Эта статья предоставит вам учебное пособие, позволяющее определить, сколько и где места кучи Java остается в потоках Java вашего активного приложения. Будет представлен реальный пример из производственной среды Oracle Weblogic 10.0, чтобы вы могли лучше понять процесс анализа.
Мы также попытаемся продемонстрировать, что чрезмерная проблема с сборкой мусора или объемом памяти кучи Java часто не вызвана истинными утечками памяти, а скорее из-за шаблонов выполнения потоков и большого количества недолговечных объектов. 
Фон
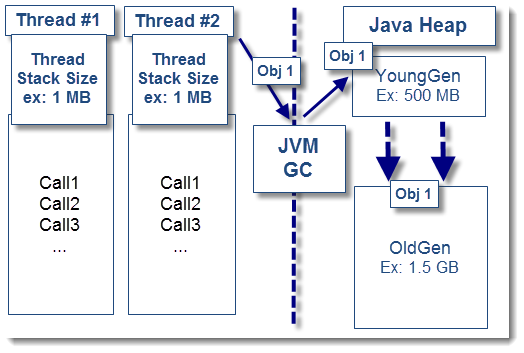
Как вы могли видеть из моей предыдущей обзорной статьи о JVM , потоки Java являются частью основ JVM. Ваше пространство памяти кучи Java управляется не только статическими и долгоживущими объектами, но также недолговечными объектами.
Проблемы OutOfMemoryError часто ошибочно предполагаются из-за утечек памяти. Мы часто пропускаем неисправные шаблоны выполнения потоков и недолговечные объекты, которые они «сохраняют» в куче Java, пока их выполнение не будет завершено. В этом проблемном сценарии:
- Ваши «ожидаемые» недолговечные объекты / объекты без состояния (XML, полезная нагрузка данных JSON и т. Д.) Слишком долго задерживаются потоками (конфликт блокировки потоков, огромная полезная нагрузка данных, медленное время отклика от удаленной системы и т. Д.)
- В конечном итоге такие недолговечные объекты переносятся сборщиком мусора в пространство долгоживущих объектов, например OldGen / tenured space
- Как побочный эффект, это заставляет пространство OldGen быстро заполняться, увеличивая частоту Full GC (основные коллекции)
- В зависимости от серьезности ситуации это может привести к чрезмерной сборке мусора GC, увеличению времени приостановки JVM и, в конечном итоге, OutOfMemoryError: пространство кучи Java
- Ваше приложение закрыто, теперь вы озадачены тем, что происходит
- Наконец, вы думаете, либо увеличить кучу Java, либо искать утечки памяти … вы действительно на правильном пути?
В приведенном выше сценарии вам нужно посмотреть на шаблоны выполнения потоков и определить, сколько памяти каждый из них сохраняет в данный момент времени.
Хорошо, я получаю картину, но как насчет размера стека потока?
Очень важно избежать путаницы между размером стека потоков и сохранением памяти Java. Размер стека потоков — это специальное пространство памяти, используемое JVM для хранения каждого вызова метода. Когда поток вызывает метод A, он «помещает» вызов в стек. Если метод A вызывает метод B, он также помещается в стек. Как только выполнение метода завершается, вызов «выталкивается» из стека.
Объекты Java, созданные в результате таких вызовов потоковых методов, размещаются в пространстве кучи Java. Увеличение размера стека потока определенно не будет иметь никакого эффекта. Настройка размера стека потока обычно требуется при работе с java.lang.stackoverflowerror или OutOfMemoryError: невозможно создать новые проблемы с собственным потоком .
Тематическое исследование и проблемный контекст
Следующий анализ основан на реальной проблеме производства, которую мы исследовали недавно.
- В производственной среде Weblogic 10.0 наблюдалось сильное снижение производительности после некоторых изменений в пользовательском веб-интерфейсе (с использованием Google Web Toolkit и JSON в качестве полезных данных)
- Первоначальный анализ выявил несколько случаев OutOfMemoryError: ошибки пространства кучи Java наряду с чрезмерной сборкой мусора. Файлы дампа кучи Java были сгенерированы автоматически (-XX: + HeapDumpOnOutOfMemoryError) после событий OOM
- Подробный анализ: журналы gc подтверждают полное истощение 32-разрядного пространства HotSpot JVM OldGen (емкость 1 ГБ)
- Снимки дампа потока также были созданы до и во время проблемы
- Единственное решение проблемы, доступное в то время, было перезапустить уязвимый сервер Weblogic, когда проблема обнаружена
- В конечном итоге был выполнен откат изменений, который разрешил ситуацию
Команда сначала заподозрила проблему утечки памяти из введенного нового кода.
Анализ дампа потока: поиск подозреваемых …
Первым шагом анализа, который мы сделали, было выполнение анализа сгенерированных данных дампа потока. Дамп потока часто будет показывать вам потоки виновника, выделяющие память в куче Java. Он также покажет любой запирающийся или застрявший поток, пытающийся отправить и получить данные с удаленной системы.
Первым примером, который мы заметили, была хорошая корреляция между событиями OOM и потоками STUCK, наблюдаемыми на управляемых серверах Weblogic (процессы JVM). Найдите ниже найденного шаблона первичной нити:
|
1
2
3
4
5
6
7
8
9
|
<10-Dec-2012 1:27:59 o'clock PM EST> <Error> <BEA-000337><[STUCK] ExecuteThread: '22' for queue:'weblogic.kernel.Default (self-tuning)'has been busy for '672' seconds working on the requestwhich is more than the configured time of '600' seconds. |

Как видите, вышеприведенный поток выглядит как STUCK или занимает очень много времени для чтения и получения ответа JSON от удаленного сервера. Как только мы нашли этот шаблон, следующим шагом было соотнести этот результат с анализом дампа кучи JVM и определить, сколько памяти эти застрявшие потоки извлекают из кучи Java.
Анализ дампа кучи: открытые объекты выставлены!
Анализ дампа кучи Java был выполнен с использованием MAT . Теперь мы перечислим различные этапы анализа, которые позволили нам точно определить объем оставшейся памяти и источник.
1. Загрузите дамп кучи HotSpot JVM
2. Выберите представление HISTOGRAM и примените фильтр «ExecuteThread».
* ExecuteThread — это класс Java, используемый ядром Weblogic для создания и исполнения потоков *
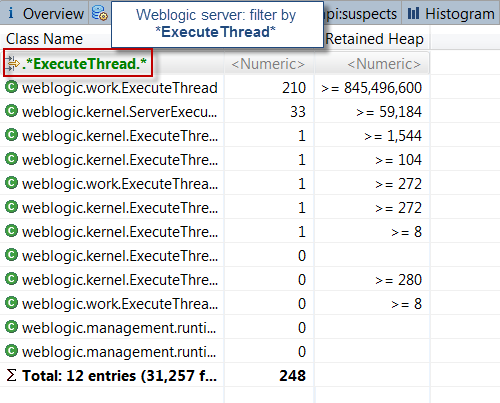
Как видите, это мнение было довольно показательным. Всего мы видим 210 созданных тем Weblogic. Общий объем сохраняемой памяти этих потоков составляет 806 МБ. Это очень важно для 32-разрядного процесса JVM с 1 ГБ пространства OldGen. Одно только это представление говорит нам, что ядро проблемы и удержания памяти происходит от самих потоков.
3. Глубокое погружение в анализ объема памяти потока
Следующим шагом было глубокое погружение в сохранение памяти потока. Для этого просто щелкните правой кнопкой мыши класс ExecuteThread и выберите: Список объектов> с исходящими ссылками.
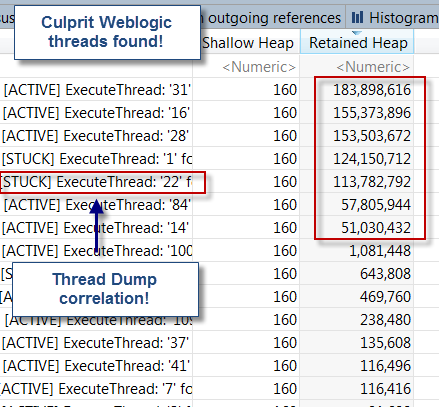
Как вы можете видеть, мы смогли сопоставить потоки STUCK из анализа дампа потоков с высоким удержанием памяти из анализа дампа кучи. Открытие было довольно удивительным.
4. Поток Java Локальные переменные идентификации
Последний этап анализа потребовал от нас расширения нескольких образцов потоков и понимания основного источника сохранения памяти.
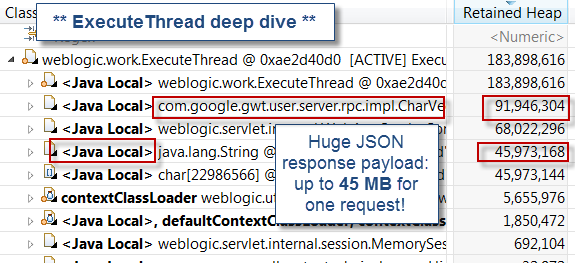
Как вы можете видеть, этот последний шаг анализа выявил огромную полезную нагрузку данных ответов JSON в качестве основной причины. Этот шаблон также был обнаружен ранее с помощью анализа дампа потоков, где мы обнаружили, что нескольким потокам требуется очень много времени, чтобы прочитать и получить ответ JSON; явный признак огромного объема данных.
Важно отметить, что недолговечные объекты, созданные с помощью локальных переменных метода, будут отображаться в анализе дампа кучи. Однако некоторые из них будут видны только из своих родительских потоков, поскольку на них не ссылаются другие объекты, как в этом случае. Вам также необходимо проанализировать трассировку стека потоков, чтобы определить истинного вызывающего абонента, после чего следует выполнить проверку кода для подтверждения основной причины.
После этого наш отдел доставки смог определить, что недавние ошибки в коде JSON приводили в некоторых случаях к огромной полезной нагрузке данных JSON до 45 МБ +. Учитывая тот факт, что в этой среде используется 32-разрядная JVM с только 1 ГБ пространства OldGen, вы можете понять, что для запуска серьезного снижения производительности достаточно всего нескольких потоков.
Это исследование наглядно демонстрирует важность правильного планирования емкости и анализа кучи Java, включая объем памяти, сохраняемой из активного приложения и потоков контейнера Java EE.
Обучение это опыт. Все остальное просто информация
Я надеюсь, что эта статья помогла вам понять, как вы можете точно определить объем памяти кучи Java, сохраняемой вашими активными потоками, путем объединения анализа дампа потока и дампа кучи. Теперь эта статья останется просто словами, если вы не будете экспериментировать, поэтому я настоятельно рекомендую вам потратить некоторое время на изучение этого процесса анализа для ваших приложений.
Ссылка: Java Thread: анализ памяти оставлен нашим партнером по JCG Пьером-Хьюгом Шарбонно в блоге « Образцы поддержки Java EE и учебник по Java» .