По моему опыту, java.nio.ByteBuffer является источником путаницы и мелких ошибок, когда разработчики впервые сталкиваются с этим, потому что не сразу очевидно, как правильно его использовать. Потребовалось некоторое повторное чтение документации API и некоторый опыт, чтобы понять некоторые тонкости, прежде чем я почувствовал себя комфортно с ними. Этот пост является кратким описанием того, как правильно их использовать, чтобы, надеюсь, избавить других от некоторых неприятностей.
Поскольку все это выводится (а не основано на явной документации) и основано на опыте, я не могу утверждать, что информация обязательно является достоверной. Я приветствую обратную связь, чтобы указать на ошибки или альтернативные точки зрения. Я также приветствую предложения о дополнительных подводных камнях / лучших методах, которые нужно охватить.
Я предполагаю, что читатель будет смотреть на документацию API, чтобы пойти с этим постом. Я не собираюсь быть исчерпывающим во всех возможных вещах, которые вы можете сделать с помощью ByteBuffer.
Абстракция ByteBuffer
Посмотрите на ByteBuffer как на представление некоторого (неопределенного) базового хранилища байтов. Два наиболее распространенных конкретных типа байтовых буферов — это те, которые поддерживаются байтовыми массивами, и те, которые поддерживаются прямыми (вне кучи, нативными) байтовыми буферами. В обоих случаях один и тот же интерфейс может использоваться для чтения и записи содержимого буфера.
Некоторые части API ByteBuffer специфичны для некоторых типов байтовых буферов. Например, байтовый буфер может быть только для чтения , ограничивая использование подмножеством методов. Метод array () будет работать только для байтового буфера, поддерживаемого байтовым массивом (который можно протестировать с помощью hasArray () ), и его, как правило, следует использовать, только если вы точно знаете, что делаете . Распространенной ошибкой является использование array () для «преобразования» ByteBuffer в байтовый массив. Это не только работает только для буферов с байтовым массивом, но и легко является источником ошибок, поскольку в зависимости от того, как был создан буфер, начало возвращаемого массива может соответствовать или не соответствовать началу ByteBuffer. В результате получается небольшая ошибка, в которой поведение кода различается в зависимости от деталей реализации буфера байтов и кода, который его создал.
ByteBuffer предлагает возможность дублировать себя, вызывая duplicate () . На самом деле это не копирует базовые байты , а только создает новый экземпляр ByteBuffer, указывающий на то же базовое хранилище. ByteBuffer, представляющий подмножество другого ByteBuffer, может быть создан с использованием slice () .
Ключевые отличия от байтовых массивов
- ByteBuffer имеет семантику значений по отношению к hashCode () / equals () и в результате может быть более удобно использован в контейнерах.
- ByteBuffer предлагает возможность передавать подмножество байтового буфера в качестве значения без копирования байтов путем создания нового ByteBuffer.
- API NIO широко использует ByteBuffer: s.
- Байты в ByteBuffer могут потенциально находиться вне кучи Java.
- ByteBuffer имеет состояние за пределами самих байтов, что облегчает относительные операции ввода / вывода (но с оговорками, о которых говорится ниже).
- ByteBuffer предлагает методы для чтения и записи различных примитивных типов, таких как целые и длинные числа (и может делать это в разных порядках байтов).
Ключевые свойства ByteBuffer
Следующие три свойства ByteBuffer являются критическими (я цитирую документацию API для каждого):
- Емкость буфера — это количество элементов в нем. Емкость буфера никогда не бывает отрицательной и никогда не меняется.
- Лимит буфера — это индекс первого элемента, который не должен быть прочитан или записан. Лимит буфера никогда не бывает отрицательным и никогда не превышает его емкость.
- Позиция буфера — это индекс следующего элемента для чтения или записи. Позиция буфера никогда не бывает отрицательной и никогда не превышает своего предела.
Вот визуализация примера ByteBuffer, который (в данном случае) поддерживается байтовым массивом, а значением ByteBuffer является слово «test» (щелкните его, чтобы увеличить):
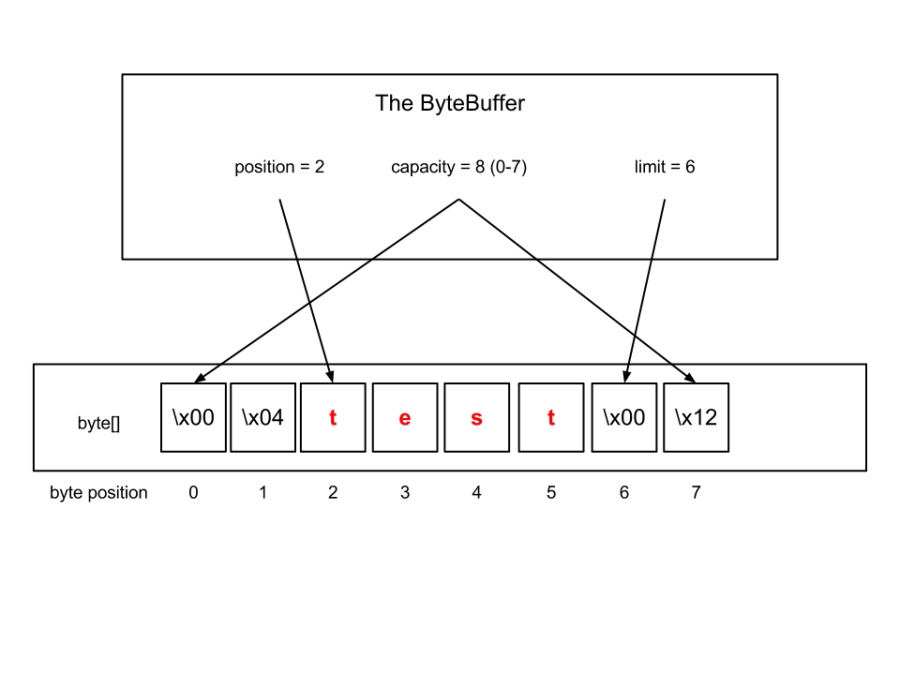
Этот ByteBuffer будет равен (в смысле equals () ) любому другому ByteBuffer, чье содержимое между [ position , limit ) одинаково.
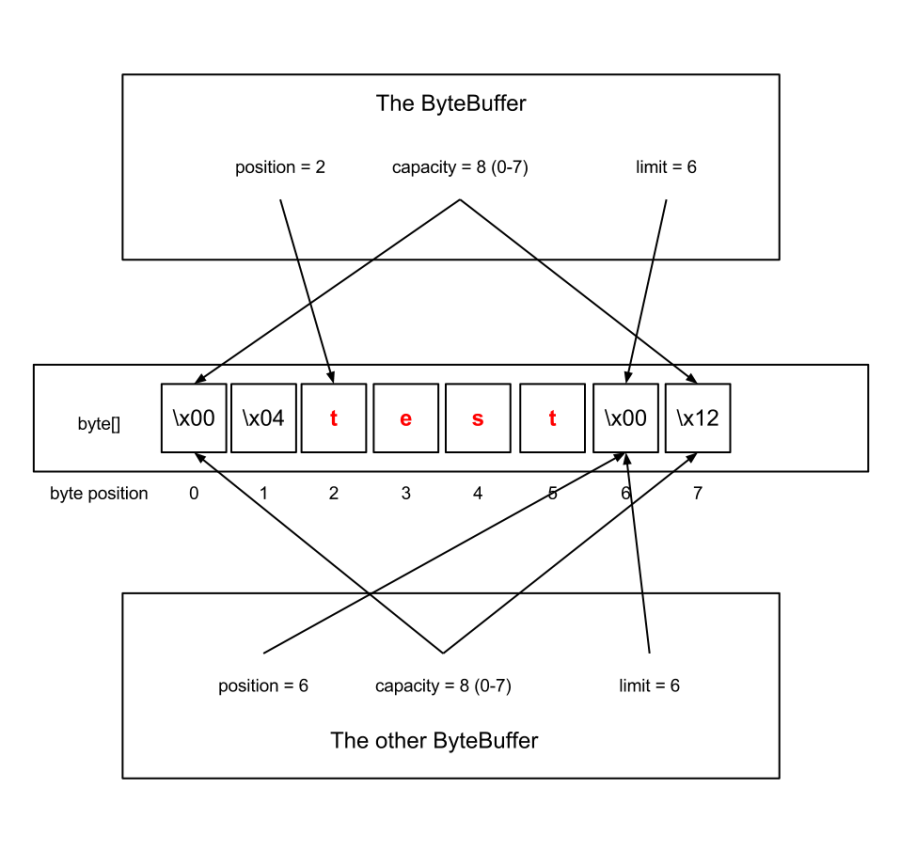
Предположим, что визуализированный выше байтовый буфер был bb , и мы сделали это:
|
1
2
|
final ByteBuffer other = bb.duplicate();other.position(bb.position() + 4); |
Теперь у нас будет два экземпляра ByteBuffer, которые ссылаются на один и тот же базовый байтовый массив, но их содержимое будет другим ( другое будет пустым):
Двойственность буфера / потока байтовых буферов
Существует два способа доступа к содержимому байтового буфера — абсолютный и относительный доступ. Например, предположим, что у меня есть ByteBuffer, который, как я знаю, содержит два целых числа. Чтобы извлечь целые числа, используя абсолютное позиционирование, можно сделать это:
|
1
2
|
int first = bb.getInt(0)int second = bb.getInt(4) |
В качестве альтернативы можно извлечь их, используя относительное расположение:
|
1
2
|
int first = bb.getInt();int second = bb.getInt(); |
Второй вариант часто удобен, но за счет побочного эффекта на буфер (т.е. его изменения). Не само содержимое, а представление ByteBuffers в это содержимое.
Таким образом, ByteBuffers может вести себя подобно потоку, если используется как таковой.
Лучшие практики и подводные камни
перевернуть () буфер
Если вы создаете ByteBuffer, многократно записывая в него, а затем хотите отдать его, вы должны не забыть его перевернуть () . Например, вот метод, который копирует байтовый массив в ByteBuffer, предполагая кодировку по умолчанию (обратите внимание, что используемый здесь ByteBuffer.wrap () создает ByteBuffer, который оборачивает указанный байтовый массив, а не копирует содержимое это в новый ByteBuffer):
|
1
2
3
4
5
6
7
8
|
public static ByteBuffer fromByteArray(byte[] bytes) { final ByteBuffer ret = ByteBuffer.wrap(new byte[bytes.length]); ret.put(bytes); ret.flip(); return ret;} |
Если бы мы не бросили () его, возвращенный ByteBuffer был бы пуст, потому что позиция была бы равна пределу .
Не использовать буфер
Будьте осторожны, чтобы не «использовать» байтовый буфер при его чтении, если только вы специально не собираетесь это делать. Например, рассмотрим этот метод для преобразования ByteBuffer в String, предполагая кодировку по умолчанию:
|
1
2
3
4
5
6
7
|
public static String toString(ByteBuffer bb) { final byte[] bytes = new byte[bb.remaining()]; bb.duplicate().get(bytes); return new String(bytes);} |
К сожалению, нет способа обеспечить абсолютное позиционное чтение байтового массива (но существует абсолютное позиционное чтение для примитивов).
Обратите внимание на использование duplicate () при чтении байтов. Если бы мы этого не сделали, функция имела бы побочный эффект на входном ByteBuffer . Стоимость этого — дополнительное выделение нового ByteBuffer только для одного вызова get () . Вы можете записать положение ByteBuffer до get () и восстановить его впоследствии, но это имеет проблемы с безопасностью потока (см. Следующий раздел).
Стоит отметить, что это применимо только тогда, когда вы пытаетесь обработать ByteBuffer: s как значения. Если вы пишете код, целью которого является побочный эффект для ByteBuffers, рассматривая их больше как потоки, вы, конечно, намереваетесь это сделать, и этот раздел неприменим.
Не изменяйте буфер
В контексте универсального кода, который не является специфичным для конкретного варианта использования, это (на мой взгляд) хорошая практика для метода, который выполняет (абстрактно) операцию только для чтения (например, чтение байтового буфера) , чтобы не мутировать его вход. Это более строгое требование, чем «Не использовать ByteByffer». Возьмите пример из предыдущего раздела, но с попыткой избежать дополнительного выделения ByteBuffer:
|
1
2
3
4
5
6
7
8
9
|
public static String toString(ByteBuffer bb) { final byte[] bytes = new byte[bb.remaining()]; bb.mark(); // NOT RECOMMENDED, don't do this bb.get(bytes); bb.reset(); // NOT RECOMMENDED, don't do this return new String(bytes);} |
В этом случае мы записываем состояние ByteBuffer до нашего вызова get () и восстанавливаем его впоследствии (см. Документацию API для mark () и reset () ). У этого подхода есть две проблемы. Первая проблема заключается в том, что функция выше не составляет . ByteBuffer имеет только одну «метку», и ваш (очень общий, не учитывающий контекст ) метод toString () не может с уверенностью предположить, что вызывающая сторона не пытается использовать mark () и reset () для своих собственных целей . Например, представьте, что этот вызывающий объект десериализует строку с префиксом длины:
|
1
2
3
4
5
6
|
bb.mark();int length = bb.getInt();... sanity check lengthfinal String str = ByteBufferUtils.toString(bb);... do somethingbb.reset(); // OOPS - reset() will now point 4 bytes off, because toString() modified the mark |
(Кроме того, это очень надуманный и странный пример, потому что мне было трудно найти реалистичный пример кода, который использует mark () / reset () , который обычно используется при обработке буфера в потоке. как фракция, которая также чувствовала бы необходимость вызова toString () для оставшейся части указанного буфера. Мне было бы интересно услышать, какие решения люди придумали здесь. Например, можно представить четкие политики в базе кода, которая разрешить mark () / reset () в контекстах, ориентированных на значения, таких как toString (), но даже если вы это сделали (и пахнет, вероятно, непреднамеренным нарушением), вы все равно столкнетесь с проблемой мутаций, упомянутой позже.
Давайте посмотрим на альтернативную версию toString (), которая позволяет избежать этой проблемы:
|
1
2
3
4
5
6
7
8
|
public static String toString(ByteBuffer bb) { final byte[] bytes = new byte[bb.remaining()]; bb.get(bytes); bb.position(bb.position() - bytes.length); // NOT RECOMMENDED, don't do this return new String(bytes);} |
В этом случае мы не изменяем марку, поэтому мы создаем. Тем не менее, мы все еще совершаем «преступление», пытаясь изменить наш вклад. Это проблема в многопоточных ситуациях; Вы не хотите читать что-либо, чтобы подразумевать его мутирование, если абстракция не подразумевает это (например, с потоком или при использовании ByteBuffers в виде потока). Если вы передаете ByteBuffer, рассматривая его как значение, помещая его в контейнеры, разделяя их и т. Д. — мутирование их приведет к незначительным ошибкам, если только вы не гарантируете, что два потока никогда не будут использовать один и тот же ByteBuffer одновременно. Как правило, результатом ошибки этого типа является странное искажение значений или неожиданное исключение BufferOverFlowException: s.
Версия, которая не страдает ни от чего из этого, появляется в разделе «Не использовать буфер» выше, который использует duplicate () для создания временного экземпляра ByteBuffer, для которого безопасно вызывать get () .
CompareTo () может быть подписано байтом
байты в Java подписаны , вопреки тому, что обычно ожидают. Что легко упустить, так это то, что это влияет и на ByteBuffer.compareTo () . Документация по Java API для этого метода гласит:
«Два байтовых буфера сравниваются путем сравнения их последовательностей оставшихся элементов лексикографически, без учета начальной позиции каждой последовательности в соответствующем буфере».
Быстрое чтение может привести к выводу, что результат — это то, чего вы обычно ожидаете, но, конечно, учитывая определение байта в Java, это не так. В результате порядок байтовых буферов, который содержит значения с установленным битом самого высокого порядка, будет отличаться от того, что вы можете ожидать.
У превосходной библиотеки Google Guava есть помощник UnsignedBytes, чтобы смягчить вашу боль.
array () — это обычно неправильный метод
Как правило, не используйте array () случайно. Для того, чтобы он был использован правильно, вы должны точно знать, что байтовый буфер поддерживается массивом, или вы должны проверить его с помощью hasArray () и иметь два отдельных пути кода для каждого случая. Кроме того, когда вы используете его, вы должны использовать arrayOffset () , чтобы определить, какой нулевой позиции ByteBuffer соответствует в байтовом массиве.
В типичном коде приложения вы не будете использовать array (), если вы действительно не знаете, что делаете, и вам это особенно нужно. Тем не менее, есть случаи, когда это полезно. Например, предположим, что вы реализуете версию BysBuffer UnsignedBytes.compare () (опять же из Гуавы ) — вы можете оптимизировать случай, когда один или оба аргумента поддерживаются массивом, чтобы избежать ненужного копирования и частых обращений к буферы. Для такого общего и потенциально интенсивно используемого метода такая оптимизация будет иметь смысл.
Ссылка: Java ByteBuffer — ускоренный курс от нашего партнера по JCG Питера Шуллера в блоге (mod: world: scode) .