Поскольку эти файловые каналы работают асинхронно, интересно посмотреть на их производительность по сравнению с обычным вводом / выводом. Вторая часть посвящена таким проблемам, как потребление памяти и ЦП, и объясняет, как безопасно использовать новые каналы NIO.2 в сценарии с высокой производительностью. Вы также должны понимать, как закрыть асинхронные каналы без потери данных, это третья часть. Наконец, в четвертой части мы рассмотрим параллелизм.
Примечание: я не буду объяснять полный API асинхронных файловых каналов. Есть достаточно постов, которые хорошо справляются с этим. Мои посты больше отражают практическую применимость и проблемы, которые могут возникнуть при использовании асинхронных файловых каналов.
Хорошо, достаточно смутных разговоров, начнем. Вот фрагмент кода, который открывает асинхронный канал (строка 7), записывает последовательность байтов в начало файла (строка 9) и ожидает возврата результата (строка 10). Наконец, в строке 14 канал закрыт.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
public class CallGraph_Default_AsynchronousFileChannel { private static AsynchronousFileChannel fileChannel; public static void main(String[] args) throws InterruptedException, IOException, ExecutionException { try { fileChannel = AsynchronousFileChannel.open(Paths.get("E:/temp/afile.out"), StandardOpenOption.READ, StandardOpenOption.WRITE, StandardOpenOption.CREATE, StandardOpenOption.DELETE_ON_CLOSE); Future<Integer> future = fileChannel.write(ByteBuffer.wrap("Hello".getBytes()), 0L); future.get(); } catch (Exception e) { e.printStackTrace(); } finally { fileChannel.close(); } }} |
Важные участники асинхронных вызовов файлового канала
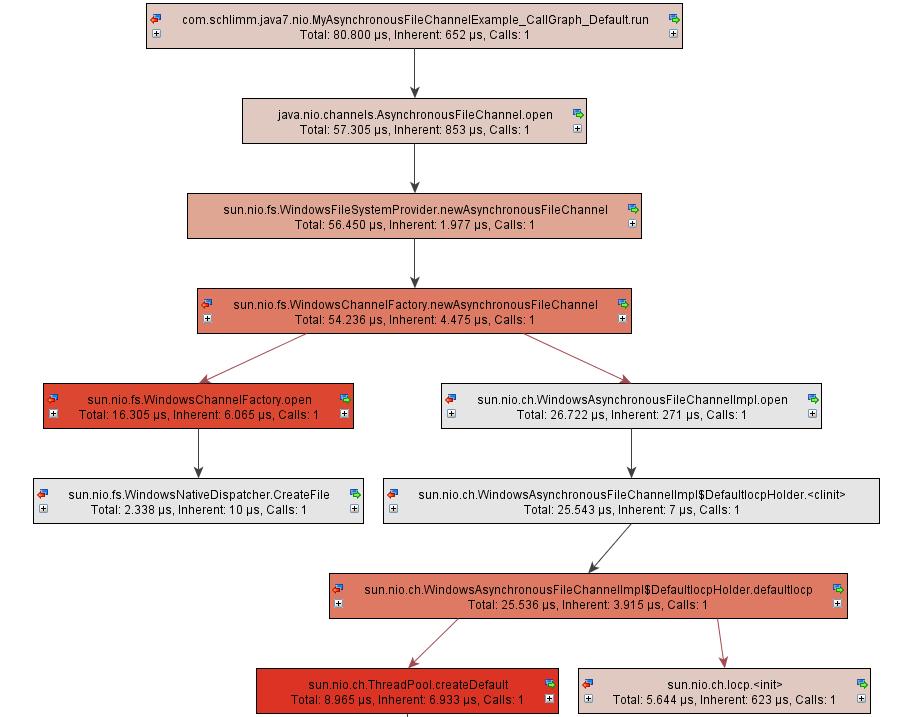
Прежде чем я углублюсь в код, давайте быстро введем концепции, связанные с асинхронным (файловым) каналом галактики. Callgraph на рисунке 1 показывает диаграмму последовательности при вызове метода open () класса AsynchronousFileChannel. FileSystemProvider инкапсулирует все особенности операционных систем. Чтобы развлечь всех, я использую клиент Windows XP, когда пишу это. Поэтому WindowsFileSystemProvider вызывает WindowsChannelFactory, которая фактически создает файл, и вызывает WindowsAsynchronousFileChannelImpl, который возвращает сам экземпляр. Наиболее важной концепцией является Iocp, порт завершения ввода / вывода. Это API для выполнения нескольких одновременных асинхронных операций ввода / вывода. Создается объект порта завершения, связанный с несколькими дескрипторами файлов. Когда для объекта запрашиваются услуги ввода / вывода, завершение указывается сообщением, помещенным в очередь в порт завершения ввода / вывода. Другие процессы, запрашивающие услуги ввода / вывода, не уведомляются о завершении служб ввода / вывода, а вместо этого проверяют очередь сообщений порта завершения ввода / вывода, чтобы определить состояние своих запросов ввода / вывода. Порт завершения ввода / вывода управляет несколькими потоками и их параллелизмом. Как видно из диаграммы, Iocp является подтипом AsynchronousChannelGroup. Таким образом, в асинхронных каналах JDK 7 асинхронная группа каналов реализована как порт завершения ввода-вывода. Он владеет ThreadPool, отвечающим за выполнение запрошенной операции асинхронного ввода-вывода. ThreadPool фактически инкапсулирует ThreadPoolExecutor, который выполняет все управление многопоточным асинхронным выполнением задач начиная с Java 1.5. Операции записи в асинхронные файловые каналы приводят к вызовам метода ThreadPoolExecutor.execute ().
Некоторые тесты
Всегда интересно посмотреть на представление. Асинхронный неблокирующий ввод / вывод должен быть быстрым, верно? Чтобы найти ответ на этот вопрос, я провел анализ производительности. Опять же, для этого я использую крошечную систему тестирования Heinz. Моя машина — процессор Intel Core i5-2310 с частотой 2,90 ГГц и четырьмя ядрами (64-разрядные). В тесте мне нужна базовая линия. Моя базовая линия — простая обычная синхронная операция записи в обычный файл. Вот фрагмент:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
public class Performance_Benchmark_ConventionalFileAccessExample_1 implements Runnable { private static FileOutputStream outputfile; private static byte[] content = "Hello".getBytes(); public static void main(String[] args) throws InterruptedException, IOException { try { System.out.println("Test: " + Performance_Benchmark_ConventionalFileAccessExample_1.class.getSimpleName()); outputfile = new FileOutputStream(new File("E:/temp/afile.out"), true); Average average = new PerformanceHarness().calculatePerf(new PerformanceChecker(1000, new Performance_Benchmark_ConventionalFileAccessExample_1()), 5); System.out.println("Mean: " + DecimalFormat.getInstance().format(average.mean())); System.out.println("Std. Deviation: " + DecimalFormat.getInstance().format(average.stddev())); } catch (Exception e) { e.printStackTrace(); } finally { new SystemInformation().printThreadInfo(true); outputfile.close(); new File("E:/temp/afile.out").delete(); } } @Override public void run() { try { outputfile.write(content); // append content } catch (IOException e) { e.printStackTrace(); } }} |
Как видно из строки 25, тест выполняет одну операцию записи в обычный файл. И вот результаты:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
Test: Performance_Benchmark_ConventionalFileAccessExample_1Warming up ...EPSILON:20:TESTTIME:1000:ACTTIME:1014:LOOPS:365947EPSILON:20:TESTTIME:1000:ACTTIME:1014:LOOPS:372298Starting test intervall ...EPSILON:20:TESTTIME:1000:ACTTIME:1000:LOOPS:364706EPSILON:20:TESTTIME:1000:ACTTIME:1014:LOOPS:368309EPSILON:20:TESTTIME:1000:ACTTIME:1014:LOOPS:370288EPSILON:20:TESTTIME:1000:ACTTIME:1001:LOOPS:364908EPSILON:20:TESTTIME:1000:ACTTIME:1014:LOOPS:370820Mean: 367.806,2Std. Deviation: 2.588,665Total started thread count: 12Peak thread count: 6Deamon thread count: 4Thread count: 5 |
Следующий фрагмент является еще одним тестом, который также выполняет операцию записи (строка 25), на этот раз в асинхронный файловый канал:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
public class Performance_Benchmark_AsynchronousFileChannel_1 implements Runnable { private static AsynchronousFileChannel outputfile; private static int fileindex = 0; public static void main(String[] args) throws InterruptedException, IOException { try { System.out.println("Test: " + Performance_Benchmark_AsynchronousFileChannel_1.class.getSimpleName()); outputfile = AsynchronousFileChannel.open(Paths.get("E:/temp/afile.out"), StandardOpenOption.WRITE, StandardOpenOption.CREATE, StandardOpenOption.DELETE_ON_CLOSE); Average average = new PerformanceHarness().calculatePerf(new PerformanceChecker(1000, new Performance_Benchmark_AsynchronousFileChannel_1()), 5); System.out.println("Mean: " + DecimalFormat.getInstance().format(average.mean())); System.out.println("Std. Deviation: " + DecimalFormat.getInstance().format(average.stddev())); } catch (Exception e) { e.printStackTrace(); } finally { new SystemInformation().printThreadInfo(true); outputfile.close(); } } @Override public void run() { outputfile.write(ByteBuffer.wrap("Hello".getBytes()), fileindex++ * 5); }} |
Это результат вышеуказанного теста на моей машине:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
Test: Performance_Benchmark_AsynchronousFileChannel_1Warming up ...EPSILON:20:TESTTIME:1000:ACTTIME:1015:LOOPS:42667EPSILON:20:TESTTIME:1000:ACTTIME:1015:LOOPS:193351Starting test intervall ...EPSILON:20:TESTTIME:1000:ACTTIME:1015:LOOPS:191268EPSILON:20:TESTTIME:1000:ACTTIME:1015:LOOPS:186916EPSILON:20:TESTTIME:1000:ACTTIME:1014:LOOPS:189842EPSILON:20:TESTTIME:1000:ACTTIME:1014:LOOPS:191103EPSILON:20:TESTTIME:1000:ACTTIME:1015:LOOPS:192005Mean: 190.226,8Std. Deviation: 1.795,733Total started thread count: 17Peak thread count: 11Deamon thread count: 9Thread count: 10 |
Поскольку приведенные выше фрагменты делают то же самое, можно с уверенностью сказать, что каналы асинхронных файлов не обязательно быстрее, чем обычные операции ввода-вывода. Это интересный результат, я думаю. Трудно сравнивать обычные операции ввода-вывода и NIO.2 друг с другом в однопоточном тесте. NIO.2 был введен для обеспечения техники ввода / вывода в сильно параллельных сценариях. Поэтому спрашивать, что быстрее — NIO или обычный ввод / вывод — не совсем правильный вопрос. Соответствующий вопрос был: что является «более параллельным»? Однако пока вышеприведенные результаты предполагают:
Попробуйте использовать обычный ввод-вывод, когда только один поток выполняет операции ввода-вывода.
Пока этого достаточно. Я объяснил основные концепции, а также указал, что традиционный ввод-вывод все еще имеет право на существование. Во втором посте я расскажу о некоторых проблемах, с которыми вы можете столкнуться при использовании асинхронных файловых каналов по умолчанию. Я также покажу, как избежать этих проблем, применяя более жизнеспособные настройки.
Применение пользовательских пулов потоков
Асинхронная обработка файлов не является зеленой картой для высокой производительности. В своем последнем посте я продемонстрировал, что обычный ввод-вывод может быть быстрее, чем асинхронные каналы. Есть несколько дополнительных важных фактов, которые следует знать при применении файловых каналов NIO.2. Класс Iocp, который выполняет все задачи асинхронного ввода-вывода в файловых каналах NIO.2, по умолчанию поддерживается так называемым «кэшированным» пулом потоков. Это пул потоков, который создает новые потоки по мере необходимости, но будет повторно использовать ранее созданные потоки *, когда они станут доступны. Посмотрите на код класса ThreadPool, поддерживаемый Iocp.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public class ThreadPool {... private static final ThreadFactory defaultThreadFactory = new ThreadFactory() { @Override public Thread newThread(Runnable r) { Thread t = new Thread(r); t.setDaemon(true); return t; } };... static ThreadPool createDefault() { ... ExecutorService executor = new ThreadPoolExecutor(0, Integer.MAX_VALUE, Long.MAX_VALUE, TimeUnit.MILLISECONDS, new SynchronousQueue<Runnable>(), threadFactory); return new ThreadPool(executor, false, initialSize); }...} |
Пул потоков в группе каналов по умолчанию создается как ThreadPoolExecutor с максимальным числом потоков Integer.MAX_VALUE и временем поддержания активности Long.MAX_VALUE. Потоки создаются как потоки демонов фабрикой потоков. Синхронная очередь передачи используется для запуска создания потока, если все потоки заняты. Есть несколько проблем с этой конфигурацией:
- Если вы выполняете операции записи на асинхронных каналах в пакете, вы создадите тысячи рабочих потоков, что, вероятно, приведет к OutOfMemoryError: не в состоянии создать новый собственный поток.
- Когда JVM завершает работу, все нити-демоны удаляются — наконец, блоки не выполняются, стеки не разматываются.
В моем другом блоге я объяснил, почему неограниченные пулы потоков могут вызвать проблемы. Поэтому, если вы используете асинхронные файловые каналы, возможно, вы захотите использовать пользовательские пулы потоков вместо пула потоков по умолчанию. В следующем фрагменте показан пример пользовательской настройки.
|
1
2
3
4
5
6
7
8
|
ThreadPoolExecutor pool = newThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(2500));pool.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());AsynchronousFileChannel outputfile = AsynchronousFileChannel.open(Paths.get(FILE_NAME), new HashSet<Standardopenoption>(Arrays.asList(StandardOpenOption.WRITE, StandardOpenOption.CREATE)), pool); |
В Javadoc AsynchronousFileChannel говорится, что пользовательский исполнитель должен «минимально […] поддерживать неограниченную рабочую очередь и не должен запускать задачи в потоке вызывающего метода execute». Это рискованное утверждение, оно разумно, только если ресурсы не являются проблемой, что редко бывает. Возможно, имеет смысл использовать ограниченные пулы потоков для асинхронных файловых каналов. Вы не можете получить проблему со слишком большим количеством потоков, а также не можете заполнить свою кучу задачами рабочей очереди. В приведенном выше примере у вас есть пять потоков, которые выполняют асинхронные задачи ввода-вывода, а рабочая очередь имеет емкость 2500 задач. Если предел емкости превышен, обработчик отклоненного выполнения реализует CallerRunsPolicy, где клиент должен синхронно выполнять задачу записи. Это может (значительно) замедлить производительность системы, поскольку рабочая нагрузка «передается» клиенту и выполняется синхронно. Тем не менее, это также может спасти вас от гораздо более серьезных проблем, когда результат непредсказуем. Рекомендуется работать с ограниченными пулами потоков и сохранять размеры пула потоков настраиваемыми, чтобы их можно было настраивать во время выполнения. Опять же, чтобы узнать больше о надежных настройках пула потоков, смотрите мою другую запись в блоге.
Пулы потоков с синхронными очередями передачи и несвязанными максимальными размерами пула потоков могут агрессивно создавать новые потоки и, таким образом, могут серьезно подорвать стабильность системы, потребляя (регистры ПК и стеки Java) оперативную память JVM. Чем «длиннее» (истекшее время) асинхронная задача, тем больше вероятность, что вы столкнетесь с этой проблемой.
Пулы потоков с неограниченными рабочими очередями и фиксированным размером пула потоков могут агрессивно создавать новые задачи и объекты и, таким образом, могут серьезно повредить стабильности системы, потребляя кучу памяти и ЦП из-за чрезмерной активности по сбору мусора. Чем больше (по размеру) и длиннее (по прошествии времени) асинхронная задача, тем больше вероятность возникновения этой проблемы.
Это все с точки зрения применения пользовательских пулов потоков к асинхронным файловым каналам. Мой следующий блог из этой серии расскажет, как безопасно закрыть асинхронные каналы без потери данных.
Ссылка: Java 7 # 7: Каналы файлов NIO.2 на стенде тестирования — Часть 1. Введение, Java 7 # 8: Каналы файлов NIO.2 на стенде испытаний — Часть 2 — Применение пользовательских пулов потоков от нашего партнера JCG Никласа.