Quartz Scheduler — одна из самых популярных библиотек планирования в мире Java. В прошлом я работал с Quartz в основном в приложениях Spring. Недавно я исследовал планирование в приложении JEE 6, работающем на JBoss 7.1.1, которое будет развернуто в облаке. Одним из вариантов, которые я рассматриваю, является Quartz Scheduler, поскольку он предлагает кластеризацию с базой данных. В этой статье я покажу, как легко настроить Quartz в приложении JEE и запустить его на JBoss 7.1.1 или WildFly 8.0.0, использовать MySQL в качестве хранилища заданий и использовать CDI для использования внедрения зависимостей в заданиях. Все будет сделано в IntelliJ. Давайте начнем.
Создать проект Maven
Я использовал org.codehaus.mojo.archetypes:webapp-javaee6 archetype для начальной загрузки приложения, а затем я немного изменил pom.xml . Я также добавил зависимость slf4J , поэтому результирующий pom.xml выглядит следующим образом:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
|
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" <modelVersion>4.0.0</modelVersion> <groupId>pl.codeleak</groupId> <artifactId>quartz-jee-demo</artifactId> <version>1.0</version> <packaging>war</packaging> <name>quartz-jee-demo</name> <properties> <endorsed.dir>${project.build.directory}/endorsed</endorsed.dir> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <dependency> <groupId>javax</groupId> <artifactId>javaee-api</artifactId> <version>6.0</version> <scope>provided</scope> </dependency> <!-- Logging --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.7</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-jdk14</artifactId> <version>1.7.7</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>2.3.2</version> <configuration> <source>1.7</source> <target>1.7</target> <compilerArguments> <endorseddirs>${endorsed.dir}</endorseddirs> </compilerArguments> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-war-plugin</artifactId> <version>2.1.1</version> <configuration> <failOnMissingWebXml>false</failOnMissingWebXml> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-dependency-plugin</artifactId> <version>2.1</version> <executions> <execution> <phase>validate</phase> <goals> <goal>copy</goal> </goals> <configuration> <outputDirectory>${endorsed.dir}</outputDirectory> <silent>true</silent> <artifactItems> <artifactItem> <groupId>javax</groupId> <artifactId>javaee-endorsed-api</artifactId> <version>6.0</version> <type>jar</type> </artifactItem> </artifactItems> </configuration> </execution> </executions> </plugin> </plugins> </build></project> |
Следующим шагом был импорт проекта в IDE. В моем случае это IntelliJ и создайте конфигурацию запуска с JBoss 7.1.1.
Одно замечание: в настройках виртуальной машины в конфигурации запуска я добавил две переменные:
|
1
2
|
-Djboss.server.default.config=standalone-custom.xml-Djboss.socket.binding.port-offset=100 |
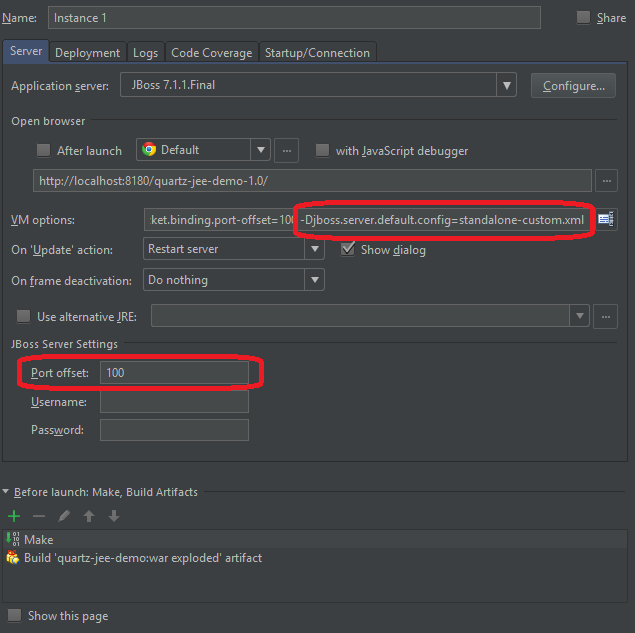
standalone-custom.xml является копией стандартного standalone.xml , так как необходимо будет изменить конфигурацию (см. ниже).
Настроить сервер JBoss
В моем демонстрационном приложении я хотел использовать базу данных MySQL с Quartz, поэтому мне нужно было добавить источник данных MySQL в мою конфигурацию. Это можно быстро сделать за два шага.
Добавить модуль драйвера
Я создал папку JBOSS_HOME/modules/com/mysql/main . В эту папку я добавил два файла: module.xml и mysql-connector-java-5.1.23.jar . Файл модуля выглядит следующим образом:
|
1
2
3
4
5
6
7
8
9
|
<?xml version="1.0" encoding="UTF-8"?> <module xmlns="urn:jboss:module:1.0" name="com.mysql"> <resources> <resource-root path="mysql-connector-java-5.1.23.jar"/> </resources> <dependencies> <module name="javax.api"/> </dependencies> </module> |
Настроить источник данных
В файле standalone-custom.xml в подсистеме datasources я добавил новый источник данных:
|
1
2
3
4
5
6
7
8
|
<datasource jta="false" jndi-name="java:jboss/datasources/MySqlDS" pool-name="MySqlDS" enabled="true" use-java-context="true"> <connection-url>jdbc:mysql://localhost:3306/javaee</connection-url> <driver>com.mysql</driver> <security> <user-name>jeeuser</user-name> <password>pass</password> </security></datasource> |
И водитель:
|
1
2
3
|
<drivers> <driver name="com.mysql" module="com.mysql"/></drivers> |
Примечание: Для целей этой демонстрации источник данных не JTA удалось упростить настройку.
Настройте кварц с кластеризацией
Я использовал официальное руководство для настройки Quarts с кластеризацией: http://quartz-scheduler.org/documentation/quartz-2.2.x/configuration/ConfigJDBCJobStoreClustering
Добавить Quartz-зависимости в pom.xml
|
01
02
03
04
05
06
07
08
09
10
|
<dependency> <groupId>org.quartz-scheduler</groupId> <artifactId>quartz</artifactId> <version>2.2.1</version></dependency><dependency> <groupId>org.quartz-scheduler</groupId> <artifactId>quartz-jobs</artifactId> <version>2.2.1</version></dependency> |
Добавьте quartz.properties в src/main/resources
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#============================================================================# Configure Main Scheduler Properties #============================================================================org.quartz.scheduler.instanceName = MySchedulerorg.quartz.scheduler.instanceId = AUTO#============================================================================# Configure ThreadPool #============================================================================org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPoolorg.quartz.threadPool.threadCount = 1#============================================================================# Configure JobStore #============================================================================org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTXorg.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegateorg.quartz.jobStore.useProperties = falseorg.quartz.jobStore.dataSource=MySqlDSorg.quartz.jobStore.isClustered = trueorg.quartz.jobStore.clusterCheckinInterval = 5000org.quartz.dataSource.MySqlDS.jndiURL=java:jboss/datasources/MySqlDS |
Создание таблиц MySQL для использования в Quartz
Файл схемы находится в дистрибутиве Quartz: quartz-2.2.1\docs\dbTables .
Демо-код
Имея конфигурацию на месте, я хотел проверить, работает ли Quartz, поэтому я создал планировщик без заданий и триггеров.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
package pl.codeleak.quartzdemo;import org.quartz.JobKey;import org.quartz.Scheduler;import org.quartz.SchedulerException;import org.quartz.TriggerKey;import org.quartz.impl.StdSchedulerFactory;import org.quartz.impl.matchers.GroupMatcher;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import javax.annotation.PostConstruct;import javax.annotation.PreDestroy;import javax.ejb.Singleton;import javax.ejb.Startup;@Startup@Singletonpublic class SchedulerBean { private Logger LOG = LoggerFactory.getLogger(SchedulerBean.class); private Scheduler scheduler; @PostConstruct public void scheduleJobs() { try { scheduler = new StdSchedulerFactory().getScheduler(); scheduler.start(); printJobsAndTriggers(scheduler); } catch (SchedulerException e) { LOG.error("Error while creating scheduler", e); } } private void printJobsAndTriggers(Scheduler scheduler) throws SchedulerException { LOG.info("Quartz Scheduler: {}", scheduler.getSchedulerName()); for(String group: scheduler.getJobGroupNames()) { for(JobKey jobKey : scheduler.getJobKeys(GroupMatcher.<JobKey>groupEquals(group))) { LOG.info("Found job identified by {}", jobKey); } } for(String group: scheduler.getTriggerGroupNames()) { for(TriggerKey triggerKey : scheduler.getTriggerKeys(GroupMatcher.<TriggerKey>groupEquals(group))) { LOG.info("Found trigger identified by {}", triggerKey); } } } @PreDestroy public void stopJobs() { if (scheduler != null) { try { scheduler.shutdown(false); } catch (SchedulerException e) { LOG.error("Error while closing scheduler", e); } } }} |
Когда вы запустите приложение, вы сможете увидеть отладочную информацию из Quartz:
|
1
2
3
4
5
6
|
Scheduler class: 'org.quartz.core.QuartzScheduler' - running locally. NOT STARTED. Currently in standby mode. Number of jobs executed: 0 Using thread pool 'org.quartz.simpl.SimpleThreadPool' - with 1 threads. Using job-store 'org.quartz.impl.jdbcjobstore.JobStoreTX' - which supports persistence. and is clustered. |
Пусть Кварц использует CDI
В Quartz задания должны реализовывать интерфейс org.quartz.Job .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
package pl.codeleak.quartzdemo;import org.quartz.Job;import org.quartz.JobExecutionContext;import org.quartz.JobExecutionException;public class SimpleJob implements Job { @Override public void execute(JobExecutionContext context) throws JobExecutionException { // do something }} |
Затем для создания вакансии мы используем JobBuilder:
|
1
2
3
4
5
|
JobKey job1Key = JobKey.jobKey("job1", "my-jobs");JobDetail job1 = JobBuilder .newJob(SimpleJob.class) .withIdentity(job1Key) .build(); |
В моем примере мне нужно было внедрить EJB в мои задания, чтобы повторно использовать существующую логику приложения. Так что на самом деле мне нужно было вставить ссылку на EJB. Как это можно сделать с помощью кварца? Легко. В Quartz Scheduler есть метод для предоставления JobFactory, который будет отвечать за создание экземпляров Job.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
package pl.codeleak.quartzdemo;import org.quartz.Job;import org.quartz.JobDetail;import org.quartz.Scheduler;import org.quartz.SchedulerException;import org.quartz.spi.JobFactory;import org.quartz.spi.TriggerFiredBundle;import javax.enterprise.inject.Any;import javax.enterprise.inject.Instance;import javax.inject.Inject;import javax.inject.Named;public class CdiJobFactory implements JobFactory { @Inject @Any private Instance<Job> jobs; @Override public Job newJob(TriggerFiredBundle triggerFiredBundle, Scheduler scheduler) throws SchedulerException { final JobDetail jobDetail = triggerFiredBundle.getJobDetail(); final Class<? extends Job> jobClass = jobDetail.getJobClass(); for (Job job : jobs) { if (job.getClass().isAssignableFrom(jobClass)) { return job; } } throw new RuntimeException("Cannot create a Job of type " + jobClass); }} |
На данный момент все задания могут использовать внедрение зависимостей и внедрять другие зависимости, включая EJB.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
package pl.codeleak.quartzdemo.ejb;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import javax.ejb.Stateless;@Statelesspublic class SimpleEjb { private static final Logger LOG = LoggerFactory.getLogger(SimpleEjb.class); public void doSomething() { LOG.info("Inside an EJB"); }}package pl.codeleak.quartzdemo;import org.quartz.Job;import org.quartz.JobExecutionContext;import org.quartz.JobExecutionException;import pl.codeleak.quartzdemo.ejb.SimpleEjb;import javax.ejb.EJB;import javax.inject.Named;public class SimpleJob implements Job { @EJB // @Inject will work too private SimpleEjb simpleEjb; @Override public void execute(JobExecutionContext context) throws JobExecutionException { simpleEjb.doSomething(); }} |
Последний шаг — изменить SchedulerBean:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
package pl.codeleak.quartzdemo;import org.quartz.*;import org.quartz.impl.StdSchedulerFactory;import org.quartz.impl.matchers.GroupMatcher;import org.quartz.spi.JobFactory;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import javax.annotation.PostConstruct;import javax.annotation.PreDestroy;import javax.ejb.Singleton;import javax.ejb.Startup;import javax.inject.Inject;@Startup@Singletonpublic class SchedulerBean { private Logger LOG = LoggerFactory.getLogger(SchedulerBean.class); private Scheduler scheduler; @Inject private JobFactory cdiJobFactory; @PostConstruct public void scheduleJobs() { try { scheduler = new StdSchedulerFactory().getScheduler(); scheduler.setJobFactory(cdiJobFactory); JobKey job1Key = JobKey.jobKey("job1", "my-jobs"); JobDetail job1 = JobBuilder .newJob(SimpleJob.class) .withIdentity(job1Key) .build(); TriggerKey tk1 = TriggerKey.triggerKey("trigger1", "my-jobs"); Trigger trigger1 = TriggerBuilder .newTrigger() .withIdentity(tk1) .startNow() .withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(10)) .build(); scheduler.scheduleJob(job1, trigger1); scheduler.start(); printJobsAndTriggers(scheduler); } catch (SchedulerException e) { LOG.error("Error while creating scheduler", e); } } private void printJobsAndTriggers(Scheduler scheduler) throws SchedulerException { // not changed } @PreDestroy public void stopJobs() { // not changed }} |
Примечание. Перед запуском приложения добавьте файл beans.xml в каталог WEB-INF.
|
1
2
3
4
5
6
7
8
9
|
<?xml version="1.0" encoding="UTF-8"?><beans xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee bean-discovery-mode="all"></beans> |
Теперь вы можете запустить сервер и наблюдать за результатами. Сначала была создана работа и триггер:
|
1
2
3
|
12:08:19,592 INFO (MSC service thread 1-3) Quartz Scheduler: MyScheduler12:08:19,612 INFO (MSC service thread 1-3) Found job identified by my-jobs.job112:08:19,616 INFO (MSC service thread 1-3) Found trigger identified by m |
Наша работа выполняется (примерно каждые 10 секунд):
|
1
2
|
12:08:29,148 INFO (MyScheduler_Worker-1) Inside an EJB12:08:39,165 INFO (MyScheduler_Worker-1) Inside an EJB |
Посмотрите также внутри таблиц Quartz, и вы увидите, что они заполнены данными.
Протестируйте приложение
Последнее, что я хотел проверить, было то, как задания запускаются в нескольких случаях. Для моего теста я просто дважды клонировал конфигурацию сервера в IntelliJ и назначил различное смещение порта для каждой новой копии.
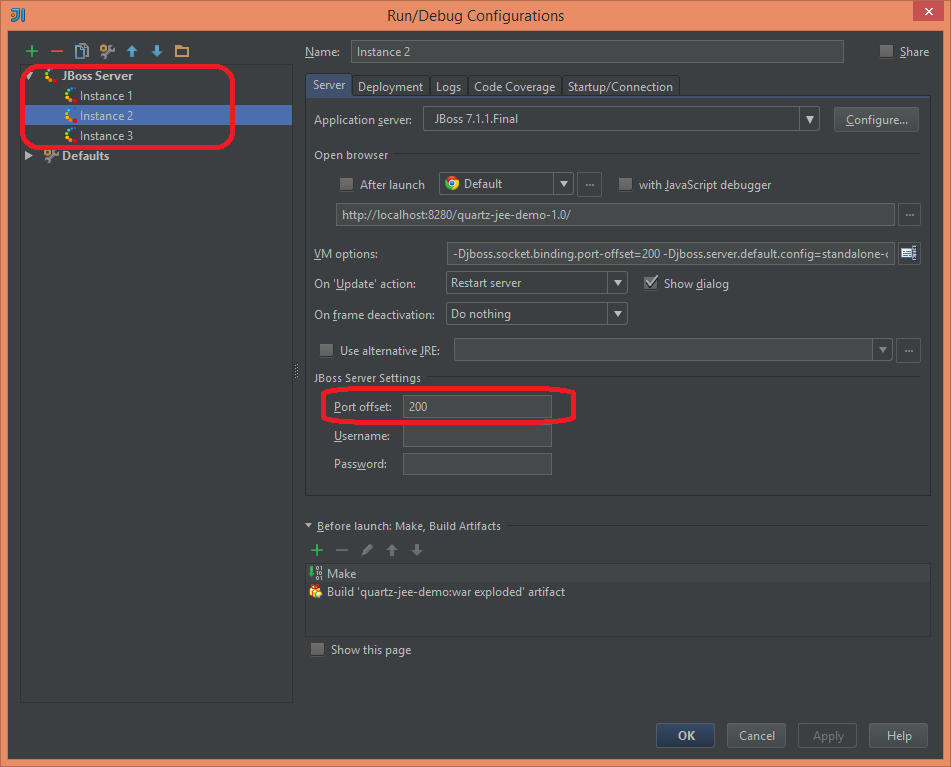
Дополнительные изменения, которые мне нужно было сделать, это изменить создание рабочих мест и триггеров. Поскольку все объекты Quartz хранятся в базе данных, создание одного и того же задания и триггера (с одинаковыми ключами) вызовет исключение:
|
1
|
Error while creating scheduler: org.quartz.ObjectAlreadyExistsException: Unable to store Job : 'my-jobs.job1', because one already exists with this identification. |
Мне нужно было изменить код, чтобы убедиться, что если задание / триггер существует, я его обновлю. Окончательный код метода scheduleJobs для этого теста регистрирует три триггера для одной и той же работы.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
@PostConstructpublic void scheduleJobs() { try { scheduler = new StdSchedulerFactory().getScheduler(); scheduler.setJobFactory(cdiJobFactory); JobKey job1Key = JobKey.jobKey("job1", "my-jobs"); JobDetail job1 = JobBuilder .newJob(SimpleJob.class) .withIdentity(job1Key) .build(); TriggerKey tk1 = TriggerKey.triggerKey("trigger1", "my-jobs"); Trigger trigger1 = TriggerBuilder .newTrigger() .withIdentity(tk1) .startNow() .withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(10)) .build(); TriggerKey tk2 = TriggerKey.triggerKey("trigger2", "my-jobs"); Trigger trigger2 = TriggerBuilder .newTrigger() .withIdentity(tk2) .startNow() .withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(10)) .build(); TriggerKey tk3 = TriggerKey.triggerKey("trigger3", "my-jobs"); Trigger trigger3 = TriggerBuilder .newTrigger() .withIdentity(tk3) .startNow() .withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(10)) .build(); scheduler.scheduleJob(job1, newHashSet(trigger1, trigger2, trigger3), true); scheduler.start(); printJobsAndTriggers(scheduler); } catch (SchedulerException e) { LOG.error("Error while creating scheduler", e); }} |
В дополнение к вышесказанному я добавил запись JobExecutionContext в SimpleJob, чтобы я мог лучше проанализировать результат.
|
01
02
03
04
05
06
07
08
09
10
|
@Overridepublic void execute(JobExecutionContext context) throws JobExecutionException { try { LOG.info("Instance: {}, Trigger: {}, Fired at: {}", context.getScheduler().getSchedulerInstanceId(), context.getTrigger().getKey(), sdf.format(context.getFireTime())); } catch (SchedulerException e) {} simpleEjb.doSomething();} |
После запуска всех трех экземпляров сервера я наблюдал результаты.
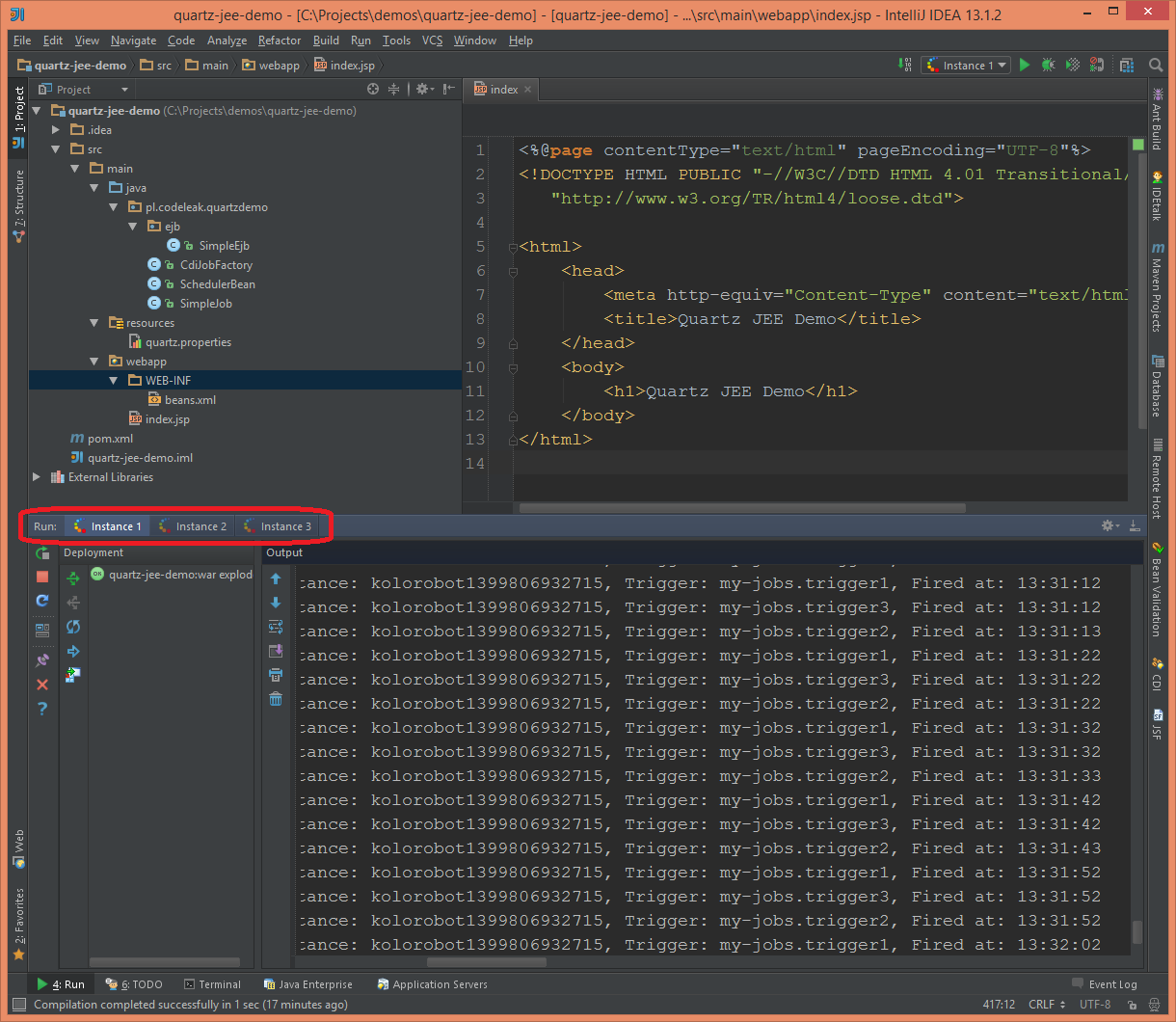
Выполнение работы
Я наблюдал выполнение trigger2 на всех трех узлах, и оно было выполнено на трех из них следующим образом:
|
1
2
3
4
5
|
Instance: kolorobot1399805959393 (instance1), Trigger: my-jobs.trigger2, Fired at: 13:00:09Instance: kolorobot1399805989333 (instance3), Trigger: my-jobs.trigger2, Fired at: 13:00:19Instance: kolorobot1399805963359 (instance2), Trigger: my-jobs.trigger2, Fired at: 13:00:29Instance: kolorobot1399805959393 (instance1), Trigger: my-jobs.trigger2, Fired at: 13:00:39Instance: kolorobot1399805959393 (instance1), Trigger: my-jobs.trigger2, Fired at: 13:00:59 |
Аналогично для других триггеров.
восстановление
После того, как я отключил kolorobot1399805989333 (instance3), через некоторое время я увидел следующее в логах:
|
1
2
|
ClusterManager: detected 1 failed or restarted instances.ClusterManager: Scanning for instance "kolorobot1399805989333"'s failed in-progress jobs. |
Затем я отключил kolorobot1399805963359 (instance2), и снова это то, что я видел в журналах:
|
1
2
3
|
ClusterManager: detected 1 failed or restarted instances.ClusterManager: Scanning for instance "kolorobot1399805963359"'s failed in-progress jobs.ClusterManager: ......Freed 1 acquired trigger(s). |
На данный момент все триггеры были выполнены kolorobot1399805959393 (instance1)
Бег на Wildfly 8
Без каких-либо изменений я мог бы развернуть то же приложение на WildFly 8.0.0. Аналогично JBoss 7.1.1 я добавил модуль MySQL (расположение папки модулей отличается в WildFly 8 — modules/system/layers/base/com/mysql/main . Источник данных и драйвер были определены точно так же, как показано выше. Я создал конфигурацию запуска для WildFly 8:
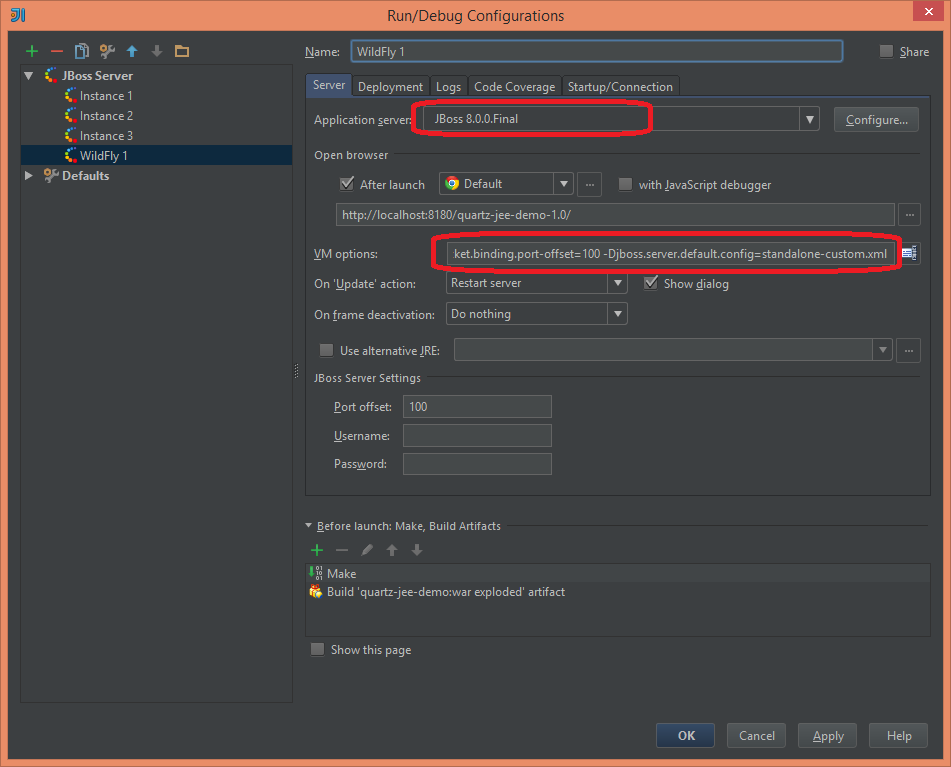
И я запустил приложение, получая те же результаты, что и с JBoss 7.
Я обнаружил, что WildFly предлагает хранилище на основе базы данных для постоянных таймеров EJB , но я еще не исследовал его. Может быть, что-то для другого сообщения в блоге.
Исходный код
- Пожалуйста, найдите исходный код этого сообщения в блоге на GitHub: https://github.com/kolorobot/quartz-jee-demo
| Ссылка: | Как: Кварцевый планировщик с кластеризацией в приложении JEE с MySQL от нашего партнера по JCG Рафаля Боровца в блоге Codeleak.pl . |