В современном мире Интернет изменил наш образ жизни, и одной из основных причин этого является использование Интернета для большинства повседневных обязанностей. Это приводит к огромному количеству данных, доступных для обработки.
Вот некоторые примеры использования огромных данных: обработка платежных ведомостей, выписок по счетам, начисление процентов и т. Д. Итак, представьте, что если все эти работы нужно было выполнять вручную, их выполнение может занять много лет.
Как это делается в нынешнем возрасте? Ответ — пакетная обработка.
1. Введение
Пакетная обработка выполняется на объемных данных, без ручного вмешательства и длительно. Это может быть большой объем данных или вычислений. Пакетные задания можно запускать по заранее заданному расписанию или запускать по требованию. Кроме того, поскольку пакетные задания обычно являются длительными, постоянные проверки и перезапуск после определенного сбоя являются общими функциями, встречающимися в пакетных заданиях.
1.1 История Java-пакетной обработки
Пакетная обработка для платформы Java была представлена как часть спецификации JSR 352, части платформы Java EE 7, определяющей модель программирования для пакетных приложений, а также среду выполнения для запуска и управления пакетными заданиями.
1.2 Архитектура Java Batch
На диаграмме ниже показаны основные компоненты для пакетной обработки.
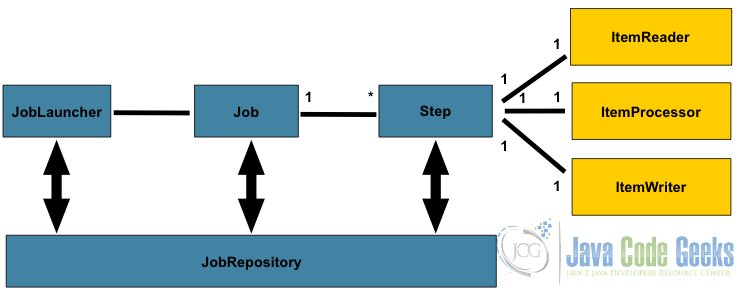
Архитектура для пакетной обработки Java
Архитектура для пакетных приложений решает проблемы пакетной обработки, такие как задания, шаги, репозитории, шаблоны записи процессора считывателя, чанки, контрольные точки, параллельная обработка, поток, повторы, секвенирование, разбиение и т. Д.
Давайте разберемся с потоком архитектуры.
- Репозиторий заданий содержит задания, которые необходимо запустить.
-
JobLauncherвытаскивает работу из репозитория Job. - Каждая работа содержит шаги. Это шаги
ItemReader,ItemProcessorиItemWriter. - Item Reader — это тот, кто читает данные.
- Item Process — это процесс, который обрабатывает данные на основе бизнес-логики.
- Элемент записи будет записывать данные обратно в определенный источник.
1.3 Компоненты пакетной обработки.
Теперь мы попробуем разобраться в компонентах пакетной обработки.
- Работа: работа включает в себя весь пакетный процесс. Он содержит один или несколько шагов. Задание составляется с использованием языка спецификации заданий (JSL), который определяет порядок, в котором должны выполняться шаги. В JSR 352 JSL указывается в XML-файле, известном как XML-файл задания. Работа — это, по сути, контейнер с шагами.
- Шаг. Шаг — это доменный объект, который содержит независимую, последовательную фазу работы. Шаг содержит всю необходимую логику и данные для выполнения фактической обработки. Определение шага остается расплывчатым в соответствии со спецификацией пакета, потому что содержание шага является чисто специфическим для приложения и может быть настолько сложным или простым, насколько этого хочет разработчик. Есть два вида шагов: чанк и ориентированные на задачи .
- Оператор задания: предоставляет интерфейс для управления всеми аспектами обработки задания, который включает в себя рабочие команды, такие как запуск, перезапуск и остановка, а также команды хранилища заданий, такие как получение задания и пошаговое выполнение.
- Репозиторий заданий: содержит информацию о выполняемых в данный момент заданиях и исторические данные о задании.
JobOperatorпредоставляет API для доступа к этому хранилищу.JobRepositoryможет быть реализован с использованием базы данных или файловой системы.
Следующий раздел поможет понять некоторые общие символы пакетной архитектуры.
1.3 Шаги в работе
Шаг — это независимая фаза работы. Как обсуждалось выше, в задании есть два типа шагов. Мы постараемся понять оба типа подробно ниже.
1.3.1. Ориентированные на куски шаги
Шаги чанков будут считывать и обрабатывать один элемент за раз и группировать результаты в чанк. Затем результаты сохраняются, когда чанк достигает предварительно определенного размера. Блок-ориентированная обработка делает сохранение результатов более эффективным, когда набор данных огромен. Он состоит из трех частей.
- Считыватель элементов читает входные данные один за другим из источника данных, который может быть базой данных, простым файлом, файлом журнала и т. Д.
- Процессор будет обрабатывать данные по очереди на основе определенной бизнес-логики.
- Писатель записывает данные кусками. Размер куска предопределен и настраивается
Как часть шагов чанка, существуют контрольные точки, которые предоставляют информацию структуре для завершения чанков. Если во время обработки фрагмента произошла ошибка, процесс может быть перезапущен на основе последней контрольной точки.
1.3.2 Задачи, ориентированные на задачу
Он выполняет задачу, отличную от обработки элементов из источника данных. К ним относится создание или удаление каталогов, перемещение файлов, создание или удаление таблиц базы данных и т. Д. Шаги задачи обычно не являются длительными по сравнению с шагами блока.
В обычном сценарии этапы, ориентированные на задачи, используются после этапов, ориентированных на фрагменты, где требуется очистка. Например, мы получаем файлы журнала как вывод приложения. Шаги чанка используются для обработки данных и получения значимой информации из файлов журнала.
Шаг задачи затем используется для очистки старых файлов журнала, которые больше не нужны.
1.3.3 Параллельная обработка
Пакетные задания часто выполняют дорогостоящие вычислительные операции и обрабатывают большие объемы данных. Пакетные приложения могут выиграть от параллельной обработки в двух сценариях.
- Шаги, которые являются независимыми по своей природе, могут выполняться в разных потоках.
- Этапы, ориентированные на блоки, где обработка каждого элемента не зависит от результатов обработки предыдущих элементов, может выполняться в нескольких потоках.
Пакетная обработка помогает быстрее выполнять задачи и выполнять операции с большими данными.
2. Инструменты и технологии
Давайте посмотрим на технологии и инструменты, используемые для создания программы.
- Eclipse Oxygen.2 Release (4.7.2)
- Java — версия 9.0.4
- Gradle — 4.3
- Spring boot — 2.0.1-Release
- База данных HSQL
3. Структура проекта
Структура проекта будет выглядеть так, как показано на рисунке ниже.
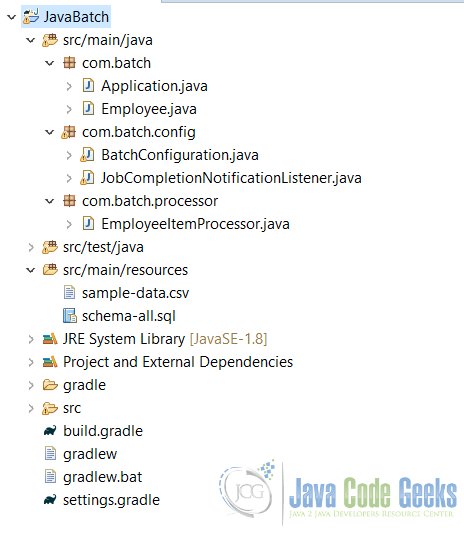
Структура проекта для Java Batch
Приведенная выше структура проекта использует Gradle. Этот проект также можно создать с помощью maven, и build.gralde будет заменен файлом pom.xml. Структура проекта будет несколько зависеть от использования Maven для сборки.
4. Цель Программы
В рамках программы мы попытаемся создать простое пакетное приложение Java с использованием весенней загрузки. Это приложение будет выполнять следующие задачи.
- Чтение: — Чтение данных о сотрудниках из файла CSV.
- Обработка данных: — Преобразование данных сотрудника в верхний регистр.
- Записать: — записать обработанные данные сотрудника обратно в базу данных.
4.1 Gradle build
Мы используем Gradle для сборки как часть программы. Файл build.gradle будет выглядеть так, как показано ниже.
build.gradle
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
buildscript { repositories { mavenCentral() } dependencies { classpath("org.springframework.boot:spring-boot-gradle-plugin:2.0.1.RELEASE") }}apply plugin: 'java'apply plugin: 'eclipse'apply plugin: 'idea'apply plugin: 'org.springframework.boot'apply plugin: 'io.spring.dependency-management'bootJar { baseName = 'java-batch' version = '1.0'}repositories { mavenCentral()}sourceCompatibility = 1.8targetCompatibility = 1.8dependencies { compile("org.springframework.boot:spring-boot-starter-batch") compile("org.hsqldb:hsqldb") testCompile("junit:junit")} |
В приведенном выше файле build.gradle apply plugin: 'java' сообщает нам плагин, который нужно установить. Для нас это плагин Java.
repositories{} позволяет нам узнать репозиторий, из которого следует извлечь зависимость. Мы выбрали mavenCentral чтобы вытащить банки зависимостей. Мы также можем использовать jcenter для jcenter соответствующих jcenter зависимостей.
Тег dependencies {} используется для предоставления необходимых сведений о файле jar, которые необходимо извлечь для проекта. apply plugin: 'org.springframework.boot' этот плагин используется для определения проекта весенней загрузки. boot jar{} будет указывать свойства jar, которые будут сгенерированы из сборки.
4.2 Пример файла данных
Чтобы предоставить данные для фазы чтения, мы будем использовать CSV-файл, содержащий данные о сотрудниках.
Файл будет выглядеть так, как показано ниже.
Образец файла CSV
|
1
2
3
4
5
|
John,FosterJoe,ToyJustin,TaylorJane,ClarkJohn,Steve |
Пример файла данных содержит имя и фамилию сотрудника. Мы будем использовать те же данные для обработки и последующей вставки в базу данных.
4.3 SQL-скрипты
Мы используем базу данных HSQL, которая является базой данных на основе памяти. Сценарий будет выглядеть так, как показано ниже.
Скрипт SQL
|
1
2
3
4
5
6
7
|
DROP TABLE employee IF EXISTS;CREATE TABLE employee ( person_id BIGINT IDENTITY NOT NULL PRIMARY KEY, first_name VARCHAR(20), last_name VARCHAR(20)); |
Spring Boot запускает schema-@@platform@@.sql автоматически при запуске. -all по умолчанию для всех платформ. Таким образом, создание таблицы произойдет само по себе при запуске приложения и будет доступно до тех пор, пока приложение не будет запущено и запущено.
4.4 Модельный класс
Мы собираемся создать класс Employee.java как класс модели. Класс будет выглядеть так, как показано ниже.
Модельный класс для Программы
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
package com.batch;public class Employee { private String lastName; private String firstName; public Employee() { } public Employee(String firstName, String lastName) { this.firstName = firstName; this.lastName = lastName; } public void setFirstName(String firstName) { this.firstName = firstName; } public String getFirstName() { return firstName; } public String getLastName() { return lastName; } public void setLastName(String lastName) { this.lastName = lastName; } @Override public String toString() { return "firstName: " + firstName + ", lastName: " + lastName; } } |
@Override используется для переопределения реализации по умолчанию метода toString() .
4.5 Класс конфигурации
Мы создадим класс BatchConfiguration.java который будет классом конфигурации для пакетной обработки. Файл Java будет выглядеть так, как показано ниже.
BatchConfiguration.java
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
|
package com.batch.config;import javax.sql.DataSource;import org.springframework.batch.core.Job;import org.springframework.batch.core.JobExecutionListener;import org.springframework.batch.core.Step;import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;import org.springframework.batch.core.launch.support.RunIdIncrementer;import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider;import org.springframework.batch.item.database.JdbcBatchItemWriter;import org.springframework.batch.item.database.builder.JdbcBatchItemWriterBuilder;import org.springframework.batch.item.file.FlatFileItemReader;import org.springframework.batch.item.file.builder.FlatFileItemReaderBuilder;import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;import org.springframework.batch.item.file.mapping.DefaultLineMapper;import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.core.io.ClassPathResource;import org.springframework.jdbc.core.JdbcTemplate;import com.batch.Employee;import com.batch.processor.EmployeeItemProcessor;@Configuration@EnableBatchProcessingpublic class BatchConfiguration { @Autowired public JobBuilderFactory jobBuilderFactory; @Autowired public StepBuilderFactory stepBuilderFactory; // tag::readerwriterprocessor[] @Bean public FlatFileItemReader reader() { return new FlatFileItemReaderBuilder() .name("EmployeeItemReader") .resource(new ClassPathResource("sample-data.csv")) .delimited() .names(new String[]{"firstName", "lastName"}) .fieldSetMapper(new BeanWrapperFieldSetMapper() {{ setTargetType(Employee.class); }}) .build(); } @Bean public EmployeeItemProcessor processor() { return new EmployeeItemProcessor(); } @Bean public JdbcBatchItemWriter writer(DataSource dataSource) { return new JdbcBatchItemWriterBuilder() .itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>()) .sql("INSERT INTO employee (first_name, last_name) VALUES (:firstName, :lastName)") .dataSource(dataSource) .build(); } // end::readerwriterprocessor[] // tag::jobstep[] @Bean public Job importUserJob(JobCompletionNotificationListener listener, Step step1) { return jobBuilderFactory.get("importUserJob") .incrementer(new RunIdIncrementer()) .listener(listener) .flow(step1) .end() .build(); } @Bean public Step step1(JdbcBatchItemWriter writer) { return stepBuilderFactory.get("step1") .<Employee, Employee> chunk(10) .reader(reader()) .processor(processor()) .writer(writer) .build(); } // end::jobstep[]} |
@EnableBatchProcessing аннотация используется для включения пакетной обработки.
JobBuilderFactory — это фабрика, которая используется для создания работы.
StepBuilderFactory используется для создания шага.
Метод step1() имеет свойство chunk() . Это свойство используется для разбиения входных данных на определенный размер. Для нас размер 10.
4.6 Предметный процессор
Предметный процессор — это интерфейс, который будет отвечать за обработку данных. Мы реализуем интерфейс в EmployeeItemProcessor.java . Класс Java будет выглядеть так, как показано ниже.
EmployeeItemProcessor.java
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
package com.batch.processor;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.batch.item.ItemProcessor;import com.batch.Employee;public class EmployeeItemProcessor implements ItemProcessor<Employee, Employee> { private static final Logger log = LoggerFactory.getLogger(EmployeeItemProcessor.class); @Override public Employee process(Employee emp) throws Exception { final String firstName = emp.getFirstName().toUpperCase(); final String lastName = emp.getLastName().toUpperCase(); final Employee transformedEmployee = new Employee(firstName, lastName); log.info("Converting (" + emp + ") into (" + transformedEmployee + ")"); return transformedEmployee; }} |
В методе process() мы будем получать данные и преобразовывать их в заглавные буквы.
4.7 Класс JobExecutionSupportListener
JobExecutionListenerSupport — это интерфейс, который будет уведомлять о завершении задания. Как часть интерфейса, у нас afterJob метод afterJob . Этот метод используется для публикации завершения работы.
JobCompletionNotificationListener.java
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
package com.batch.config;import java.util.List;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.batch.core.BatchStatus;import org.springframework.batch.core.JobExecution;import org.springframework.batch.core.listener.JobExecutionListenerSupport;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.jdbc.core.JdbcTemplate;import org.springframework.jdbc.core.RowMapper;import org.springframework.stereotype.Component;import com.batch.Employee;@Componentpublic class JobCompletionNotificationListener extends JobExecutionListenerSupport { private static final Logger log = LoggerFactory.getLogger(JobCompletionNotificationListener.class); private final JdbcTemplate jdbcTemplate; @Autowired public JobCompletionNotificationListener(JdbcTemplate jdbcTemplate) { this.jdbcTemplate = jdbcTemplate; } @Override public void afterJob(JobExecution jobExecution) { RowMapper rowMapper = (rs, rowNum) -> { Employee e = new Employee(); e.setFirstName(rs.getString(1)); e.setLastName(rs.getString(2)); return e; }; if(jobExecution.getStatus() == BatchStatus.COMPLETED) { log.info("!!! JOB FINISHED! Time to verify the results"); List empList= jdbcTemplate.query("SELECT first_name, last_name FROM employee",rowMapper); log.info("Size of List "+empList.size()); for (Employee emp: empList) { log.info("Found: "+emp.getFirstName()+" "+emp.getLastName()); } } }} |
В этом методе мы получаем данные из базы данных после завершения задания и печатаем результат на консоли, чтобы проверить обработку, которая была выполнена с данными.
4.8 Класс приложения
Мы создадим класс приложения, который будет содержать метод main, отвечающий за запуск пакетной программы Java. Класс будет выглядеть так, как показано ниже.
Application.java
|
01
02
03
04
05
06
07
08
09
10
11
|
package com.batch;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplicationpublic class Application { public static void main(String[] args) throws Exception { SpringApplication.run(Application.class, args); }} |
@SpringBootApplication — аннотация, используемая для указания программы в качестве программы начальной загрузки.
5. Выход
Давайте выполним приложение как приложение Java. Мы получим следующий вывод на консоль.
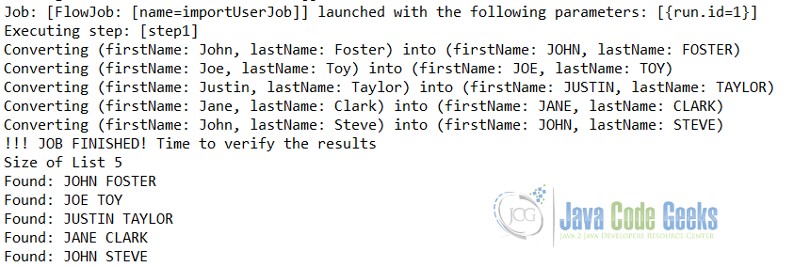
Вывод программы JavaBatch
Рабочий процесс пакетной программы очень четко доступен в выводе. Задание начинается с importUserJob , затем начинается выполнение шага 1, где оно преобразует прочитанные данные в верхний регистр.
Постобработка шага, мы можем увидеть результат в верхнем регистре на консоли.
6. Резюме
В этом уроке мы узнали следующие вещи:
- Пакет Java содержит задания, которые могут содержать несколько шагов.
- Каждый шаг — это сочетание чтения, обработки, записи.
- Мы можем разделить данные на части для обработки.
7. Скачать проект Eclipse
Это был учебник для JavaBatch с SpringBoot.