Работая консультантом, я до сих пор довольно часто встречаю программистов, которые не совсем понимают JUnit и его правильное использование. Это дало мне идею написать учебник, состоящий из нескольких частей, чтобы объяснить основы с моей точки зрения.
Несмотря на существование нескольких хороших книг и статей о тестировании с помощью инструмента, возможно, практический подход этой мини-серии может быть уместным, чтобы заинтересовать одного или двух дополнительных разработчиков модульным тестированием, что стоило бы усилий.
Обратите внимание, что в этой главе основное внимание уделяется основным методам модульного тестирования, а не функциям JUnit или API. Подробнее о последних будет рассказано в следующих постах. Номенклатура, используемая для описания методов, основана на определениях, представленных в тестовых шаблонах Meszaros xUnit [MES].
Ранее на JUnit в двух словах
Учебное пособие началось с главы Hello World , знакомящей с основами теста: как он написан, выполнен и оценен. Он продолжил со структурой после тестирования , объясняя четыре фазы (настройка, тренировка, проверка и разбор), обычно используемые для структурирования юнит-тестов.
Уроки сопровождались последовательным примером, облегчающим понимание абстрактных концепций. Было продемонстрировано, как постепенно растет контрольный пример — начиная со счастливого пути и заканчивая контрольными тестами, включая ожидаемые исключения.
В целом было подчеркнуто, что тест представляет собой нечто большее, чем простая машина проверки и может также служить своего рода низкоуровневой спецификацией. Следовательно, он должен быть разработан с максимально возможными стандартами кодирования, которые только можно придумать.
зависимости
Для танго нужны двое
пословица
Пример, используемый в этом руководстве, касается написания простого счетчика диапазона чисел, который выдает определенное количество последовательных целых чисел, начиная с заданного значения. Тестовый пример, определяющий поведение модуля, может выглядеть в выдержках примерно так:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
public class NumberRangeCounterTest { private static final int LOWER_BOUND = 1000; private static final int RANGE = 1000; private static final int ZERO_RANGE = 0; private NumberRangeCounter counter = new NumberRangeCounter( LOWER_BOUND, RANGE ); @Test public void subsequentNumber() { int first = counter.next(); int second = counter.next(); assertEquals( first + 1, second ); } @Test public void lowerBound() { int actual = counter.next(); assertEquals( LOWER_BOUND, actual ); } @Test( expected = IllegalStateException.class ) public void exeedsRange() { new NumberRangeCounter( LOWER_BOUND, ZERO_RANGE ).next(); } [...]} |
Обратите внимание, что здесь я приведу довольно компактный тестовый пример, чтобы сэкономить место, например, используя неявную настройку прибора и проверку исключений. Подробное обсуждение шаблонов структурирования тестов см. В предыдущей главе .
Также обратите внимание, что для проверки я использую встроенную функциональность JUnit. Я расскажу о плюсах и минусах конкретных библиотек соответствия ( Hamcrest , AssertJ ) в отдельном посте.
Хотя первоначального описания NumberRangeCounter было достаточно для начала этого урока, внимательный читатель, возможно, заметил, что подход был немного наивным. Рассмотрим, например, что процесс программы может быть прекращен. Чтобы иметь возможность правильно инициализировать счетчик при перезапуске системы, он должен был сохранить хотя бы его последнее состояние.
Однако сохранение состояния счетчика предполагает доступ к ресурсам (база данных, файловая система и т. П.) Через программные компоненты (драйвер базы данных, API файловой системы и т. Д.), Которые не являются частью устройства, или тестируемой системы (SUT). Это означает, что единица зависит от таких компонентов, которые Месарош описывает термином зависимый компонент (DOC) .
К сожалению, это влечет за собой проблемы, связанные с тестированием во многих отношениях:
- В зависимости от компонентов, которые мы не можем контролировать, это может помешать достойной проверке спецификации теста. Подумайте только о реальном веб-сервисе, который иногда может быть недоступен. Это может быть причиной сбоя теста, хотя сама SUT работает правильно.
- Документы также могут замедлить выполнение теста. Чтобы позволить модульным тестам выступать в качестве защитной сети, полный набор тестируемой системы должен выполняться очень часто. Это возможно только в том случае, если каждый тест выполняется невероятно быстро. Снова подумайте о примере веб-службы.
- И последнее, но не менее важное: поведение DOC может неожиданно измениться, например, из-за использования более новой версии сторонней библиотеки. Это показывает, как зависимость от компонентов, которые мы не можем контролировать, делает тест непрочным .
Итак, что мы можем сделать, чтобы обойти эту проблему?
Изоляция — поле SEP юнит-тестера
SEP — это то, что мы не можем видеть или не видим, или наш мозг не позволяет нам видеть, потому что мы думаем, что это проблема S Smebody E lse….
Префект Форд
Поскольку мы не хотим, чтобы наши модульные тесты зависели от поведения DOC, и не хотели, чтобы они были медленными или хрупкими, мы стремимся максимально защитить наш модуль от всех других частей программного обеспечения. Говоря легкомысленно, мы обращаем внимание на эти специфические проблемы в отношении других типов тестов — таким образом, в шутку цитируемое поле SEP .
В общем, этот принцип известен как изоляция SUT и выражает стремление испытывать проблемы отдельно и держать тесты независимыми друг от друга. Практически это подразумевает, что устройство должно быть спроектировано таким образом, чтобы каждый DOC мог быть заменен так называемым Test Double , который является легким вспомогательным компонентом для DOC [MES1].
Что касается нашего примера, мы можем решить не обращаться к базе данных, файловой системе или тому подобному непосредственно из самого устройства. Вместо этого мы можем разделить эту проблему на экранирующий тип интерфейса, не интересуясь тем, как будет выглядеть конкретная реализация.
Хотя этот выбор, безусловно, также является разумным с точки зрения низкоуровневой разработки, он не объясняет, как двойной тест создается, устанавливается и используется на протяжении всего теста. Но прежде чем подробно остановиться на том, как использовать двойные символы, необходимо обсудить еще одну тему.
Косвенные входы и выходы
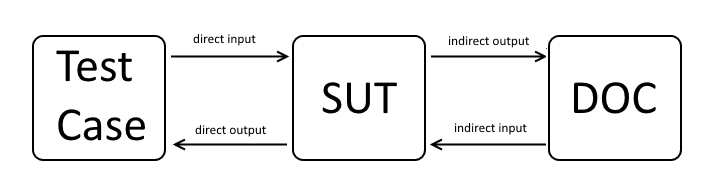
Пока наши усилия по тестированию поставили нас перед прямыми входами и выходами только из SUT. Т.е. каждый экземпляр NumberRangeCounter снабжен нижней границей и значением диапазона (прямой ввод). И после каждого вызова next() SUT возвращает значение или выдает исключение (прямой вывод), используемое для проверки ожидаемого поведения SUT.
Но теперь ситуация становится немного сложнее. Учитывая, что DOC предоставляет последнее значение счетчика для инициализации SUT, результат next() зависит от этого значения. Если DOC обеспечивает вход SUT таким способом, мы говорим о косвенных входах .
И наоборот, предполагая, что каждый вызов next() должен сохранять текущее состояние счетчика, у нас нет шансов проверить это через прямые выходы SUT. Но мы могли бы проверить, что состояние счетчика было передано DOC. Такое делегирование обозначается как косвенный результат .
С этим новым знанием мы должны быть готовы продолжить пример NumberRangeCounter .
Управление косвенными входами с заглушками
Из того, что мы узнали, было бы, вероятно, хорошей идеей разделить сохранение состояния счетчика на собственный тип. Этот тип изолировал бы SUT от фактической реализации хранилища, так как с точки зрения SUT нас не интересует, как на самом деле решается проблема сохранения . По этой причине мы представляем интерфейс CounterStorage .
Хотя реальной реализации хранилища пока нет, мы можем вместо этого использовать тестовый двойной. На этом этапе создать тестовый тип double тривиально, поскольку в интерфейсе еще нет методов.
|
1
2
|
public class CounterStorageDouble implements CounterStorage {} |
Чтобы предоставить хранилище для NumberRangeCounter в слабосвязанной форме, мы можем использовать внедрение зависимостей . Улучшение настройки неявного устройства с помощью двойного теста хранилища и его внедрения в SUT может выглядеть следующим образом:
|
1
2
3
4
5
6
7
|
private CounterStorage storage; @Before public void setUp() { storage = new CounterStorageDouble(); counter = new NumberRangeCounter( storage, LOWER_BOUND, RANGE ); } |
После исправления ошибок компиляции и запуска всех тестов полоса должна оставаться зеленой, поскольку мы еще не изменили поведение. Но теперь мы хотим, чтобы первый вызов NumberRangeCounter#next() состояние хранилища. Если хранилище предоставляет значение n пределах определенного диапазона счетчика, первый вызов next() также должен вернуть n , что выражается следующим тестом:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
private static final int IN_RANGE_NUMBER = LOWER_BOUND + RANGE / 2; [...] @Test public void initialNumberFromStorage() { storage.setNumber( IN_RANGE_NUMBER ); int actual = counter.next(); assertEquals( IN_RANGE_NUMBER, actual ); } |
Наш двойной тест должен обеспечить детерминированный косвенный ввод, в нашем случае IN_RANGE_NUMBER . Из-за этого оно снабжено значением, используя setNumber(int) . Но поскольку хранилище не используется, тест не пройден. Чтобы изменить это, самое время объявить первый метод CounterStorage :
|
1
2
3
|
public interface CounterStorage { int getNumber();} |
Что позволяет нам реализовать двойной тест:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
public class CounterStorageDouble implements CounterStorage { private int number; public void setNumber( int number ) { this.number = number; } @Override public int getNumber() { return number; }} |
Как вы можете видеть, двойной реализует getNumber() , возвращая значение конфигурации, setNumber(int) . Тестовый двойник, который обеспечивает косвенные входные данные таким образом, называется заглушкой . Теперь мы сможем реализовать ожидаемое поведение NumberRangeCounter и пройти тест.
Если вы думаете, что get / setNumber создают плохие имена для описания поведения хранилища, я согласен. Но это облегчает эволюцию поста. Пожалуйста, чувствуйте себя приглашенными сделать хорошо продуманные предложения по рефакторингу …
Непрямая проверка вывода со шпионами
Чтобы иметь возможность восстановить экземпляр NumberRangeCounter после перезапуска системы, мы ожидаем, что каждое изменение состояния счетчика будет сохраняться. Этого можно достичь, отправляя текущее состояние в хранилище каждый раз, когда происходит вызов next() . Из-за этого мы добавляем метод setNumber(int) к нашему типу DOC:
|
1
2
3
4
|
public interface CounterStorage { int getNumber(); void setNumber( int number );} |
Какое странное совпадение, что новый метод имеет ту же сигнатуру, что и для настройки нашей заглушки! После внесения изменений в этот метод с помощью @Override можно легко использовать нашу настройку прибора также для следующего теста:
|
1
2
3
4
5
6
|
@Test public void storageOfStateChange() { counter.next(); assertEquals( LOWER_BOUND + 1, storage.getNumber() ); } |
По сравнению с исходным состоянием мы ожидаем, что новое состояние счетчика будет увеличено на единицу после вызова next() . Более важно, что мы ожидаем, что это новое состояние будет передано в DOC хранилища в качестве косвенного вывода. К сожалению, мы не являемся свидетелями фактического вызова, поэтому мы записываем результат вызова в локальной переменной нашего двойника.
Фаза проверки позволяет сделать вывод, что правильные косвенные выходные данные были переданы в DOC, если записанное значение соответствует ожидаемому. Состояние записи и / или поведение для последующей проверки, описанное выше в простейшем виде, также обозначается как шпионаж. Поэтому двойной тест с использованием этой техники называется шпионом .
Что насчет насмешек?
Есть еще одна возможность проверить косвенный вывод next() с помощью макета . Наиболее важной характеристикой этого типа double является то, что косвенная проверка вывода выполняется внутри метода делегирования. Кроме того, это позволяет гарантировать, что ожидаемый метод был фактически вызван:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
public class CounterStorageMock implements CounterStorage { private int expectedNumber; private boolean done; public CounterStorageMock( int expectedNumber ) { this.expectedNumber = expectedNumber; } @Override public void setNumber( int actualNumber ) { assertEquals( expectedNumber, actualNumber ); done = true; } public void verify() { assertTrue( done ); } @Override public int getNumber() { return 0; }} |
Экземпляр CounterStorageMock настраивается с ожидаемым значением с помощью параметра конструктора. Если setNumber(int) , немедленно проверяется, соответствует ли данное значение ожидаемому. Флаг хранит информацию о том, что метод был вызван. Это позволяет проверить фактический вызов с помощью метода verify() .
И вот как может выглядеть тест storageOfStateChange с использованием макета:
|
01
02
03
04
05
06
07
08
09
10
11
|
@Test public void storageOfStateChange() { CounterStorageMock storage = new CounterStorageMock( LOWER_BOUND + 1 ); NumberRangeCounter counter = new NumberRangeCounter( storage, LOWER_BOUND, RANGE ); counter.next(); storage.verify(); } |
Как видите, в тесте не осталось подтверждения спецификации. И кажется странным, что обычная тестовая структура была немного искажена. Это связано с тем, что условие проверки указывается до фазы тренировки в середине настройки прибора. На этапе проверки остается только фиктивная проверка вызова.
Но взамен макет обеспечивает точную трассировку стека в случае неудачной проверки поведения, что может облегчить анализ проблемы. Если вы снова посмотрите на шпионское решение, вы поймете, что трассировка сбоя будет указывать только на проверочный раздел теста. Не будет никакой информации о строке производственного кода, которая фактически вызвала сбой теста.
Это совершенно другое с насмешкой. Трассировка позволила бы нам точно идентифицировать позицию, где был вызван setNumber(int) . Имея эту информацию, мы могли бы легко установить точку останова и отладить проблемный вопрос.
Из-за объема этого поста я ограничился тестом двойного введения на пнях, шпионах и издевательствах. Для краткого объяснения других типов вы можете взглянуть на статью TestDouble Мартина Фаулера , но подробное объяснение всех типов и их вариаций можно найти в книге Meszaros ‘xUnit Test Patterns [MES].
Хорошее сравнение между шуткой и шпионом на основе тестовых двойных фреймворков (см. Следующий раздел) можно найти в книге Томека Качановского « Практическое модульное тестирование с JUnit и Mockito» [KAC].
После прочтения этого раздела у вас может сложиться впечатление, что написание всех этих двойников — утомительная работа. Не удивительно, что библиотеки были написаны для того, чтобы значительно упростить двойную обработку.
Тест двойных рамок — Земля Обетованная?
Если у вас есть только молоток, все выглядит как гвоздь
пословица
Есть несколько фреймворков, разработанных для облегчения задачи использования двойников теста. К сожалению, эти библиотеки не всегда хорошо справляются с точной двойной терминологией теста . В то время как, например, JMock и EasyMock фокусируются на мошенничестве , Mockito , несмотря на свое имя, ориентировано на шпионов. Возможно, именно поэтому большинство людей говорят о насмешках , независимо от того, какой тип двойного числа они на самом деле используют.
Тем не менее есть признаки того, что в настоящее время Mockito является предпочтительным испытательным двойным инструментом. Я предполагаю, что это потому, что он обеспечивает хорошее чтение API интерфейса и немного компенсирует недостаток шпионов, упомянутых выше, предоставляя подробные сообщения об ошибках проверки.
Не вдаваясь в подробности, я предоставляю версию storageOfStateChange() , который использует Mockito для создания шпионов и проверки теста. Обратите внимание, что mock и Mockito являются статическими методами типа Mockito . Обычной практикой является использование статического импорта с выражениями Mockito для улучшения читабельности:
|
01
02
03
04
05
06
07
08
09
10
|
@Test public void storageOfStateChange() { CounterStorage storage = mock( CounterStorage.class ); NumberRangeCounter counter = new NumberRangeCounter( storage, LOWER_BOUND, RANGE ); counter.next(); verify( storage ).setNumber( LOWER_BOUND + 1 ); } |
Много было написано о том, использовать ли такие инструменты или нет. Роберт К. Мартин, например, предпочитает рукописные двойники, а Майкл Болдишар даже считает насмешливые рамки вредными . Последний описывает просто простое злоупотребление, на мой взгляд, и на этот раз я не согласен с высказыванием Мартина «Написание этих издевательств тривиально».
Я сам использовал рукописные двойники до того, как открыл Mockito. Мгновенно я был продан беглому синтаксису заглушки, интуитивному способу проверки, и я посчитал, что это облегчение, чтобы избавиться от этих двойных типов. Но это, безусловно, в глазах смотрящего.
Тем не менее, я испытал, что двойные инструменты теста побуждают разработчиков переусердствовать. Например, очень легко заменить сторонние компоненты, которые в противном случае могут быть дорогостоящими, на дубликаты. Но это считается плохой практикой, и Стив Фриман и Нат Прайс подробно объясняют, почему вы должны имитировать только те типы, которые принадлежат вам [FRE_PRY].
Сторонний код требует интеграционных тестов и уровня абстрагирующего адаптера . Последнее на самом деле является тем, что мы указали в нашем примере, представляя CounterStorage . А поскольку у нас есть адаптер, мы можем безопасно заменить его на двойной.
Вторая ловушка, в которую легко попасть, — это написание тестов, где двойной тест возвращает другой двойной тест. Если вы дойдете до этого, вам следует пересмотреть дизайн кода, с которым вы работаете. Это, вероятно, нарушает закон Деметры , что означает, что может быть что-то не так с тем, как ваши объекты связаны друг с другом.
И последнее, но не менее важное: если вы собираетесь использовать тестовую двойную среду, вы должны помнить, что это, как правило, долгосрочное решение, затрагивающее всю команду. Вероятно, не самая лучшая идея смешивать разные фреймворки из-за единого стиля кодирования, и даже если вы используете только один, каждый (новый) член должен изучить API, специфичный для инструмента.
Прежде чем вы начнете широко использовать удвоение теста, вы можете прочитать « Мучения Мартина Фаулера — это не заглушки» , в которых сравниваются классические и мокистские тесты, или « Когда имитировать» Роберта К. Мартина, в котором вводится некоторая эвристика, позволяющая найти золотое соотношение между двойными и слишком большими двойники. Или, как выразился Томек Качановский:
«Рад, что ты можешь все высмеять, а? Замедлите и убедитесь, что вам действительно нужно проверить взаимодействие. Скорее всего, нет. [KAC1]
Вывод
В этой главе JUnit в двух словах обсуждались последствия модульных зависимостей для тестирования. Он проиллюстрировал принцип изоляции и показал, как его можно применить на практике, заменив DOC тестовыми двойниками. В этом контексте была представлена концепция косвенных входов и выходов, и была описана ее актуальность для тестирования.
Этот пример углубил знания практическими примерами и ввел несколько тестовых двойных типов и их назначение. Наконец, краткое объяснение тестовых двойных фреймворков и их плюсов и минусов завершило эту главу. Надеемся, что он был достаточно сбалансирован, чтобы обеспечить понятный обзор темы, не будучи тривиальным. Предложения по улучшению, конечно, высоко ценятся.
В следующем посте руководства будут рассмотрены функции JUnit, такие как Runners и Rules, и показано, как их использовать, в следующем примере.
использованная литература
[MES] Тестовые таблицы xUnit, Джерард Месарос, 2007
[MES1] Тестовые таблицы xUnit, глава 5, Принцип: изолировать SUT, Джерард Месарос, 2007
[KAC] Практическое модульное тестирование с JUnit и Mockito, Приложение C. Test Spy vs. Mock, Томек Качановский, 2013
[KAC1] Плохие тесты, хорошие тесты, глава 4, Ремонтопригодность, Томек Качановский, 2013
[FRE_PRY] Растущее объектно-ориентированное программное обеспечение, руководствуясь тестами, глава 8, Стив Фриман, Нат Прайс, 2010
| Ссылка: | JUnit в двух словах: тестовая изоляция от нашего партнера JCG Фрэнка Аппеля в блоге Code Affine . |