Примечание редактора: не пропустите наш новый бесплатный учебный курс по требованию о том, как создавать приложения конвейера данных с использованием Apache Spark — узнайте больше здесь
Этот пост поможет вам начать использовать Apache Spark GraphX с Scala в песочнице MapR. GraphX - это компонент Apache Spark для параллельных графов вычислений, построенный на ветви математики, называемой теорией графов. Это распределенная среда обработки графиков, которая располагается поверх ядра Spark.
Обзор некоторых понятий графа
Граф — это математическая структура, используемая для моделирования отношений между объектами. Граф состоит из вершин и ребер, которые их соединяют. Вершины — это объекты, а ребра — это отношения между ними.
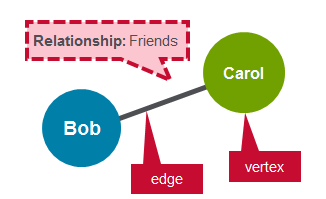
Направленный граф — это граф, в котором ребра имеют направление, связанное с ними. Примером ориентированного графа является последователь Twitter. Пользователь Bob может следовать за пользователем Carol, не подразумевая, что пользователь Carol следует за пользователем Bob.
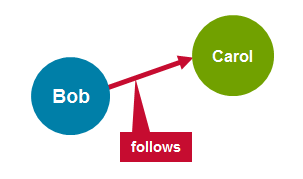
Регулярный граф — это граф, в котором каждая вершина имеет одинаковое количество ребер. Примером регулярного графика являются друзья в Facebook. Если Боб друг Кэрол, то Кэрол тоже друг Боба.
GraphX Property Graph
GraphX расширяет Spark RDD графом распределенных эластичных свойств.
Граф свойств представляет собой ориентированный мультиграф, который может иметь несколько ребер параллельно. Каждое ребро и вершина имеют определенные пользователем свойства, связанные с ним. Параллельные ребра допускают множественные отношения между одними и теми же вершинами.
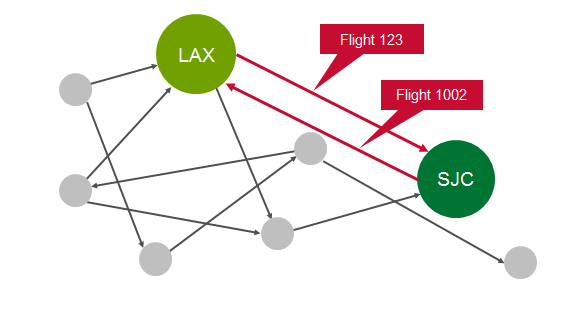
В этом упражнении вы будете использовать GraphX для анализа полетных данных.
сценарий
В качестве исходного простого примера рассмотрим три полета. Для каждого рейса у нас есть следующая информация:
| Исходный аэропорт | Аэропорт назначения | Расстояние |
| SFO | ORD | 1800 миль |
| ORD | DFW> | 800 миль |
| DFW | SFO> | 1400 миль |
В этом сценарии мы будем представлять аэропорты как вершины, а маршруты как ребра. Для нашего графика у нас будет три вершины, каждая из которых представляет аэропорт. Расстояние между аэропортами является свойством маршрута, как показано ниже: 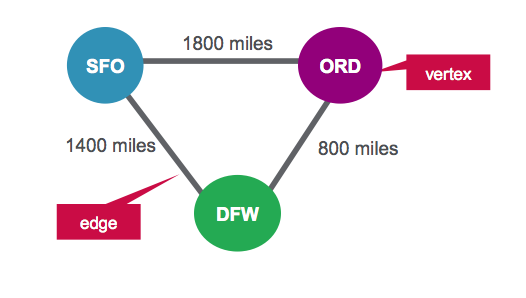
Стол Vertex для аэропортов
| МНЕ БЫ | Имущество |
| 1 | SFO |
| 2 | ORD |
| 3 | DFW |
Таблица ребер для маршрутов
| SrcId | DestId | Имущество |
| 1 | 2 | 1800 |
| 2 | 3 | 800 |
| 3 | 1 | 1400 |
Программного обеспечения
Это руководство будет работать в песочнице MapR, в которую входит Spark.
- Вы можете скачать код и данные для запуска этих примеров здесь:
- Примеры в этом посте можно запустить в оболочке Spark после запуска с помощью команды spark-shell.
- Вы также можете запустить код как отдельное приложение, как описано в руководстве по началу работы с Spark в MapR Sandbox .
Запустите Spark Interactive Shell
Войдите в MapR Sandbox, как описано в разделе Начало работы с Spark в MapR Sandbox , используя идентификатор пользователя user01, пароль mapr. Начните искровую оболочку с:
|
1
|
$ spark-shell |
Определить вершины
Сначала мы импортируем пакеты GraphX.
(В полях кода комментарии отображаются зеленым, а вывод — синим)
|
1
2
3
4
|
import org.apache.spark._import org.apache.spark.rdd.RDD// import classes required for using GraphXimport org.apache.spark.graphx._ |
Мы определяем аэропорты как вершины. Вершины имеют идентификатор и могут иметь свойства или атрибуты, связанные с ними. Каждая вершина состоит из:
- Идентификатор вершины → Идентификатор (длинный)
- Свойство вершины → имя (строка)
Стол Vertex для аэропортов
| МНЕ БЫ | Свойство (В) |
| 1 | SFO |
Мы определяем СДР с указанными выше свойствами, которые затем используются для вершин.
|
1
2
3
4
5
6
7
|
// create vertices RDD with ID and Nameval vertices=Array((1L, ("SFO")),(2L, ("ORD")),(3L,("DFW")))val vRDD= sc.parallelize(vertices)vRDD.take(1)// Array((1,SFO)) // Defining a default vertex called nowhereval nowhere = "nowhere" |
Определить края
Края — это маршруты между аэропортами. Ребро должно иметь источник, назначение и может иметь свойства. В нашем примере ребро состоит из:
- Идентификатор происхождения края → src (Long)
- Идентификатор конечного пункта назначения → dest (Long)
- Edge Свойство расстояние → расстояние (Long)
Таблица ребер для маршрутов
| srcid | destid | Свойство (E) |
| 1 | 12 | 1800 |
Мы определяем СДР с указанными выше свойствами, которые затем используются для ребер. Ребро RDD имеет форму (идентификатор src, идентификатор id, расстояние).
|
1
2
3
4
5
|
// create routes RDD with srcid, destid, distanceval edges = Array(Edge(1L,2L,1800),Edge(2L,3L,800),Edge(3L,1L,1400))val eRDD= sc.parallelize(edges) eRDD.take(2)// Array(Edge(1,2,1800), Edge(2,3,800)) |
Создать график свойств
Чтобы создать график, вам необходимо иметь RDD вершины, ED Rdge и вершину по умолчанию.
Создайте граф свойств с именем graph.
|
01
02
03
04
05
06
07
08
09
10
11
12
|
// define the graphval graph = Graph(vRDD,eRDD, nowhere)// graph verticesgraph.vertices.collect.foreach(println)// (2,ORD)// (1,SFO)// (3,DFW) // graph edgesgraph.edges.collect.foreach(println) // Edge(1,2,1800)// Edge(2,3,800)// Edge(3,1,1400) |
1. Сколько аэропортов там?
|
1
2
3
|
// How many airports?val numairports = graph.numVertices// Long = 3 |
2. Сколько существует маршрутов?
|
1
2
3
|
// How many routes?val numroutes = graph.numEdges// Long = 3 |
3. какие маршруты> 1000 миль?
|
1
2
3
4
|
// routes > 1000 miles distance?graph.edges.filter { case Edge(src, dst, prop) => prop > 1000 }.collect.foreach(println)// Edge(1,2,1800)// Edge(3,1,1400) |
4. Класс EdgeTriplet расширяет класс Edge, добавляя члены srcAttr и dstAttr, которые содержат свойства источника и назначения, соответственно.
|
1
2
3
4
5
|
// tripletsgraph.triplets.take(3).foreach(println)((1,SFO),(2,ORD),1800)((2,ORD),(3,DFW),800)((3,DFW),(1,SFO),1400) |
5. Сортировка и распечатка самых длинных маршрутов
|
1
2
3
4
5
6
|
// print out longest routesgraph.triplets.sortBy(_.attr, ascending=false).map(triplet => "Distance " + triplet.attr.toString + " from " + triplet.srcAttr + " to " + triplet.dstAttr + ".").collect.foreach(println) Distance 1800 from SFO to ORD.Distance 1400 from DFW to SFO.Distance 800 from ORD to DFW. |
Анализ данных реального полета с GraphX
сценарий
Наши данные взяты из http://www.transtats.bts.gov/DL_SelectFields.asp?Table_ID=236&DB_Short_Name=On-Time . Мы используем информацию о рейсе за январь 2015 года. Для каждого рейса у нас есть следующая информация:
| поле | Описание | Пример значения |
| ДОФМ (String) | День месяца | 1 |
| dOfW (Строка) | День недели | 4 |
| Перевозчик (Строка) | Код оператора | А.А. |
| tailNum (Строка) | Уникальный идентификатор самолета — номер хвоста | N787AA |
| flnum (Int) | Номер рейса | 21 |
| org_ID (String) | Идентификационный номер аэропорта | 12478 |
| происхождения (String) | Код аэропорта происхождения | JFK |
| dest_id (Строка) | ID аэропорта назначения | 12892 |
| dest (String) | Код аэропорта назначения | LAX |
| crsdeptime (Двухместный) | Запланированное время отправления | 900 |
| deptime (Двухместный) | Фактическое время отправления | 855 |
| depdelaymins (Двухместный) | Задержка вылета в минутах | 0 |
| crsarrtime (двухместный) | Запланированное время прибытия | 1230 |
| arrtime (Двухместный) | Фактическое время прибытия | 1237 |
| arrdelaymins (Двухместный) | Минуты задержки прибытия | 7 |
| crselapsedtime (Двухместный) | Пройденное время | 390 |
| dist (Int) | Расстояние | 2475 |
В этом сценарии мы будем представлять аэропорты как вершины, а маршруты как ребра. Мы заинтересованы в визуализации аэропортов и маршрутов и хотели бы видеть количество аэропортов, которые имеют отправления или прибытия.
- Вы можете скачать код и данные для запуска этих примеров здесь: https://github.com/caroljmcdonald/sparkgraphxexample
Войдите в MapR Sandbox, как описано в разделе Начало работы с Spark в MapR Sandbox , используя идентификатор пользователя user01, пароль mapr. Скопируйте пример файла данных rita2014jan.csv в домашнюю директорию песочницы / user / user01 с помощью scp.
Запустите оболочку Spark с помощью:
|
1
|
$ spark-shell |
Определить вершины
Сначала мы импортируем пакеты GraphX.
(В полях кода комментарии отображаются зеленым, а вывод — синим)
|
1
2
3
4
5
6
|
import org.apache.spark._import org.apache.spark.rdd.RDDimport org.apache.spark.util.IntParam// import classes required for using GraphXimport org.apache.spark.graphx._import org.apache.spark.graphx.util.GraphGenerators |
Ниже мы используем классы случаев Scala для определения схемы полета, соответствующей файлу данных CSV.
|
1
2
|
// define the Flight Schemacase class Flight(dofM:String, dofW:String, carrier:String, tailnum:String, flnum:Int, org_id:Long, origin:String, dest_id:Long, dest:String, crsdeptime:Double, deptime:Double, depdelaymins:Double, crsarrtime:Double, arrtime:Double, arrdelay:Double,crselapsedtime:Double,dist:Int) |
Функция ниже анализирует строку из файла данных в классе полета.
|
1
2
3
4
5
|
// function to parse input into Flight classdef parseFlight(str: String): Flight = { val line = str.split(",") Flight(line(0), line(1), line(2), line(3), line(4).toInt, line(5).toLong, line(6), line(7).toLong, line(8), line(9).toDouble, line(10).toDouble, line(11).toDouble, line(12).toDouble, line(13).toDouble, line(14).toDouble, line(15).toDouble, line(16).toInt)} |
Ниже мы загружаем данные из файла CSV в Resilient Distributed Dataset (RDD) . СДР могут иметь преобразования и действия , действие first () возвращает первый элемент СДР.
|
1
2
3
4
5
|
// load the data into a RDDval textRDD = sc.textFile("/user/user01/data/rita2014jan.csv")// MapPartitionsRDD[1] at textFile // parse the RDD of csv lines into an RDD of flight classesval flightsRDD = textRDD.map(parseFlight).cache() |
Мы определяем аэропорты как вершины. Вершины могут иметь свойства или атрибуты, связанные с ними. Каждая вершина имеет следующее свойство:
- Название аэропорта (Строка)
Стол Vertex для аэропортов
| МНЕ БЫ | Свойство (В) |
| 10397 | АТЛ |
Мы определяем СДР с указанными выше свойствами, которые затем используются для вершин.
|
1
2
3
4
5
6
7
8
9
|
// create airports RDD with ID and Nameval airports = flightsRDD.map(flight => (flight.org_id, flight.origin)).distinct airports.take(1)// Array((14057,PDX)) // Defining a default vertex called nowhereval nowhere = "nowhere"// Map airport ID to the 3-letter code to use for printlnsval airportMap = airports.map { case ((org_id), name) => (org_id -> name) }.collect.toList.toMap// Map(13024 -> LMT, 10785 -> BTV,…) |
Определить края
Края — это маршруты между аэропортами. Ребро должно иметь источник, назначение и может иметь свойства. В нашем примере ребро состоит из:
- Идентификатор происхождения края → src (Long)
- Идентификатор конечного пункта назначения → dest (Long)
- Пограничное свойство расстояние → расстояние (Long)
Таблица ребер для маршрутов
| srcid | destid | Свойство (E) |
| 14869 | 14683 | 1087 |
Мы определяем СДР с указанными выше свойствами, которые затем используются для ребер. Ребро RDD имеет форму (идентификатор src, идентификатор id, расстояние).
|
1
2
3
4
5
6
7
8
9
|
// create routes RDD with srcid, destid, distanceval routes = flightsRDD.map(flight => ((flight.org_id, flight.dest_id), flight.dist)).distinctdistinct routes.take(2)// Array(((14869,14683),1087), ((14683,14771),1482)) // create edges RDD with srcid, destid , distanceval edges = routes.map { case ((org_id, dest_id), distance) =>Edge(org_id.toLong, dest_id.toLong, distance) } edges.take(1)//Array(Edge(10299,10926,160)) |
Создать график свойств
Чтобы создать график, вам нужно иметь RDD вершины, ED Rdge и вершину по умолчанию.
Создайте граф свойств с именем graph.
|
1
2
3
4
5
6
7
8
|
// define the graphval graph = Graph(airports, edges, nowhere) // graph verticesgraph.vertices.take(2)Array((10208,AGS), (10268,ALO)) // graph edgesgraph.edges.take(2)Array(Edge(10135,10397,692), Edge(10135,13930,654)) |
6. Сколько аэропортов там?
|
1
2
3
|
// How many airports?val numairports = graph.numVertices// Long = 301 |
7. Сколько существует маршрутов?
|
1
2
3
|
// How many airports?val numroutes = graph.numEdges// Long = 4090 |
8. Какие маршруты> 1000 миль?
|
1
2
3
|
// routes > 1000 miles distance?graph.edges.filter { case ( Edge(org_id, dest_id,distance))=> distance > 1000}.take(3)// Array(Edge(10140,10397,1269), Edge(10140,10821,1670), Edge(10140,12264,1628)) |
9. Класс EdgeTriplet расширяет класс ребер, добавляя члены srcAttr и dstAttr, которые содержат свойства источника и назначения, соответственно.
|
1
2
3
4
5
|
// tripletsgraph.triplets.take(3).foreach(println)((10135,ABE),(10397,ATL),692)((10135,ABE),(13930,ORD),654)((10140,ABQ),(10397,ATL),1269) |
10. Сортировка и распечатка самых длинных маршрутов
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
// print out longest routesgraph.triplets.sortBy(_.attr, ascending=false).map(triplet => "Distance " + triplet.attr.toString + " from " + triplet.srcAttr + " to " + triplet.dstAttr + ".").take(10).foreach(println) Distance 4983 from JFK to HNL.Distance 4983 from HNL to JFK.Distance 4963 from EWR to HNL.Distance 4963 from HNL to EWR.Distance 4817 from HNL to IAD.Distance 4817 from IAD to HNL.Distance 4502 from ATL to HNL.Distance 4502 from HNL to ATL.Distance 4243 from HNL to ORD.Distance 4243 from ORD to HNL. |
11. Вычислить вершину высшей степени
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
// Define a reduce operation to compute the highest degree vertexdef max(a: (VertexId, Int), b: (VertexId, Int)): (VertexId, Int) = { if (a._2 > b._2) a else b}val maxInDegree: (VertexId, Int) = graph.inDegrees.reduce(max)//maxInDegree: (org.apache.spark.graphx.VertexId, Int) = (10397,152) val maxOutDegree: (VertexId, Int) = graph.outDegrees.reduce(max)//maxOutDegree: (org.apache.spark.graphx.VertexId, Int) = (10397,153) val maxDegrees: (VertexId, Int) = graph.degrees.reduce(max)//maxDegrees: (org.apache.spark.graphx.VertexId, Int) = (10397,305) // Get the name for the airport with id 10397airportMap(10397)//res70: String = ATL |
12. В каком аэропорту больше всего рейсов?
|
01
02
03
04
05
06
07
08
09
10
11
12
|
// get top 3val maxIncoming = graph.inDegrees.collect.sortWith(_._2 > _._2).map(x => (airportMap(x._1), x._2)).take(3) maxIncoming.foreach(println)(ATL,152)(ORD,145)(DFW,143) // which airport has the most outgoing flights?val maxout= graph.outDegrees.join(airports).sortBy(_._2._1, ascending=false).take(3) maxout.foreach(println)(10397,(153,ATL))(13930,(146,ORD))(11298,(143,DFW)) |
PageRank
Другим оператором GraphX является PageRank. который основан на алгоритме Google PageRank.
PageRank измеряет важность каждой вершины в графе, определяя, у каких вершин больше всего ребер с другими вершинами. В нашем примере мы можем использовать PageRank, чтобы определить, какие аэропорты являются наиболее важными, измерив, какие аэропорты имеют наибольшее количество соединений с другими аэропортами.
Мы должны указать допуск, который является мерой сходимости.
13. Каковы наиболее важные аэропорты в соответствии с PageRank?
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
// use pageRankval ranks = graph.pageRank(0.1).vertices// join the ranks with the map of airport id to nameval temp= ranks.join(airports)temp.take(1)// Array((15370,(0.5365013694244737,TUL))) // sort by rankingval temp2 = temp.sortBy(_._2._1, false)temp2.take(2)//Array((10397,(5.431032677813346,ATL)), (13930,(5.4148119418905765,ORD))) // get just the airport namesval impAirports =temp2.map(_._2._2)impAirports.take(4)//res6: Array[String] = Array(ATL, ORD, DFW, DEN) |
Преголя
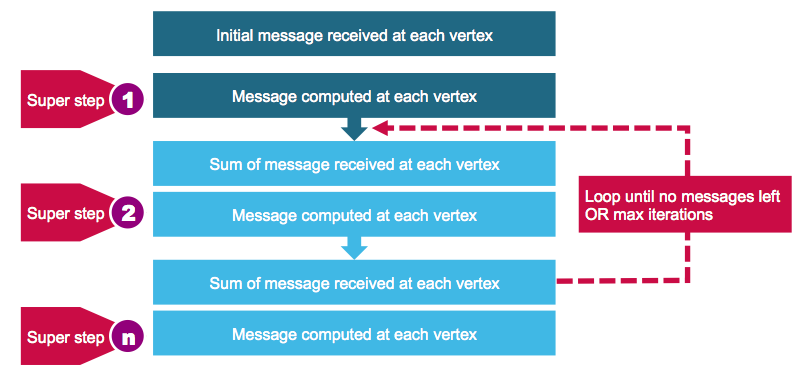
Многие важные графовые алгоритмы являются итерационными алгоритмами, поскольку свойства вершин зависят от свойств их соседей, которые зависят от свойств их соседей. Pregel — это модель итеративной обработки графа, разработанная в Google, которая использует последовательность итераций сообщений, проходящих между вершинами графа. GraphX реализует Pregel-подобный API для синхронной передачи сообщений.
Благодаря реализации Pregel в GraphX вершины могут отправлять сообщения только в соседние вершины.
Оператор Прегеля выполняется в серии супершагов. На каждом супер шаге:
- Вершины получают сумму своих входящих сообщений из предыдущего суперэтапа
- Они вычисляют новое значение для свойства вершины
- Они отправляют сообщения в соседние вершины в следующем супершаге
Когда больше не осталось сообщений, оператор Pregel завершит итерацию и вернется окончательный граф.
Приведенный ниже код вычисляет самую дешевую стоимость авиабилетов, используя Pregel по следующей формуле для расчета стоимости авиабилетов.
50 + расстояние / 20
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
// starting vertexval sourceId: VertexId = 13024// a graph with edges containing airfare cost calculationval gg = graph.mapEdges(e => 50.toDouble + e.attr.toDouble/20 )// initialize graph, all vertices except source have distance infinityval initialGraph = gg.mapVertices((id, _) => if (id == sourceId) 0.0 else Double.PositiveInfinity)// call pregel on graphval sssp = initialGraph.pregel(Double.PositiveInfinity)( // Vertex Program (id, dist, newDist) => math.min(dist, newDist), triplet => { // Send Message if (triplet.srcAttr + triplet.attr < triplet.dstAttr) { Iterator((triplet.dstId, triplet.srcAttr + triplet.attr)) } else { Iterator.empty } }, // Merge Message (a,b) => math.min(a,b)) // routes , lowest flight costprintln(sssp.edges.take(4).mkString("\n"))Edge(10135,10397,84.6)Edge(10135,13930,82.7)Edge(10140,10397,113.45)Edge(10140,10821,133.5) // routes with airport codes , lowest flight costssp.edges.map{ case ( Edge(org_id, dest_id,price))=> ( (airportMap(org_id), airportMap(dest_id), price)) }.takeOrdered(10)(Ordering.by(_._3))Array((WRG,PSG,51.55), (PSG,WRG,51.55), (CEC,ACV,52.8), (ACV,CEC,52.8), (ORD,MKE,53.35), (IMT,RHI,53.35), (MKE,ORD,53.35), (RHI,IMT,53.35), (STT,SJU,53.4), (SJU,STT,53.4)) // airports , lowest flight costprintln(sssp.vertices.take(4).mkString("\n")) (10208,277.79)(10268,260.7)(14828,261.65)(14698,125.25) // airport codes , sorted lowest flight costsssp.vertices.collect.map(x => (airportMap(x._1), x._2)).sortWith(_._2 < _._2)res21: Array[(String, Double)] = Array(PDX,62.05), (SFO,65.75), (EUG,117.35) |
Хотите узнать больше?
- Руководство по программированию GraphX
- MapR объявляет о бесплатной полной Apache Spark Обучение и сертификация разработчика
- Бесплатное обучение Spark On Demand
- Получите сертификат Spark с сертификатом MapR Spark
- MapR Сертифицированное руководство по разработке Spark Developer
В этом посте вы узнали, как начать использовать Apache Spark GraphX с Scala в песочнице MapR. Если у вас есть какие-либо вопросы о GraphX, пожалуйста, задавайте их в разделе комментариев ниже.
| Ссылка: | Как начать использовать Apache Spark GraphX с Scala от нашего партнера по JCG Кэрол Макдональд в блоге Mapr . |