Поскольку Java-приложения часто используются в самых разных операционных системах и средах, разработчики Java нередко сталкиваются с проблемами, связанными с вводом и выводом символов. Сообщения в блоге, посвященные этим вопросам, включают «Ужас полицейского: локали по умолчанию», «Наборы символов по умолчанию» и «Часовые пояса по умолчанию» ; Аннотирование данных JDK по умолчанию ; Проблемы кодирования: решения для Linux и Java-приложений ; Глупые Струны Java ; Java: грубое руководство по кодированию символов ; и этот пост со слишком длинным названием, чтобы перечислять здесь .
За прошедшие годы в Java было сделано несколько улучшений, чтобы уменьшить эти проблемы, но все еще иногда возникают проблемы, когда неявно используется кодировка по умолчанию. Книга Java Puzzlers содержит головоломку (Puzzle # 18), описывающую причуды, связанные с «капризами кодировки по умолчанию» в Java.
Принимая во внимание все эти проблемы, связанные с набором символов по умолчанию в Java, приветствуется наличие проекта JEP « Использовать UTF-8 в качестве набора символов по умолчанию » ( JDK-8187041 ). В дополнение к потенциальному решению проблем, связанных с набором символов по умолчанию, этот JEP уже предоставляет хороший обзор того, что представляют собой эти проблемы и альтернативы для решения этих проблем сегодня. В разделе «Мотивация» JEP в настоящее время суммируется важность этого JEP: «API-интерфейсы, использующие кодировку по умолчанию, представляют опасность для разработчиков, впервые знакомых с платформой Java», и «также являются ошибкой для опытных разработчиков».
Проблемы с набором символов по умолчанию усложняются из-за разного использования наборов символов и различий в подходах, доступных в настоящее время в API JDK, которые приводят к нескольким «значениям по умолчанию». Вот разбивка вопросов для рассмотрения.
- Кодировка «по умолчанию», описывающая набор символов содержимого файла, потенциально отличается от кодировки «по умолчанию», описывающей набор символов путей к файлам .
- Системное свойство Java
file.encodingуказываетfile.encodingсимволов по умолчанию для содержимого файла, а его настройка — это то, что возвращает java.nio.charsets.Charset.defaultCharset () . - Системное свойство Java
sun.jnu.encodingуказывает кодировку по умолчанию для путей к файлам и, согласно этому сообщению , «первоначально использовалось только для Windows, но теперь у нас есть случаи, когда оно может отличаться отfile.encodingна других платформах». - Что касается этих системных свойств (
file.encodingиsun.jnu.encoding), проект JEP в настоящее время утверждает (я добавил выделение ): «Значение этих системных свойств может быть переопределено в командной строке, хотя это никогда не поддерживалось . »
- Системное свойство Java
- Существует два типа «по умолчанию», относящихся к наборам символов, используемым для чтения / записи содержимого файла.
- Некоторые методы JDK не позволяют указывать кодировку и всегда принимают кодировку «по умолчанию» UTF-8 только для этого конкретного метода и независимо от локали или конфигурации системы.
- Некоторые методы JDK не позволяют указывать кодировку и принимают общесистемную («платформу») кодировку «по умолчанию» (связанную с
file.encoding/Charset.defaultCharset()описанной выше), основанную на локали и конфигурации системы.
Проект JEP « Использовать UTF-8 в качестве кодировки по умолчанию » поможет решить проблемы, связанные с различными типами «по умолчанию», когда речь идет о кодировке, используемой по умолчанию для чтения и записи содержимого файла. Например, он удалит потенциальный конфликт, который может возникнуть при записи файла с использованием метода, который использует платформу по умолчанию, и чтения этого файла из метода, который всегда использует UTF-8, независимо от кодировки по умолчанию для платформы. Конечно, это проблема только в этом конкретном случае, если платформой по умолчанию НЕ является UTF-8.
Следующий код Java представляет собой простой класс, который распечатывает некоторые параметры, связанные с наборами символов.
Отображение сведений о кодировке по умолчанию
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
package dustin.examples.charset;import java.io.ByteArrayInputStream;import java.io.InputStream;import java.io.InputStreamReader;import java.nio.charset.Charset;import java.util.Locale;import static java.lang.System.out;/** * Demonstrate default Charset-related details. */public class CharsetDemo{ /** * Supplies the default encoding without using Charset.defaultCharset() * and without accessing System.getProperty("file.encoding"). * * @return Default encoding (default charset). */ public static String getEncoding() { final byte [] bytes = {'D'}; final InputStream inputStream = new ByteArrayInputStream(bytes); final InputStreamReader reader = new InputStreamReader(inputStream); final String encoding = reader.getEncoding(); return encoding; } public static void main(final String[] arguments) { out.println("Default Locale: " + Locale.getDefault()); out.println("Default Charset: " + Charset.defaultCharset()); out.println("file.encoding; " + System.getProperty("file.encoding")); out.println("sun.jnu.encoding: " + System.getProperty("sun.jnu.encoding")); out.println("Default Encoding: " + getEncoding()); }} |
На следующем снимке экрана показаны результаты работы этого простого класса на ноутбуке под управлением Windows 10 без явного указания системного свойства, связанного с file.encoding , со спецификацией только системного свойства file.encoding и со спецификацией обоих системных свойств file.encoding и sun.jnu.encoding .
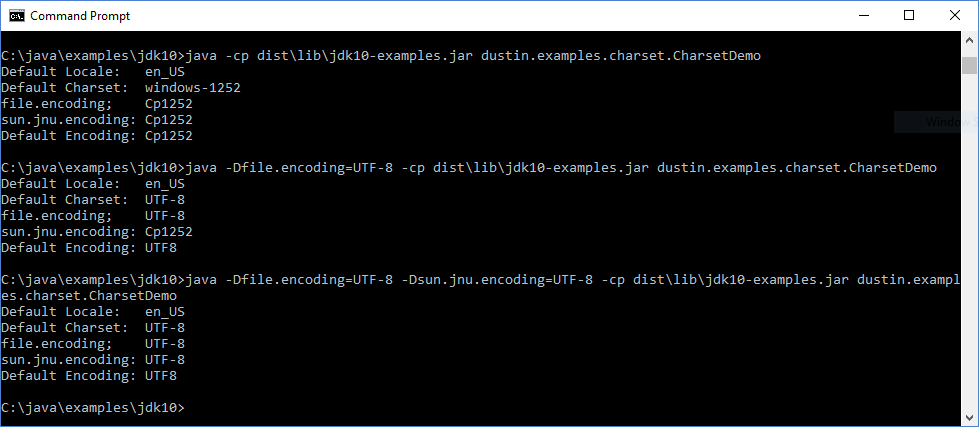
Только что показанное изображение демонстрирует возможность управления кодировками по умолчанию через свойства. Это также демонстрирует, что для этой среды Windows с языковым стандартом en_US набор символов по умолчанию для содержимого и путей к файлам — windows-1252 ( Cp1252 ). Если проект JEP, обсуждаемый в этом посте, будет реализован, кодировка по умолчанию для содержимого файла будет изменена на UTF-8 даже для Windows.
В некоторых приложениях существует вероятность значительного сбоя при изменении кодировки по умолчанию на UTF-8. В проекте JEP говорится о способах снижения этого риска, включая раннее тестирование чувствительности приложения к изменению, предварительно явно file.encoding для системного свойства file.encoding значение UTF-8 . В тех случаях, когда необходимо сохранить текущее поведение (используя определяемую системой кодировку по умолчанию, а не всегда используя UTF-8), текущая версия черновика JEP предлагает поддержку возможности указать -Dfile.encoding=SYSTEM .
В настоящий момент JEP находится в черновике и не связан с какой-либо конкретной версией JDK. Однако, основываясь на недавних публикациях в списках рассылки JDK , я с оптимизмом смотрю, что мы увидим UTF-8 в качестве кодировки по умолчанию в будущей версии JDK в не столь отдаленном будущем.
| Опубликовано на Java Code Geeks с разрешения Дастина Маркса, партнера нашей программы JCG . См. Оригинальную статью здесь: Java может использовать UTF-8 в качестве кодировки по умолчанию
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |