Одной из последних функций в JPA 2.1 является возможность задавать планы выборки с использованием графов объектов. Это полезно, поскольку позволяет настраивать данные, полученные с помощью запроса или операции поиска. При работе с приложениями среднего и большого размера распространено отображение данных из одной и той же сущности разными и разными способами. В других случаях вам просто нужно выбрать наименьший набор информации для оптимизации производительности вашего приложения.
У вас нет многих механизмов для контроля того, что загружено или нет в сущности JPA. Вы можете использовать выборку EAGER / LAZY , но эти определения в значительной степени статичны. Вы не смогли изменить их поведение при получении данных, а это означает, что вы застряли с тем, что было определено в объекте. Их изменение в середине разработки — кошмар, так как это может привести к неожиданному поведению запросов. Еще один способ управления загрузкой — написание конкретных запросов JPQL. Обычно вы findEntityWithX очень похожие запросы и следующие методы: findEntityWithX , findEntityWithY , findEntityWithXandY и так далее.
До JPA 2.1 реализации уже поддерживали нестандартный способ загрузки данных, аналогичный Entity Graphs. У вас есть профили извлечения Hibernate , группы извлечения OpenJPA и группы извлечения EclipseLink . Было логично иметь такое поведение в спецификации. Это позволяет вам более точно и детально контролировать то, что вам нужно загрузить, используя стандартный API.
пример
Рассмотрим следующий граф сущностей:
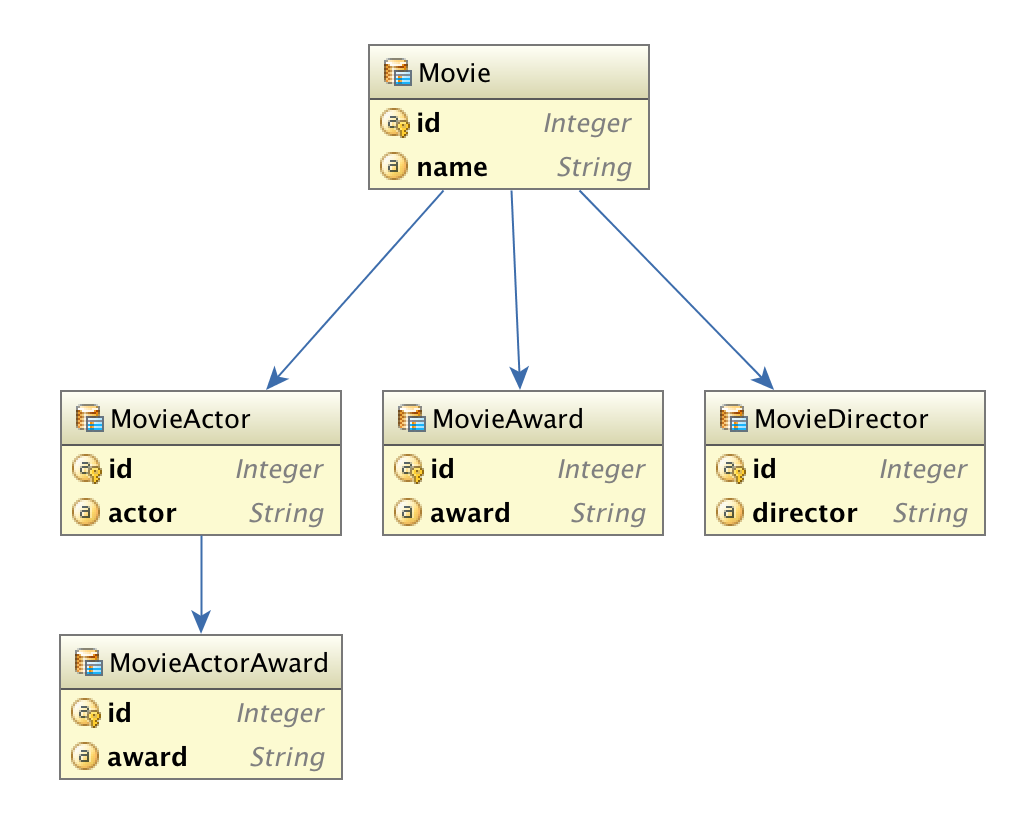
(Вероятно, отношения должны быть от N до N, но давайте сделаем это проще).
А у сущности Кино есть следующее определение:
Movie.java
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
@Entity@Table(name = "MOVIE_ENTITY_GRAPH")@NamedQueries({ @NamedQuery(name = "Movie.findAll", query = "SELECT m FROM Movie m")})@NamedEntityGraphs({ @NamedEntityGraph( name = "movieWithActors", attributeNodes = { @NamedAttributeNode("movieActors") } ), @NamedEntityGraph( name = "movieWithActorsAndAwards", attributeNodes = { @NamedAttributeNode(value = "movieActors", subgraph = "movieActorsGraph") }, subgraphs = { @NamedSubgraph( name = "movieActorsGraph", attributeNodes = { @NamedAttributeNode("movieActorAwards") } ) } )})public class Movie implements Serializable { @Id private Integer id; @NotNull @Size(max = 50) private String name; @OneToMany @JoinColumn(name = "ID") private Set<MovieActor> movieActors; @OneToMany(fetch = FetchType.EAGER) @JoinColumn(name = "ID") private Set<MovieDirector> movieDirectors; @OneToMany @JoinColumn(name = "ID") private Set<MovieAward> movieAwards;} |
Если присмотреться к сущности, мы увидим, что у нас есть три отношения от 1 до N, и movieDirectors настроен для быстрой загрузки. Другие отношения устанавливаются по умолчанию в Ленивую стратегию загрузки. Если мы хотим изменить это поведение, мы можем определить различные модели загрузки, используя аннотацию @NamedEntityGraph . Просто установите имя для его идентификации, а затем используйте @NamedAttributeNode чтобы указать, какие атрибуты корневого объекта вы хотите загрузить. Для отношений вам нужно установить имя для подграфа, а затем использовать @NamedSubgraph . В деталях:
Аннотации
Entity Graph фильмWithActors
|
1
2
3
4
5
6
|
@NamedEntityGraph( name = "movieWithActors", attributeNodes = { @NamedAttributeNode("movieActors") }) ) |
Это определяет Entity Graph с именем movieWithActors и указывает, что отношение movieActors должно быть загружено.
Entity Graph фильмWithActorsAndAwards
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
@NamedEntityGraph( name = "movieWithActorsAndAwards", attributeNodes = { @NamedAttributeNode(value = "movieActors", subgraph = "movieActorsGraph") }, subgraphs = { @NamedSubgraph( name = "movieActorsGraph", attributeNodes = { @NamedAttributeNode("movieActorAwards") } ) }) |
Это определяет Entity Graph с именем movieWithActorsAndAwards и указывает, что должны быть загружены отношения movieActors . Кроме того, он также указывает, что отношение movieActors должно загружать movieActorAwards .
Обратите внимание, что мы не указываем атрибут id в графе сущностей. Это потому, что первичные ключи всегда выбираются независимо от того, что указано. Это также верно для атрибутов версии.
Советы
Чтобы использовать графы сущностей, определенные в запросе, вы должны установить их как подсказку. Вы можете использовать два свойства подсказки, и они также влияют на способ загрузки данных.
Вы можете использовать javax.persistence.fetchgraph и этот javax.persistence.fetchgraph будет обрабатывать все указанные атрибуты в FetchType.EAGER сущностей как FetchType.EAGER . Атрибуты, которые не указаны, обрабатываются как FetchType.LAZY .
Другая подсказка свойства — это javax.persistence.loadgraph . Это будет обрабатывать все указанные атрибуты в FetchType.EAGER сущностей как FetchType.EAGER . Атрибуты, которые не указаны, обрабатываются с указанным или заданным по умолчанию FetchType .
Для упрощения и на основе нашего примера при применении Entity Graph movieWithActors :
| По умолчанию / указано | javax.persistence.fetchgraph | javax.persistence.loadgraph | |
|---|---|---|---|
| movieActors | LAZY | EAGER | EAGER |
| movieDirectors | EAGER | LAZY | EAGER |
| movieAwards | LAZY | LAZY | LAZY |
Теоретически, так должно быть, как выбираются разные отношения. На практике это может не сработать, потому что в спецификации JPA 2.1 также указано, что поставщик JPA всегда может получить дополнительное состояние сверх того, которое указано в графе сущностей. Это связано с тем, что провайдер может оптимизировать данные для загрузки и в конечном итоге загружать гораздо больше материала. Вам нужно проверить поведение вашего провайдера. Например, Hibernate всегда выбирает все, что указано как EAGER, даже при использовании подсказки javax.persistence.fetchgraph . Проверьте проблему здесь .
запрос
Выполнить запрос легко. Вы делаете это, как обычно, но просто вызываете setHint для объекта Query :
Подсказка Entity Graph
|
1
2
3
4
5
6
7
8
|
@PersistenceContextprivate EntityManager entityManager;public List<Movie> listMovies(String hint, String graphName) { return entityManager.createNamedQuery("Movie.findAll") .setHint(hint, entityManager.getEntityGraph(graphName)) .getResultList();} |
Чтобы получить Entity Graph, который вы хотите использовать в своем запросе, вам нужно вызвать метод getEntityGraph в EntityManager и передать имя. Тогда воспользуйтесь ссылкой в подсказке. Подсказка должна быть либо javax.persistence.fetchgraph либо javax.persistence.loadgraph .
программный
Аннотации могут стать многословными, особенно если у вас есть большие графы или много графов сущностей. Вместо использования аннотаций вы можете программно определять графы объектов. Посмотрим как:
Начнем с добавления статической метамодели Entity Class:
Movie_.java
|
1
2
3
4
5
6
7
8
|
@StaticMetamodel(Movie.class)public abstract class Movie_ { public static volatile SingularAttribute<Movie, Integer> id; public static volatile SetAttribute<Movie, MovieAward> movieAwards; public static volatile SingularAttribute<Movie, String> name; public static volatile SetAttribute<Movie, MovieActor> movieActors; public static volatile SetAttribute<Movie, MovieDirector> movieDirectors;} |
Это на самом деле не нужно, вы можете ссылаться на атрибуты по их именам строк, но это обеспечит вам безопасность типов.
Граф программных объектов
|
1
2
3
4
|
EntityGraph<Movie> fetchAll = entityManager.createEntityGraph(Movie.class);fetchAll.addSubgraph(Movie_.movieActors);fetchAll.addSubgraph(Movie_.movieDirectors);fetchAll.addSubgraph(Movie_.movieAwards); |
Этот Entity Graph указывает, что все отношения Entity должны быть загружены. Теперь вы можете настроить ваши собственные варианты использования.
Ресурсы
Вы можете найти этот пример кода в примерах Java EE на Github. Проверьте это здесь .
Дополнительное примечание: в настоящее время в EclipseLink / Glassfish есть ошибка, которая препятствует javax.persistence.loadgraph подсказки javax.persistence.loadgraph . Проверьте проблему здесь .
Вывод
Entity Graphs заполнили пробел, отсутствующий в спецификации JPA. Это дополнительный механизм, который помогает вам запрашивать то, что вам действительно нужно. Они также помогают вам улучшить производительность вашего приложения. Но будьте умны при их использовании. Там может быть лучший способ.
| Ссылка: | JPA Entity Graphs от нашего партнера JCG Роберто Кортеса в блоге |