньшего из двух зол по-прежнему выбирает зло».
разветвление
Если значительная настройка является обязательной частью поставки, то метод « все в одном» не может быть использован. Есть еще один простой подход — ветвление . Вы просто разветвляете кодовую базу продукта и изменяете что-либо отдельно.
Сравнивая ветвление с All in One , самое большое преимущество состоит в том, что нет никаких ограничений, применимых к области настройки. Вы используете отдельные ветви для удовлетворения специфических требований разных клиентов и избегаете смешивания всех функций в одной кодовой базе.
Однако есть и обратная сторона, которая может зайти в тупик с точки зрения эволюции продукта. Очевидно, что отрасль продукта является основным пространством разработки: большинство исправлений, улучшений, новых функциональных возможностей сначала распространяются на продукт. Таким образом, частое объединение необходимо для синхронизации всех настроенных веток с основным продуктом. Слияние — это простая операция, если настраиваемая ветвь не затрагивает исходный код продукта, в противном случае она становится чрезвычайно трудоемкой и может привести к неизбежным ошибкам регрессии.
Этот подход все еще может работать, если вы ограничены несколькими настроенными ветками. Тем не менее, по мере того как число доставленных экземпляров растет, вероятность столкновения с «пыткой слиянием» становится неизбежной.
Резюме: Подход ветвления, несомненно, очень гибкий и простой — любая часть продукта может быть изменена. Однако этап после доставки потенциально очень трудоемкий, со временем становится более трудным, и вряд ли это приведет к созданию значительного числа управляемых настраиваемых филиалов.
Модель Entity-Attribute-Value
Модель Entity-Attribute-Value ( модель объекта-атрибута-значения, вертикальная модель базы данных и открытая схема) является хорошо известной и широко используемой моделью данных. EAV обеспечивает поддержку динамических атрибутов сущностей и обычно используется параллельно со стандартной реляционной моделью.
С точки зрения продуктизации главное преимущество использования EAV заключается в том, что вы можете предоставить продукт «как есть», а затем настроить модель данных, добавив необходимые атрибуты во время выполнения, поддерживая чистоту исходного кода.
Как всегда, есть и обратная сторона:
- Ограниченная применимость — модель EAV ограничена только возможностью добавления атрибутов к объектам, которые затем будут автоматически встраиваться в пользовательский интерфейс в соответствии с предварительно запрограммированной логикой.
- Дополнительная нагрузка на сервер базы данных. Вертикальный дизайн базы данных часто становится узким местом для корпоративных приложений, которые обычно работают с большим количеством объектов и связанных с ними атрибутов.
- Наконец, корпоративные системы невозможно представить без наличия сложного механизма отчетности. Модель EAV потенциально может привести к многочисленным осложнениям из-за своей «вертикальной» структуры базы данных.
Описание: Модель Entity-Attribute-Value имеет большое значение в определенных ситуациях, например, когда необходимо обеспечить гибкость, достигаемую благодаря наличию дополнительных информативных данных, которые явно не используются в бизнес-логике. Другими словами, EAV хорош в умеренности, например, в дополнение к стандартной реляционной модели и архитектуре плагинов .
Плагин Архитектура
Архитектура плагинов является одним из самых популярных и мощных подходов, где функциональная логика хранится в виде отдельных артефактов, известных как плагины. Чтобы переопределить существующее готовое поведение и запустить плагины, необходимо определить «Точки настройки» (также называемые Точки расширения) в исходном коде продукта. «Точка настройки» — это определенное место в исходном коде, где приложение перелистывает подключенные плагины, чтобы проверить, содержит ли плагин переопределенную реализацию, которая будет запущена здесь. Одним из вариантов архитектуры плагина является внешний сценарий; когда функциональная реализация реализована и хранится извне как скрипт. Вызов скрипта также контролируется предопределенными «точками настройки».
Используя этот подход к подключаемым модулям, можно поддерживать продукт в чистоте от конкретных требований заказчика, предоставлять основной продукт «как есть» и настраивать поведение в соответствии с требованиями подключаемых модулей или сценариев. Еще одним преимуществом этого подхода является хорошо управляемая процедура обновления. Полное разделение функциональности продукта и плагина позволяет обновлять их независимо друг от друга.
Конечно, существуют ограничения: главное ограничение состоит в том, что невозможно полностью знать, какие пользовательские требования могут быть повышены в будущем. Следовательно, можно только догадываться, куда следует встраивать «точки настройки». Конечно, они могут быть разбросаны повсеместно в качестве смягчающего плана «на всякий случай», но это приведет к плохой читаемости кода, сложной отладке и дополнительной сложной поддержке.
Описание: архитектура плагина работает, если «точки настройки» легко предсказать, но помните, что настройка между «точками настройки» невозможна.
Подход расширений
Мы реализовали уникальный подход в нашей корпоративной платформе разработки программного обеспечения CUBA . Как было сказано в нашей предыдущей статье , CUBA — очень практичный, живой организм, созданный в процессе эволюции, управляемой разработчиком. Итак, основываясь на нашем обширном опыте готовых продуктов, мы пришли к двум основным требованиям:
- Клиентский код должен быть полностью отделен от основного кода продукта
- Каждая часть кода продукта должна быть доступна для модификации
Нам удалось удовлетворить эти требования и добиться еще большего с помощью нашего механизма «Расширения».
CUBA Extensions
Расширение — это отдельный проект CUBA, который наследует все функции базового проекта (т.е. вашего основного продукта), используя его в качестве библиотеки. Это, очевидно, позволяет разработчикам реализовать совершенно новую функциональность, не затрагивая родительский проект, но благодаря использованию шаблона Open Inheritance и специальных возможностей CUBA вы также можете переопределить любую часть родительского проекта. Таким образом, расширение — это место, где вы реализуете сотни «мелких деталей», которые обсуждались в начале этой статьи.
Фактически, каждый проект CUBA является расширением самой платформы CUBA, поэтому он может переопределить любую функцию платформы. Мы приняли этот подход сами, чтобы отделить некоторые базовые функции (полнотекстовый поиск, отчеты, графики и т. Д.) От базовой платформы. Так что если они вам нужны в вашем проекте, вы просто добавляете их как родительские проекты — вот и все, своего рода множественное наследование!
Таким же образом вы можете построить иерархическую модель настройки . Это может показаться сложным, но это имеет смысл. Позвольте мне привести пример из реальной жизни: Шерлок — это полное решение по управлению такси от Haulmont , поддерживающее все аспекты управления бизнесом такси, от бронирования и отправки до приложений и выставления счетов. Решение охватывает множество различных аспектов бизнеса клиентов, и многие из них связаны с местоположением. Например, все британские компании такси имеют одинаковые правовые нормы, но многие из них не применимы к США, и наоборот. Очевидно, что мы не хотим внедрять все эти правила в основной продукт, потому что:
- это особенность области действия
- местные правила могут иметь совершенно разные последствия для операций парка такси в разных странах
- некоторые клиенты вообще не требуют регулирующего контроля
Итак, мы организуем иерархию многоуровневых расширений:
- Основной продукт содержит общие характеристики бизнеса такси
- Первый уровень настройки реализует региональную специфику
- Второй уровень настройки охватывает список пожеланий клиента (если он есть!)
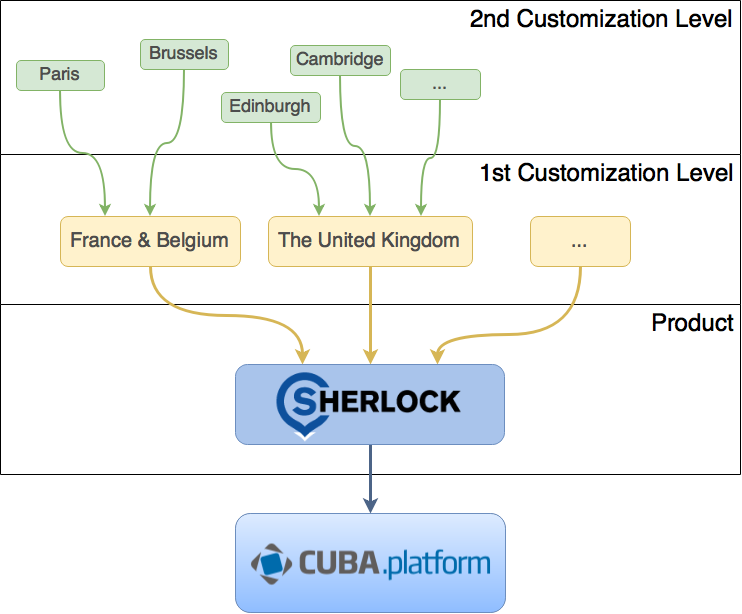
Чисто и понятно.
Как видите, с помощью расширений вам не нужно ни разветвляться, ни интегрировать все требования в основной продукт, код остается чистым и управляемым. Это звучит слишком хорошо, чтобы быть правдой, поэтому давайте посмотрим, как это работает на практике!
Добавление нового атрибута в существующую сущность
Давайте предположим, что у нас есть определение продукта объекта « Пользователь», которое состоит из двух полей: логин и пароль:
|
01
02
03
04
05
06
07
08
09
10
11
|
@Entity(name = "product$User")@Table(name = "PRODUCT_USER")public class User extends StandardEntity { @Column(name = "LOGIN") protected String login; @Column(name = "PASSWORD") protected String password; //getters and setters} |
Теперь у некоторых из наших клиентов есть дополнительное требование добавить пользователям поле «домашний адрес». Для этого мы расширяем сущность User в расширении:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
@Entity(name = "ext$User")@Extends(User.class)public class ExtUser extends User { @Column(name = "ADDRESS", length = 100) private String address; public String getAddress() { return address; } public void setAddress(String address) { this.address = address; }} |
Как вы, возможно, уже заметили, все аннотации, кроме @Extends, являются обычными аннотациями JPA. Атрибут @Extends является частью механизма CUBA, который глобально заменяет сущность User на ExtUser , даже в зависимости от функциональности продукта.
Используя атрибут @Extends, мы заставляем платформу:
- всегда создавайте сущность типа «последний ребенок»
|
1
|
User user = metadata.create(User.class); //ExtUser entity will be created |
- преобразовать все JPQL-запросы перед выполнением, чтобы они всегда возвращали «последний дочерний набор»
|
1
|
select u from product$User u where u.name = :name //returns a list of ExtUsers |
- всегда используйте «последний ребенок» в связанных объектах
|
1
|
userSession.getUser(); //returns an instance of ExtUser type |
Другими словами, если объявлена расширенная сущность, базовая сущность отбрасывается по всему решению (продукт и расширение) и глобально переопределяется расширенной.
Настройка экранов
Итак, мы расширили сущность User , добавив атрибут адреса, и теперь хотим, чтобы изменения были отражены в пользовательском интерфейсе. Во-первых, давайте взглянем на оригинальную (экранную) декларацию экрана:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
<window datasource="userDs" caption="msg://caption" class="com.haulmont.cuba.gui.app.security.user.edit.UserEditor" messagesPack="com.haulmont.cuba.gui.app.security.user.edit" > <dsContext> <datasource id="userDs" class="com.haulmont.cuba.security.entity.User" view="user.edit"> </datasource> </dsContext> <layout> <fieldGroup id="fieldGroup" datasource="userDs"> <column> <field id="login"/> <field id="password"/> </column> </fieldGroup> <iframe id="windowActions" screen="editWindowActions"/> </layout> </window> |
Как видите, экранный дескриптор CUBA представлен в виде обычного XML. Очевидно, что мы могли бы просто повторно объявить весь дескриптор экрана в расширении, но это означало бы вставку копии большей части. В результате, если что-то изменится на экране продукта в будущем, нам придется скопировать эти изменения на экран расширения вручную. Чтобы избежать этого, CUBA вводит механизм наследования экрана, и все, что вам нужно, это описать изменения на экране:
|
1
2
3
4
5
6
7
8
9
|
<window extends="/com/haulmont/cuba/gui/app/security/user/edit/user-edit.xml"> <layout> <fieldGroup id="fieldGroup"> <column> <field id="address"/> </column> </fieldGroup> </layout> </window> |
Вы определяете экран предка с помощью атрибута extends и описываете только объект, подлежащий изменению.
Вот, пожалуйста! Давайте наконец посмотрим на результат:
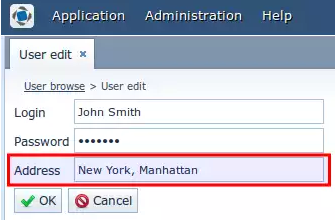
Модификация бизнес-логики
Чтобы включить модификацию бизнес-логики, платформа CUBA использует Spring Framework, который является основной частью инфраструктуры платформы.
Например, у вас есть компонент промежуточного программного обеспечения для выполнения процедуры расчета цены:
|
1
2
3
4
5
6
|
@ManagedBean("product_PriceCalculator")public class PriceCalculator { public void BigDecimal calculatePrice() { //price calculation }} |
Чтобы отменить реализацию расчета цены, нам нужно выполнить только два простых действия.
Сначала расширьте класс продукта и переопределите соответствующую процедуру:
|
1
2
3
4
5
6
|
public class ExtPriceCalculator extends PriceCalcuator { @Override public void BigDecimal calculatePrice() { //modified logic goes here }} |
И, наконец, зарегистрируйте новый класс в конфигурации Spring, используя идентификатор компонента продукта:
|
1
|
<bean id="product_PriceCalculator" class="com.sample.extension.core.ExtPriceCalculator"/> |
Теперь инъекция PriceCalculator всегда будет возвращать экземпляр расширенного класса. Следовательно, измененная реализация будет использоваться во всем продукте.
Обновление базовой версии продукта в расширении
По мере развития основного продукта и выпуска новых версий вы в конечном итоге решите обновить свое расширение до последней версии продукта. Процесс довольно прост:
- Укажите новую версию базового продукта в расширении.
- Перестройте расширение:
- Если расширение построено на стабильных частях API продукта, оно готово к работе.
- Если произошли некоторые существенные модификации API продукта, и эти модификации перекрывают настройку, реализованную в расширении, необходимо будет поддерживать новый API продукта в расширении.
В большинстве случаев API продукта существенно не меняется от обновления к обновлению, особенно в небольших версиях. Но даже если происходит «большой взрыв» API, продукт обычно сохраняет совместимость с предыдущими версиями, по крайней мере, для пары будущих версий, а старая реализация помечается как «устаревшая», что позволяет перенести все расширения в новейший API.
Вывод
В качестве краткого резюме я хотел бы проиллюстрировать результаты сравнительного анализа в виде таблицы:
| Все в одном | разветвление | EAV | Плагины | CUBA Extensions | |
| Независимая архитектура | + | + | — | — | — |
| Динамическая настройка | — | — | + | +/- | — |
| Настройка бизнес-логики | + | + | — | +/- | + |
| Настройка модели данных | + | + | + | +/- | + |
| Настройка пользовательского интерфейса | + | + | +/- | +/- | + |
| Качество кода и читаемость | — | +/- | +/- | +/- | + |
| Не влияет на производительность | + | + | — | + | + |
| Риск регрессии программного обеспечения | Высокий | Высокий | Низкий | средний | средний |
| Сложность долгосрочной поддержки | экстремальный | экстремальный | Низкий | средний | средний |
| Масштабируемость | Низкий | Низкий | Высокий | Высокий | Высокий |
Как вы можете видеть, подход «Расширение» является мощным, но ему не хватает одной возможности — точной настройки системы на лету (динамически настраиваемой). Чтобы преодолеть это, CUBA также предоставляет полную поддержку модели Entity-Attribute-Value и подхода Plugin / Scripting .
Я надеюсь, что вы найдете этот обзор полезным и, конечно, ваши отзывы очень ценятся.