Вступление
Реактивные потоки — это стандарт для асинхронной потоковой обработки данных с неблокирующим противодавлением. Начиная с Java 9, они стали частью JDK в виде java.util.concurrent.Flow.*интерфейсов.
Наличие интерфейсов под рукой может побудить вас написать свои собственные реализации. Как ни удивительно, но не потому, что они в JDK.
В этой статье я собираюсь описать основные концепции обработки реактивного потока и показать, как не использовать API, включенные в JDK 9+. Кроме того, мы собираемся обдумать возможные направления, в которых поддержка JDK Reactive Streams может пойти в будущем.
Бесстыдная вилка
Если вы предпочитаете смотреть видео, а не читать, вот запись одного из моих выступлений на эту тему, которое, кстати, стало третьим по популярности выступлением Riga Dev Days 2016–18 . В противном случае, пожалуйста, продолжайте читать.
Обзор потоковой обработки
В обобщенной архитектуре потоковой обработки, которую большинство из вас, вероятно, видели хотя бы один раз, вы можете назвать несколько основных понятий:
- источник данных, иногда называемый производителем ,
- место назначения данных, иногда называемое потребителем ,
- один или несколько этапов обработки, которые что-то делают с данными.
В таком конвейере данные передаются от производителя через этапы обработки к потребителю:

Обобщенная архитектура обработки потоков
Теперь, если учесть, что вышеупомянутые компоненты могут иметь разные скорости обработки, есть два возможных сценария:
- Если нисходящий поток (т. Е. Компонент, который получает данные) быстрее, чем нисходящий поток (компонент, который отправляет данные), у вас все хорошо, поскольку конвейер должен работать без сбоев.
- Однако, если восходящий поток работает быстрее, тогда нижний поток становится заполненным данными, и ситуация начинает ухудшаться.
В последнем случае есть несколько стратегий для работы с избыточными данными:
- Сделайте это, но у буферов ограниченная емкость, и рано или поздно у вас закончится память.
- Отбросьте его — но тогда вы потеряете данные (что обычно нежелательно, но в некоторых случаях может иметь смысл — например, именно это часто делает сетевое оборудование).
- Блокируйте, пока потребитель не покончит с этим — но это может привести к замедлению всего конвейера.
Предпочтительным способом работы с этими различными возможностями обработки является метод, называемый обратным давлением, который сводится к тому, что более медленный потребитель запрашивает определенный объем данных у более быстрого производителя, но только тот объем, который потребитель может обработать в это время.
Возвращаясь к диаграмме потокового конвейера, вы можете рассматривать противодавление как особый вид данных сигнализации, передаваемых в противоположном направлении (по сравнению с обычными данными, которые обрабатываются:
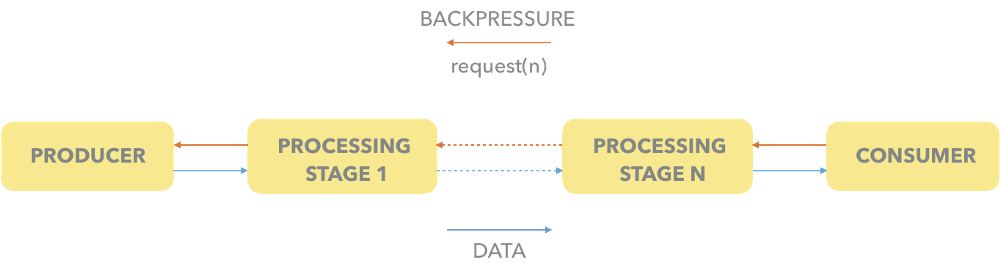
Потоковый трубопровод с противодавлением
Однако не каждый потоковый конвейер с противодавлением обязательно является реактивным.
Реактивные потоки
Ключевой концепцией Reactive Streams является обработка бесконечных потоков данных асинхронным и неблокирующим образом, чтобы вычислительные ресурсы (например, ядра ЦП или хосты сети) могли использоваться параллельно.
Есть три ключевых фактора, которые делают поток реактивным:
- данные обрабатываются асинхронно,
- механизм противодавления неблокирующий,
- тот факт, что нисходящий поток может быть медленнее, чем восходящий, каким-то образом представлен в модели предметной области.
Примеры последнего включают потокового API Twitter , где вы можете быть отключены , если потребляют слишком медленно, или один из встроенных этапов в Akka Streams - conflate - которая позволяет явно планировать медленно вниз по течению.
Поддержка реактивных потоков в JDK
Начиная с версии 9, интерфейсы Reactive Streams, ранее доступные как отдельная библиотека , стали частью JDK в java.util.concurrent.Flowклассе.
На первый взгляд четыре интерфейса кажутся довольно простыми:
Publisher<T>отвечает за публикацию элементов типаTи обеспечиваетsubscribeспособ для абонентов подключиться к нему- a
Subscriber<T>подключается к aPublisher, получает подтверждение черезonSubscribe, затем получает данные черезonNextобратные вызовы и дополнительные сигналы черезonErrorиonComplete - a
Subscriptionпредставляет связь между aPublisherи aSubscriberи позволяет оказать давление на издателяrequestили прекратить связь сcancel Processorсочетает в себе возможностиPublisherиSubscriberв одном интерфейсе
ОК, давайте код!
Наличие таких простых интерфейсов под рукой может соблазнить вас попытаться реализовать их. Например, вы можете написать тривиальную реализацию, Publisherкоторая публикует произвольный итератор целых чисел:
public class SimplePublisher implements Flow.Publisher<Integer> {
private final Iterator<Integer> iterator;
SimplePublisher(int count) {
this.iterator = IntStream.rangeClosed(1, count).iterator();
}
@Override
public void subscribe(Flow.Subscriber<? super Integer> subscriber) {
iterator.forEachRemaining(subscriber::onNext);
subscriber.onComplete();
}
}Затем вы можете попытаться запустить его, используя какой-нибудь фиктивный файл, subscriber который просто распечатывает полученные данные:
public static void main(String[] args) {
new SimplePublisher(10).subscribe(new Flow.Subscriber<>() {
@Override
public void onSubscribe(Flow.Subscription subscription) {}
@Override
public void onNext(Integer item) {
System.out.println("item = [" + item + "]");
}
@Override
public void onError(Throwable throwable) {}
@Override
public void onComplete() {
System.out.println("complete");
}
});
}Если вы запустите его и проверьте вывод, он должен был произвести:
item = [1]
item = [2]
item = [3]
item = [4]
item = [5]
item = [6]
item = [7]
item = [8]
item = [9]
item = [10]
completeИтак, это работает, верно? Похоже, что это так, но у вас может быть внутреннее чувство, что чего-то не хватает. Например, издатель не испускает элементы в соответствии с каким-либо требованием, а просто отправляет их сразу вниз.
Оказывается, есть способ доказать, что эта наивная реализация далека от правильной. Этого можно достичь, запустив пару тестов из TCK Reactive Streams . TCK (или комплект для обеспечения технологической совместимости) — это не что иное, как тестовая среда, которая проверяет правильность реализации реактивных компонентов с точки зрения взаимодействия компонентов друг с другом. Его цель — обеспечить бесперебойную совместную работу всех пользовательских реализаций Reactive Streams, связанных абстрактными интерфейсами, при одновременном правильном выполнении всех передач данных, сигнализации и противодавления.
Чтобы создать контрольный пример SimplePublisher, вам нужно добавить правильную зависимость в определение вашей сборки и расширить TCK FlowPublisherVerification:
public class SimplePublisherTest extends FlowPublisherVerification<Integer> {
public SimplePublisherTest() {
super(new TestEnvironment());
}
@Override
public Flow.Publisher<Integer> createFlowPublisher(long elements) {
return new SimplePublisher((int) elements);
}
@Override
public Flow.Publisher<Integer> createFailedFlowPublisher() {
return null;
}
}После запуска тестового примера для наивного издателя вы можете увидеть, что у него действительно есть некоторые проблемы:
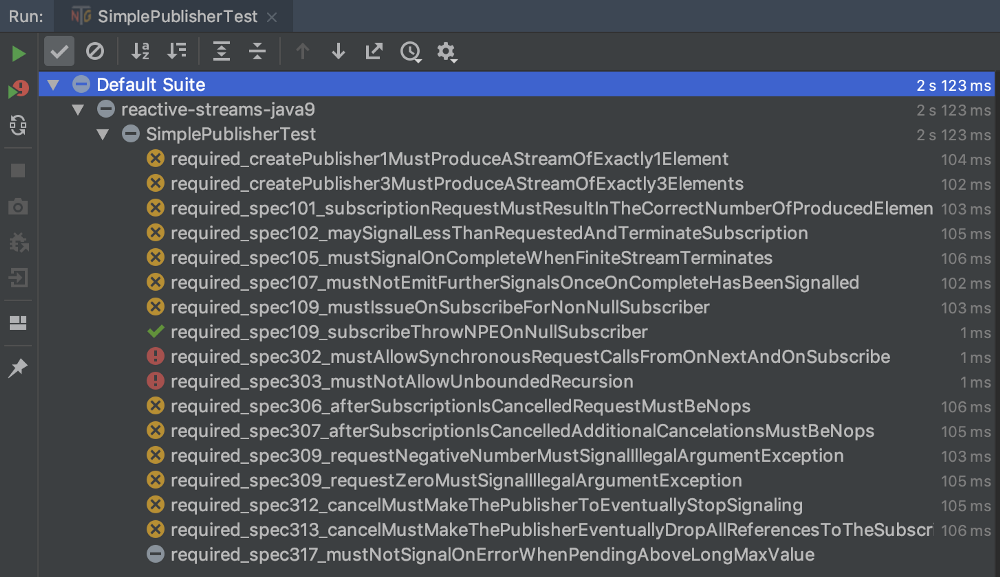
Результаты тестирования издателя TCK на SimplePublisher.
На самом деле, прошел только один тестовый случай; у всех остальных проблемы. Это ясно демонстрирует, что тривиальная реализация не является правильной.
Числа в именах тестовых примеров относятся к соответствующим элементам в спецификации Reactive Streams, где вы можете дополнительно изучить концепции, лежащие в основе этих требований.
Оказывается, что большинство проблем можно устранить с помощью пары небольших изменений, а именно:
- введение реализации
Subscriptionсвязи издателя с его подписчиками, которая будет генерировать элементы в соответствии со спросом - добавив базовую обработку ошибок
- добавление некоторого простого состояния в подписку для правильной обработки завершения.
Для получения подробной информации, пожалуйста, взгляните на историю коммитов в репозитории с примером кода.
Однако, в конце концов, вы придете к тому, что проблемы станут менее тривиальными и их будет сложнее решить.
Поскольку реализация является синхронной, существует проблема с неограниченной рекурсией, возникающая из-за того, что подписка request()вызывает абонента onNext(), где, в свою очередь, абонент request()снова звонит и т. Д.
Другая серьезная проблема связана с обработкой бесконечного спроса (т. Е. Подписчик запрашивает Long.MAX_VALUEэлементы, возможно, пару раз). Если вы здесь недостаточно осторожны, вы можете либо создать слишком много потоков, либо переполнить какое-то longзначение, чтобы вы могли сохранить накопленный спрос.
Не пробуй это дома
Суть приведенного выше примера заключается в том, что реактивные компоненты на самом деле не тривиальны для правильной реализации. Итак, если вы не создаете еще одну реализацию Reactive Streams, вам не следует реализовывать их самостоятельно, а использовать существующие реализации, которые проверены с помощью TCK.
И если вы все равно решите написать свою собственную реализацию, убедитесь, что понимаете все детали спецификации и не забудьте запустить TCK для своего кода.

Цель новых интерфейсов
Итак, для чего нужны интерфейсы, спросите себя? Фактическая цель включения их в JDK — предоставить то, что называется уровнем интерфейса поставщика услуг (или SPI). В конечном итоге это должно служить уровнем объединения для различных компонентов, которые имеют реактивную и потоковую природу, но могут предоставлять свои собственные пользовательские API и, следовательно, не смогут взаимодействовать с другими аналогичными реализациями.
Другая, не менее важная цель — направить будущее развитие JDK в правильном направлении, что приведет к тому, что существующие потоковые абстракции, которые уже присутствуют в JDK и широко используются, используют некоторые общие интерфейсы — еще раз улучшить совместимость.
Существующие потоковые абстракции
Итак, какие потоковые абстракции уже есть в JDK (что означает потоковую обработку больших, возможно бесконечных, объемов данных, порций за порциями, без предварительного считывания всех данных в память)? К ним относятся:
java.io.InputStream/OutputStreamjava.util.Iteratorjava.nio.channels.*javax.servlet.ReadListener/WriteListenerjava.sql.ResultSetjava.util.Streamjava.util.concurrent.Flow.*
Хотя все вышеперечисленные абстракции демонстрируют какое-то потоковое поведение, им не хватает общего API, который бы позволял вам легко их подключать, например, использовать a Publisherдля чтения данных из одного файла и a Subscriberдля записи в другой.
Преимущество такого объединяющего слоя заключается в возможности использовать один вызов:
publisher.subscribe(subscriber)Используйте это для обработки всех скрытых сложностей обработки реактивного потока (таких как противодавление и сигнализация).
На пути к идеальному миру
Каковы могут быть возможные результаты использования различных абстракций с общими интерфейсами? Давайте посмотрим на несколько примеров.
Минимальный набор операций
Текущая поддержка Reactive Streams в JDK ограничена четырьмя интерфейсами, описанными ранее. Если вы когда-либо использовали какую-либо реактивную библиотеку — Akka Streams , RxJava или Project Reactor — вы знаете, что их сила заключается в различных потоковых комбинаторах (например, mapили, filterесли назвать самые простые), доступных из коробки. Эти комбинаторы, однако, отсутствуют в JDK, хотя вы, вероятно, ожидаете, что по крайней мере пара из них будет доступна.
Чтобы решить эту проблему, Lightbend предложил POC Reactive Streams Utilities - библиотеку со встроенными базовыми операциями и возможностью предоставления более сложных из них в качестве плагинов, делегирующих существующей реализации, определяемой системным параметром JVM. как:
-Djava.flow.provider=akkaHTTP
Как мы получаем файл, загруженный через HTTP, и загружаем его куда-то еще, конечно же, в реактивном режиме?
Начиная с версии 3.1 сервлета существует асинхронный ввод-вывод сервлета. Кроме того, начиная с JDK 9, появился новый HTTP-клиент (который был в jdk.incubating.httpмодуле в Java 9/10, но считается стабильным с Java 11 и далее). Помимо более приятного API, новый клиент также поддерживает Reactive Streams в качестве ввода / вывода. Среди прочего, он предоставляет POST(Publisher<ByteBuffer>)метод.
Теперь, если HttpServletRequestбы издатель предоставил выставить тело запроса, загрузка полученного файла стала бы:
POST(BodyPublisher.fromPublisher(req.getPublisher())Это происходит со всеми реактивными функциями под капотом — просто с помощью этой единственной строки кода.
Доступ к базе данных
Когда речь заходит об универсальном способе доступа к реляционной базе данных реактивным способом, появилась некоторая надежда, связанная с API асинхронного доступа к базе данных (ADBA) , который, к сожалению, до сих пор не дошел до JDK.
Существует также R2DBC — попытка внедрить API реактивного программирования в реляционные хранилища данных . В настоящее время он поддерживает H2 и Postgres и прекрасно работает с Spring Data JPA , что может быть преимуществом, которое помогает при более широком внедрении.
Затем существуют некоторые специфичные для производителя асинхронные драйверы. Но мы все еще не нашли идеальное решение, которое позволило бы вам сделать что-то вроде:
Publisher<User> users = entityManager
.createQuery("select u from users")
.getResultPublisher()По сути, это обычный старый вызов JPA, только с Publisherпользователями вместо List.
Это все еще не реальность
Напомню еще раз — приведенные выше примеры — это взгляд в будущее. Они еще не здесь. В каком направлении движется экосистема JDK — это вопрос времени и усилий сообщества.
Фактическое использование уровня объединения
Хотя унификация HTTP и баз данных еще не достигнута, уже возможно фактически соединить различные реализации Reactive Streams, используя унифицированные интерфейсы, найденные в JDK.
В этом примере я собираюсь использовать Project Reactor в Fluxкачестве издателя, Akka Streams Flowв качестве процессора и RXJava в качестве подписчика. Примечание. В приведенном ниже примере кода используется Java 10 vars, поэтому, если вы планируете попробовать его самостоятельно, убедитесь, что у вас установлен правильный JDK.
public class IntegrationApp {
public static void main(String[] args) {
var reactorPublisher = reactorPublisher();
var akkaStreamsProcessor = akkaStreamsProcessor();
reactorPublisher.subscribe(akkaStreamsProcessor);
Flowable
.fromPublisher(FlowAdapters.toProcessor(akkaStreamsProcessor))
.subscribe(System.out::println);
}
private static Publisher<Long> reactorPublisher() {
var numberFlux = Flux.interval(Duration.ofSeconds(1));
return JdkFlowAdapter.publisherToFlowPublisher(numberFlux);
}
private static Processor<Long, Long> akkaStreamsProcessor() {
var negatingFlow = Flow.of(Long.class).map(i -> -i);
return JavaFlowSupport.Flow.toProcessor(negatingFlow).run(materializer);
}
private static ActorSystem actorSystem = ActorSystem.create();
private static ActorMaterializer materializer = ActorMaterializer.create(actorSystem);
}Глядя main, вы можете видеть , что есть три компонента , которые образуют трубопровод: reactorPublisher, то akkaStreamsProcessorи Flowable, которая печатает на стандартный вывод.
Когда вы посмотрите на типы возврата фабричных методов, вы заметите, что они представляют собой не что иное, как обычные интерфейсы Reactive Streams (a Publisher<Long>и a Processor<Long, Long>), которые используются для бесшовного соединения различных реализаций.
Кроме того, как вы можете видеть, различные библиотеки не возвращают унифицированные типы «из коробки» (то есть они внутренне используют другую иерархию типов), но им нужен некоторый связующий код, который бы преобразовывал их внутренние типы в типы из java.util.concurrent.Flow.* - как JdkFlowAdapterили JavaFlowSupport.
И последнее, но не менее важное: вы можете заметить некоторые различия между различными библиотеками с точки зрения того, как они раскрывают внутренности потокового движка. В то время как Project Reactor полностью скрывает внутренние компоненты, Akka Streams, с другой стороны, требует, чтобы вы явно указали материализатор — время выполнения для потокового конвейера.
Резюме
Вот несколько ключевых выводов из этой статьи:
- Поддержка реактивных потоков в JDK — это не полная реализация спецификации, а только общие интерфейсы,
- интерфейсы предназначены для использования в качестве SPI (интерфейса поставщика услуг) — уровня унификации для различных реализаций реактивных потоков,
- Реализация интерфейсов самостоятельно не тривиальна и не рекомендуется, если вы не создаете новую библиотеку; если вы решите реализовать их, убедитесь, что все тесты из TCK имеют зеленый цвет — это дает вам хороший шанс, что ваша библиотека будет работать с другими реактивными компонентами.
Если вы хотите поэкспериментировать с TCK и SimplePublisherпримером, код доступен на моем GitHub .
И если вы заинтересованы в более глубоком изучении реализации Reactive Streams, я искренне рекомендую блог Advanced Reactive Java и блог SoftwareMill Tech для дополнительных постов, подобных этому.