Возобновление из предыдущих частей
Часть № 1 , Часть № 2 , Часть № 3 , Часть № 4 , Часть № 5 , Часть № 6
В предыдущем посте (номер 6) мы выяснили, как мы можем модульно протестировать нашу модель домена JPA2, используя Arquillian и Wildfly 8.1. В посте мы приняли простое решение о конфигурации, мы использовали внутреннюю базу данных H2, которая связана с Wildfly 8.1, и уже настроенный источник данных (называемый ExampleDS). Но как насчет настоящей СУБД? В этом посте мы собираемся немного расширить предыдущую работу, использовать те же принципы и
- тест на работающий PostgreSQL на нашем локальном хосте
- используйте некоторые из действительно хороших функций ShrinkWrap APi Arquillian Offers.
Предпосылки
Вам необходимо установить локально RBDMS PostgreSQL , мой пример основан на сервере, работающем на localhost, а имя базы данных — papodb .
Добавление еще нескольких зависимостей
В конце концов нам нужно будет добавить еще несколько зависимостей в нашем sample-parent (pom). Некоторые из них связаны с Arquillian и, в частности, с функциями ShrinkWrap Resolvers (подробнее об этом позже).
Таким образом, наши мы должны добавить к родительскому пом. xml следующее:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
<shrinkwrap.bom-version>2.1.1</shrinkwrap.bom-version> <!-- jbdc drivers --> <postgreslq.version>9.1-901-1.jdbc4</postgreslq.version>... <!-- shrinkwrap BOM--><dependency> <groupId>org.jboss.shrinkwrap.resolver</groupId> <artifactId>shrinkwrap-resolver-bom</artifactId> <version>${shrinkwrap.bom-version}</version> <type>pom</type> <scope>import</scope> </dependency> <!-- shrinkwrap dependency chain--> <dependency> <groupId>org.jboss.shrinkwrap.resolver</groupId> <artifactId>shrinkwrap-resolver-depchain</artifactId> <version>${shrinkwrap.bom-version}</version> <type>pom</type> </dependency> <!-- arquillian itself--> <dependency> <groupId>org.jboss.arquillian</groupId> <artifactId>arquillian-bom</artifactId> <version>${arquillian-version}</version> <scope>import</scope> <type>pom</type> </dependency> <!-- the JDBC driver for postgresql --> <dependency> <groupId>postgresql</groupId> <artifactId>postgresql</artifactId> <version>${postgreslq.version}</version> </dependency> |
Некоторые примечания по вышеуказанному изменению:
- Чтобы избежать возможных конфликтов между зависимостями, обязательно определите спецификацию ShrinkWrap поверх спецификации Arquillian.
Теперь в примере сервисов (pom.xml) , в котором размещаются простые тесты, нам нужно сослаться на некоторые из этих зависимостей.
|
01
02
03
04
05
06
07
08
09
10
11
|
<dependency> <groupId>org.jboss.shrinkwrap.resolver</groupId> <artifactId>shrinkwrap-resolver-depchain</artifactId> <scope>test</scope> <type>pom</type> </dependency> <dependency> <groupId>postgresql</groupId> <artifactId>postgresql</artifactId></dependency> |
Реструктуризация нашего тестового кода
В предыдущем примере наш тест был простым, мы использовали только определенную конфигурацию теста. Это привело к единственному файлу test-persistence.xml и отсутствию файла web.xml , поскольку мы упаковывали наше тестовое приложение как jar. Теперь мы обновим наш тестовый архив до войны. Военная упаковка в JavaEE7 стала гражданином первого уровня, когда дело доходит до объединения и развертывания корпоративного приложения. Основное отличие от предыдущего примера состоит в том, что мы хотели бы сохранить как предыдущие настройки, то есть тестирование с использованием внутренней H2 на wildfly, так и тестирование новых настроек в отношении реального сервера RDBMS. Поэтому нам нужно сохранить 2 набора файлов конфигурации и, используя функцию профилей Maven, упаковать их соответствующим образом в зависимости от нашего режима. Если вы новичок в Maven, обязательно ознакомьтесь с концепциями профилей .
Добавление отдельных конфигураций для профилей
Итак, наши тестовые ресурсы (обратите внимание, что они находятся в каталоге src / test / resources) теперь, как показано ниже.
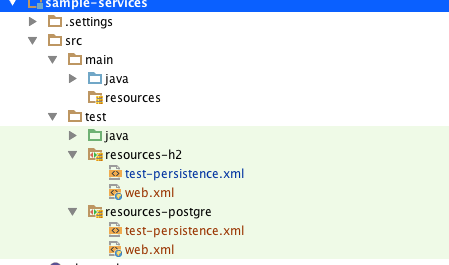
Есть различия в обоих случаях. Test-persistence.xml из h2 указывает на источник данных ExampleDS, где на postgre указывает на новый источник данных, который мы определили в файле web.xml! Пожалуйста, ознакомьтесь с реальным кодом, перейдя по ссылке ниже.
Вот как мы определяем источник данных в web.xml
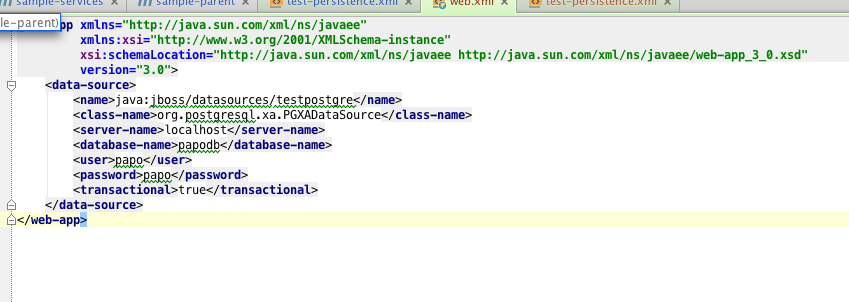
Примечания к вышесказанному
- стандартное именование в имени JNDI java: jboss / datasources / datasourceName
- сервер приложений, как только он прочитает содержимое файла web.xml, автоматически развернет и настроит новый источник данных.
Это наш persistence.xml
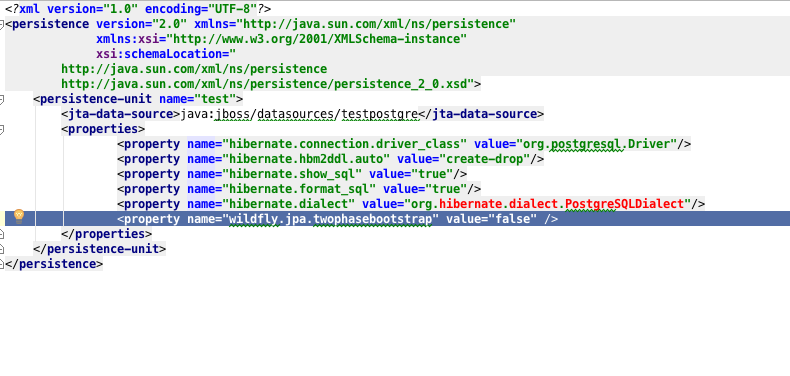
Примечания к вышесказанному
- Убедитесь, что 2 записи JNDI одинаковы как в определении источника данных, так и в файле persistence.xml.
- Конечно, Hibernate Диалект, используемый для postGresql, отличается
- Выделенная строка — это специальный параметр, который требуется для Wildfly 8.1 в тех случаях, когда вы хотите выполнить развертывание одним движением, источником данных, драйвером jdbc и кодом. Он указывает серверу приложений на инициализацию и настройку сначала источника данных, а затем инициализирует EntityManager. В тех случаях, когда вы уже развернули / настроили источник данных, этот параметр не требуется.
Определите профили в нашем пом
В образец-службы pom.xml мы добавляем следующий раздел. Это определение нашего профиля.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
<profiles> <profile> <id>h2</id> <build> <testResources <testResource> <directory>/resources-h2</directory> <includes> <include>**/*</include> </includes> </testResource> </testResources> </build> </profile> <profile> <id>postgre</id> <build> <testResources> <testResource> <directory>/resources-postgre</directory> <includes> <include>**/*</include> </includes> </testResource> </testResources> </build> </profile></profiles> |
В зависимости от профиля actived мы указываем Maven включать и работать с файлами xml в определенной подпапке. Так что, если мы применим следующую команду:
|
1
|
mvn clean test -Pdb2 |
Затем maven включит persistence.xml и web.xml в папку resource-h2, и наши тесты будут использовать интерактивную базу данных H2. Если мы выпустим, хотя:
|
1
|
mvn clean test -Ppostgre |
Затем наш тестовый веб-архив будет упакован с определением источника данных, специфичным для нашего локального сервера postgresql.
Написание простого теста
В конце концов наш новый тест JUnit не сильно отличается от предыдущего. Вот скриншот с указанием некоторых ключевых моментов.

{kind=link}
Некоторые примечания к коду выше:
- Тест Junit и основные аннотации те же, что и в предыдущем посте.
- Метод init () опять тот же, мы просто создаем и сохраняем новый объект SimpleUser
- Первым существенным отличием является использование ShrinkWrap Api, которое использует наши тестовые зависимости в нашем pom, и мы можем найти драйвер JBDC в качестве jar. После того, как ShrinkWrap найден, он должен упаковать его вместе с остальными ресурсами и кодом в наш test.war.
- Упаковка только драйвера jdbc, однако, НЕ является достаточной, чтобы это работало, нам нужен источник данных, который будет присутствовать (настроен) на сервере. Мы хотели бы, чтобы это было автоматически, то есть мы не хотим ничего предварительно настраивать на нашем тестовом сервере Wildfly. Мы используем эту функцию для определения источника данных в web.xml. (откройте его в коде).
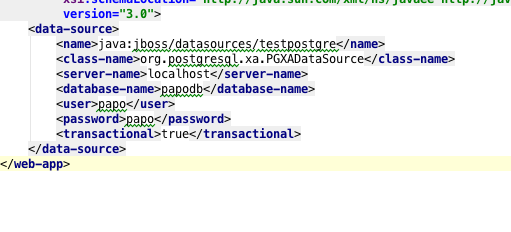
- Сервер приложений после сканирования web.xml подберет запись и настроит источник данных под именем java: jboss / datasources / testpostgre.
- Итак, мы связали драйвер, определение источника данных, у нас есть файл persistence.xml, указывающий на правильный источник данных. мы готовы проверить
- Наш метод испытаний похож на предыдущий.
Мы немного изменили ресурсы для профиля H2, чтобы мы каждый раз упаковывали одну и ту же военную структуру. Это означает, что если мы запустим тест с использованием профиля -Ph2, включенный файл web.xml будет пустым, потому что на самом деле нам не нужно определять источник данных там, так как источник данных уже развернут Wildfly. Файл persistence.xml отличается, потому что в одном случае определенный диалект специфичен для H2, а в другом — для Postgre.
Вы можете следовать тому же принципу и добавить новую подпапку ресурса, настроить источник данных для другой СУБД, например, MySQL, добавить соответствующий код для загрузки драйвера и упаковать его вместе.
- Вы можете получить код для этого поста в этом репо-теге bitbucket .
Ресурс
- Страница API Shrinkwrap resolver (много хороших примеров для этого мощного API)
- Определение источников данных для Wildfly 8.1
| Ссылка: | Проект Java EE7 и Maven для новичков — часть 7 от нашего партнера JCG Париса Апостолопулоса в блоге Papo . |