Вступление
В моем предыдущем посте я представил READ_ONLY CacheConcurrencyStrategy , который является очевидным выбором для графов неизменяемых сущностей. Когда кэшируемые данные изменяемы, нам нужно использовать стратегию кэширования чтения-записи, и в этом посте будет описано, как работает кэш второго уровня NONSTRICT_READ_WRITE .
Внутренние работы
Когда транзакция Hibernate зафиксирована, выполняется следующая последовательность операций:
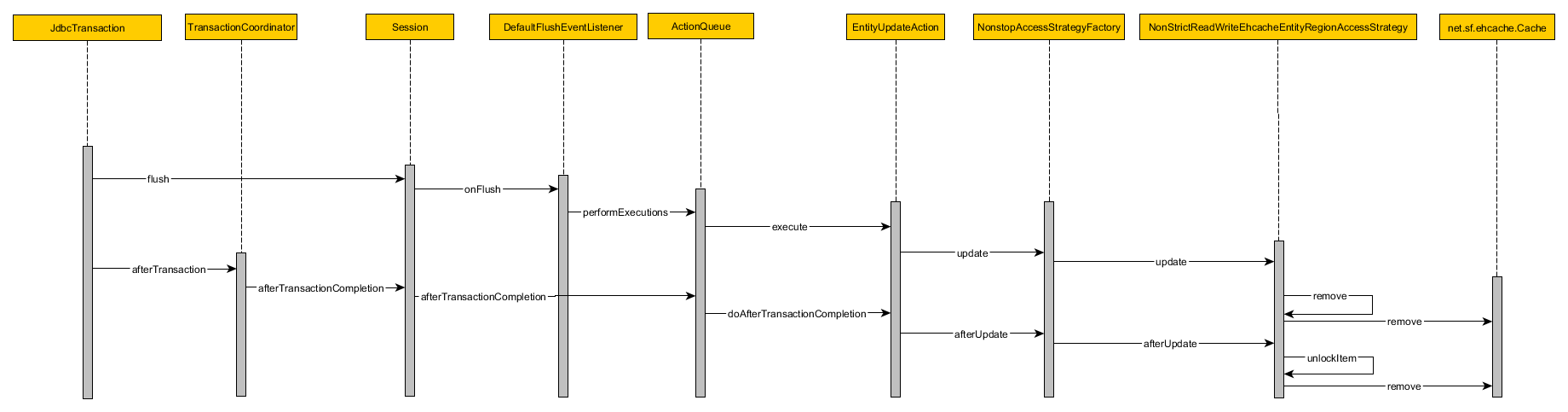
Во-первых, кэш становится недействительным до того, как транзакция базы данных будет зафиксирована во время сброса:
- Текущая транзакция гибернации (например, JdbcTransaction , JtaTransaction ) сбрасывается
- DefaultFlushEventListener выполняет текущий ActionQueue
- EntityUpdateAction вызывает метод обновления EntityRegionAccessStrategy
- NonStrictReadWriteEhcacheCollectionRegionAccessStrategy удаляет запись кэша из базового EhcacheEntityRegion
После фиксации транзакции базы данных запись в кэше еще раз удаляется:
- Текущая транзакция Hibernate после завершения обратного вызова называется
- Текущий сеанс распространяет это событие на свой внутренний ActionQueue
- EntityUpdateAction вызывает метод afterUpdate для EntityRegionAccessStrategy
- NonStrictReadWriteEhcacheCollectionRegionAccessStrategy вызывает метод удаления базового EhcacheEntityRegion
Предупреждение о несоответствии
Режим NONSTRICT_READ_WRITE не является стратегией кэширования с записью, поскольку записи кэша становятся недействительными, а не обновляются. Аннулирование кэша не синхронизировано с текущей транзакцией базы данных. Даже если соответствующая запись в области кэша становится недействительной дважды (до и после завершения транзакции), все еще остается крошечное временное окно, когда кэш и база данных могут расходиться.
Следующий тест продемонстрирует эту проблему. Сначала мы определим логику транзакции Алисы:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
doInTransaction(session -> { LOGGER.info("Load and modify Repository"); Repository repository = (Repository) session.get(Repository.class, 1L); assertTrue(getSessionFactory().getCache() .containsEntity(Repository.class, 1L)); repository.setName("High-Performance Hibernate"); applyInterceptor.set(true);});endLatch.await();assertFalse(getSessionFactory().getCache() .containsEntity(Repository.class, 1L));doInTransaction(session -> { applyInterceptor.set(false); Repository repository = (Repository) session.get(Repository.class, 1L); LOGGER.info("Cached Repository {}", repository);}); |
Алиса загружает объект Repository и изменяет его в своей первой транзакции базы данных.
Чтобы вызвать еще одну параллельную транзакцию, когда Алиса готовится к фиксации, мы будем использовать следующий Hibernate Interceptor :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
private AtomicBoolean applyInterceptor = new AtomicBoolean();private final CountDownLatch endLatch = new CountDownLatch(1);private class BobTransaction extends EmptyInterceptor { @Override public void beforeTransactionCompletion(Transaction tx) { if(applyInterceptor.get()) { LOGGER.info("Fetch Repository"); assertFalse(getSessionFactory().getCache() .containsEntity(Repository.class, 1L)); executeSync(() -> { Session _session = getSessionFactory() .openSession(); Repository repository = (Repository) _session.get(Repository.class, 1L); LOGGER.info("Cached Repository {}", repository); _session.close(); endLatch.countDown(); }); assertTrue(getSessionFactory().getCache() .containsEntity(Repository.class, 1L)); } }} |
Запуск этого кода генерирует следующий вывод:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
[Alice]: Load and modify Repository[Alice]: select nonstrictr0_.id as id1_0_0_, nonstrictr0_.name as name2_0_0_ from repository nonstrictr0_ where nonstrictr0_.id=1[Alice]: update repository set name='High-Performance Hibernate' where id=1[Alice]: Fetch Repository from another transaction[Bob]: select nonstrictr0_.id as id1_0_0_, nonstrictr0_.name as name2_0_0_ from repository nonstrictr0_ where nonstrictr0_.id=1[Bob]: Cached Repository from Bob's transaction Repository{id=1, name='Hibernate-Master-Class'}[Alice]: committed JDBC Connection[Alice]: select nonstrictr0_.id as id1_0_0_, nonstrictr0_.name as name2_0_0_ from repository nonstrictr0_ where nonstrictr0_.id=1[Alice]: Cached Repository Repository{id=1, name='High-Performance Hibernate'} |
- Алиса выбирает репозиторий и обновляет его имя
- Пользовательский Hibernate Interceptor вызывается и транзакция Боба запускается
- Поскольку хранилище было удалено из кэша , Боб загрузит кэш 2-го уровня с текущим снимком базы данных.
- Алиса транзакция фиксирует, но теперь Cache содержит предыдущий снимок базы данных, который Боб только что загрузил
- Если третий пользователь теперь получит объект Repository , он также увидит устаревшую версию объекта, которая отличается от текущего снимка базы данных.
- После фиксации транзакции Алисы запись Cache снова удаляется, и любой последующий запрос загрузки объекта заполняет Cache текущим снимком базы данных.
Устаревшие данные против потерянных обновлений
Стратегия параллелизма NONSTRICT_READ_WRITE вводит крошечное окно несогласованности, когда база данных и кэш второго уровня могут не синхронизироваться. Хотя это может звучать ужасно, в действительности мы всегда должны разрабатывать наши приложения, чтобы справляться с этими ситуациями, даже если мы не используем кэш второго уровня. Hibernate предлагает повторяемые операции чтения на уровне приложения через кэш первого уровня с транзакционной записью, и все управляемые объекты становятся устаревшими. Сразу после загрузки объекта в текущий контекст персистентности его может обновить другая параллельная транзакция, и поэтому мы должны предотвратить перерастание устаревших данных в потерянные обновления .
Оптимистическое управление параллелизмом — эффективный способ справиться с потерянными обновлениями в длинных разговорах, и этот метод также может смягчить проблему несогласованности NONSTRICT_READ_WRITE .
Вывод
Стратегия параллелизма NONSTRICT_READ_WRITE является хорошим выбором для приложений, предназначенных главным образом для чтения (если это поддерживается механизмом оптимистической блокировки). Для сценариев с интенсивной записью механизм аннулирования кэша увеличит частоту пропуска кэша , что сделает этот метод неэффективным.
- Код доступен на GitHub .
| Ссылка: | Как Hibernate NONSTRICT_READ_WRITE CacheConcurrencyStrategy работает от нашего партнера по JCG Влада Михалча в блоге Влада Михалчеа . |