Параллельные вычисления или распараллеливание — это форма вычислений, в которой многие вычисления выполняются одновременно, исходя из того, что большие проблемы часто можно разделить на более мелкие, которые затем решаются одновременно («параллельно»). По сути, если проблему с интенсивным использованием ЦП можно разделить на более мелкие независимые задачи, то эти задачи могут быть назначены различным процессорам.
Что касается многопоточности и параллелизма, Java очень интересна. У него была поддержка Thread s с самого начала, и в прежние времена вы могли манипулировать выполнением потока, используя низкоуровневый подход с методами interrupt , join , sleep . Кроме того, могут быть полезны методы notify и wait, которые наследуют все объекты.
Таким способом можно было контролировать выполнение приложения, но процесс был немного утомительным. А затем появился пакет параллелизма в Java 1.5, который предоставил инфраструктуру более высокого уровня, с помощью которой разработчики могли обрабатывать потоки более простым, легким и менее подверженным ошибкам способом. Пакет предоставляет набор служебных классов, обычно полезных для параллельного программирования.
С годами потребность в программах с поддержкой параллелизма стала еще больше, поэтому платформа сделала еще один шаг вперед, представив новые функции параллелизма для Java SE 7 . Одной из особенностей является введение инфраструктуры Fork / Join, которая должна была быть включена в версию JDK 1.5, но, в конце концов, этого не произошло.
Инфраструктура Fork / Join разработана для упрощения распараллеливания алгоритмов «разделяй и властвуй» . Этот тип алгоритмов идеально подходит для задач, которые можно разделить на две или более подзадач одного типа. Они используют рекурсию, чтобы разбить проблему на простые задачи, пока они не станут достаточно простыми для непосредственного решения. Решения подзадач затем объединяются, чтобы дать решение исходной проблемы. Отличным введением в подход Fork / Join является статья « Разработка Fork-Join в Java SE ».
Как вы, возможно, заметили, подход Fork / Join похож на MapReduce в том, что они оба являются алгоритмами для распараллеливания задач. Однако одно отличие состоит в том, что задачи Fork / Join будут подразделяться на более мелкие задачи только в случае необходимости (если они слишком велики), тогда как алгоритмы MapReduce делят всю работу на части в качестве первого шага их выполнения.
Среда Java Fork / Join возникла как JSR-166, и вы можете найти больше информации на сайте интересов Concurrency JSR-166, который ведет Дуг Ли . На самом деле, это то место, куда вы должны пойти, если вы хотите использовать инфраструктуру и у вас нет JDK 7. Как упоминалось на сайте, мы можем использовать связанные классы в JDK 1.5 и 1.6 без необходимости устанавливать последнюю версию JDK. Для этого нам нужно скачать jar jsr166 и запустить нашу JVM с помощью опции -Xbootclasspath / p: jsr166.jar. Обратите внимание, что перед «jsr166.jar» может потребоваться указывать полный путь к файлу. Это должно быть сделано, потому что JAR содержит некоторые классы, которые переопределяют основные классы Java (например, те, которые находятся в пакете java.util). Не забудьте добавить в закладки документы JSR-166 API .
Итак, давайте посмотрим, как можно использовать структуру для решения реальной проблемы. Мы собираемся создать программу, которая вычисляет числа Фибоначчи (классическая педагогическая проблема) и посмотрим, как использовать новые классы, чтобы сделать это как можно быстрее. Эта проблема также была рассмотрена в статье Java Fork / Join + Groovy .
Сначала мы создаем класс, который представляет проблему следующим образом:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
package com.javacodegeeks.concurrency.forkjoin;public class FibonacciProblem { public int n; public FibonacciProblem(int n) { this.n = n; } public long solve() { return fibonacci(n); } private long fibonacci(int n) { System.out.println("Thread: " + Thread.currentThread().getName() + " calculates " + n); if (n <= 1) return n; else return fibonacci(n-1) + fibonacci(n-2); }} |
Как видите, мы используем рекурсивную версию решения, и это типичная реализация. (Обратите внимание, что эта реализация крайне неэффективна, поскольку она вычисляет одни и те же значения снова и снова. В реальном сценарии уже рассчитанные значения должны кэшироваться и извлекаться в последующих выполнениях). Давайте теперь посмотрим, как будет выглядеть однопотоковый подход:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
package com.javacodegeeks.concurrency.forkjoin;import org.perf4j.StopWatch;public class SillyWorker { public static void main(String[] args) throws Exception { int n = 10; StopWatch stopWatch = new StopWatch(); FibonacciProblem bigProblem = new FibonacciProblem(n); long result = bigProblem.solve(); stopWatch.stop(); System.out.println("Computing Fib number: " + n); System.out.println("Computed Result: " + result); System.out.println("Elapsed Time: " + stopWatch.getElapsedTime()); }} |
Мы просто создаем новую проблему FibonacciProblem и выполняем ее метод решения, который будет рекурсивно вызывать метод Фибоначчи Я также использую симпатичную библиотеку Perf4J, чтобы отслеживать истекшее время. Вывод будет выглядеть примерно так (я выделил последние строки): … Тема: main рассчитывает 1 Тема: main вычисляет 0 Вычисление числа Fib: 10 Вычисление Результат: 55 Истекшее время: 8 Как и ожидалось, вся работа выполняется только одна нить (основная). Давайте посмотрим, как это можно переписать с помощью инфраструктуры Fork / Join. Обратите внимание, что в решении Фибоначчи происходит следующее: fibonacci (n-1) + fibonacci (n-2). Поэтому мы можем назначить каждую из этих двух задач новому рабочему (то есть новому потоку) и после рабочие закончили свои казни, мы присоединимся к результату. Принимая это во внимание, мы вводим класс FibonacciTask, который по сути является способом разделения большой проблемы Фибоначчи на более мелкие.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
package com.javacodegeeks.concurrency.forkjoin;import java.util.concurrent.RecursiveTask;public class FibonacciTask extends RecursiveTask<Long> { private static final long serialVersionUID = 6136927121059165206L; private static final int THRESHOLD = 5; private FibonacciProblem problem; public long result; public FibonacciTask(FibonacciProblem problem) { this.problem = problem; } @Override public Long compute() { if (problem.n < THRESHOLD) { // easy problem, don't bother with parallelism result = problem.solve(); } else { FibonacciTask worker1 = new FibonacciTask(new FibonacciProblem(problem.n-1)); FibonacciTask worker2 = new FibonacciTask(new FibonacciProblem(problem.n-2)); worker1.fork(); result = worker2.compute() + worker1.join(); } return result; }} |
Примечание. Если вы не используете JDK 7 и вручную включили библиотеки JSR-166, вам придется переопределить базовые классы Java по умолчанию. В противном случае вы столкнетесь со следующей ошибкой: java.lang.SecurityException: имя запрещенного пакета: java.util.concurrent. Чтобы предотвратить это, настройте JVM для переопределения классов с помощью следующего аргумента: -Xbootclasspath / p: lib / jsr166.jar Я использовал значение «lib / jsr166.jar», потому что JAR находится в папке с именем «lib» внутри моего проекта Eclipse. Вот как выглядит конфигурация:
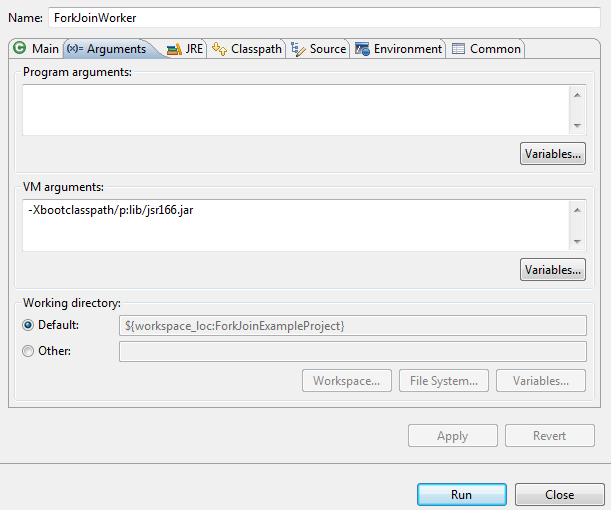
Наша задача расширяет класс RecursiveTask, который является рекурсивным ForkJoinTask, приносящим результаты . Мы переопределяем метод compute, который обрабатывает основные вычисления, выполняемые этой задачей. В этом методе мы сначала проверяем, должны ли мы использовать параллелизм (сравнивая с порогом). Если эту задачу легко выполнить, мы напрямую вызываем метод решения, в противном случае мы создаем две меньшие задачи и затем выполняем каждую из них независимо. Выполнение происходит в разных потоках и их результаты затем объединяются. Это достигается с помощью методов fork и join . Давайте проверим нашу реализацию:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
package com.javacodegeeks.concurrency.forkjoin;import java.util.concurrent.ForkJoinPool;import org.perf4j.StopWatch;public class ForkJoinWorker { public static void main(String[] args) { // Check the number of available processors int processors = Runtime.getRuntime().availableProcessors(); System.out.println("No of processors: " + processors); int n = 10; StopWatch stopWatch = new StopWatch(); FibonacciProblem bigProblem = new FibonacciProblem(n); FibonacciTask task = new FibonacciTask(bigProblem); ForkJoinPool pool = new ForkJoinPool(processors); pool.invoke(task); long result = task.result; System.out.println("Computed Result: " + result); stopWatch.stop(); System.out.println("Elapsed Time: " + stopWatch.getElapsedTime()); } } |
Сначала мы проверяем доступное количество процессоров в системе, а затем создаем новый ForkJoinPool с соответствующим уровнем параллелизма. Мы назначаем и выполняем нашу задачу, используя метод invoke . Вот вывод (я выделил первый и последний методы): Нет процессоров: 8 Поток: ForkJoinPool-1-worker-7 вычисляет 4 Поток: ForkJoinPool-1-worker-6 вычисляет 4 Поток: ForkJoinPool-1-worker- 4 вычисляет 4… Поток: ForkJoinPool-1-worker-2 вычисляет 1 Поток: ForkJoinPool-1-worker-2 вычисляет 0 Вычисленный результат: 55 Истекшее время: 16 Обратите внимание, что теперь вычисление делегировано количеству рабочих потоков, каждый из которых из которых назначена задача меньше, чем оригинал. Возможно, вы заметили, что прошедшее время больше предыдущего. Этот парадокс происходит потому, что мы использовали низкий порог (5) и низкое значение для n (10). Из-за этого создается большое количество потоков, что приводит к ненужной задержке. Реальная сила каркаса станет очевидной для больших значений порога (около 20) и более высоких значений n (40 и выше). Я выполнил несколько быстрых стресс-тестов для значений n> 40, и вот диаграмма с результатами:
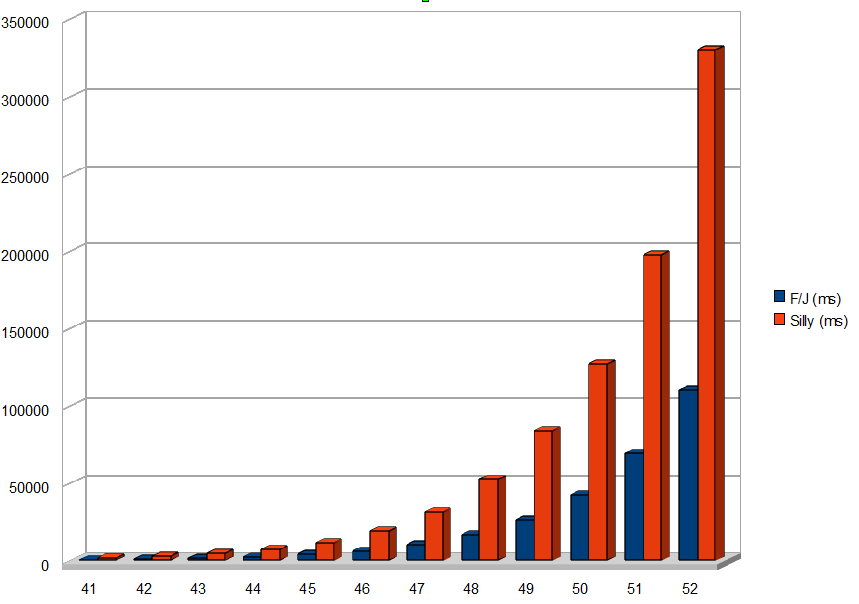 Очевидно, что инфраструктура Fork / Join масштабируется намного лучше, чем однопотоковый подход, и выполняет вычисления гораздо быстрее. (Если вы хотите выполнить некоторые собственные стресс-тесты, не забудьте удалить вызов System.out в классе FibonacciProblem.) Также интересно посмотреть некоторые картины использования процессора на моем компьютере с Windows 7 ( i7- 720QM с 4 ядрами и Hyper-Threading ), в то время как каждый из подходов был использован.
Очевидно, что инфраструктура Fork / Join масштабируется намного лучше, чем однопотоковый подход, и выполняет вычисления гораздо быстрее. (Если вы хотите выполнить некоторые собственные стресс-тесты, не забудьте удалить вызов System.out в классе FibonacciProblem.) Также интересно посмотреть некоторые картины использования процессора на моем компьютере с Windows 7 ( i7- 720QM с 4 ядрами и Hyper-Threading ), в то время как каждый из подходов был использован.
Однозаходные: 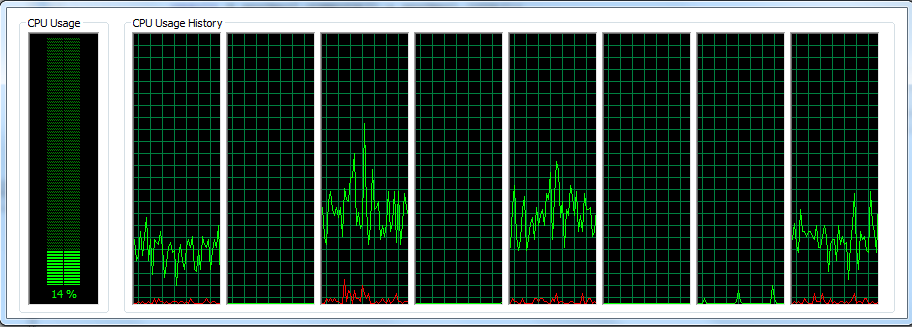 Общее использование процессора оставалось очень низким во время выполнения (никогда не превышало 16%). Как видите, ЦП недостаточно загружен, в то время как однопоточное приложение пытается выполнить все вычисления.
Общее использование процессора оставалось очень низким во время выполнения (никогда не превышало 16%). Как видите, ЦП недостаточно загружен, в то время как однопоточное приложение пытается выполнить все вычисления.
Многопоточная:
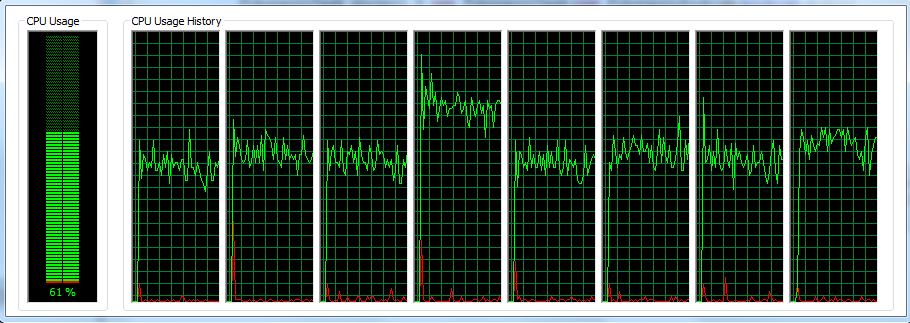 Загрузка ЦП намного лучше, и все процессоры вносят свой вклад в общий расчет. Мы подошли к концу моего представления фреймворка Fork / Join в Java. Обратите внимание, что здесь я только коснулся темы, существует множество других функций, которые готовы помочь нам в использовании многоядерных процессоров. Появляется новая эра, поэтому разработчики должны ознакомиться с этими концепциями. Как всегда, вы можете найти здесь исходный код, созданный для этой статьи. Не забудьте поделиться!
Загрузка ЦП намного лучше, и все процессоры вносят свой вклад в общий расчет. Мы подошли к концу моего представления фреймворка Fork / Join в Java. Обратите внимание, что здесь я только коснулся темы, существует множество других функций, которые готовы помочь нам в использовании многоядерных процессоров. Появляется новая эра, поэтому разработчики должны ознакомиться с этими концепциями. Как всегда, вы можете найти здесь исходный код, созданный для этой статьи. Не забудьте поделиться!