Задумывались ли вы, как коммит и его содержимое хранятся в Git? Ну, у меня есть, и у меня было немного свободного времени в последние дождливые выходные, поэтому я провел небольшое исследование.
Поскольку я чувствую себя как дома с Java, а не с Bash, я использовал JGit и пару учебных тестов для изучения внутренних возможностей коммитов Git. Вот мои выводы:
Git — База данных объектов
Git по сути — это простое хранилище данных с адресной информацией Это означает, что вы можете вставить любой контент в него, и он вернет ключ, который вы можете использовать для получения данных снова в более поздний момент времени.
В случае Git ключом является 20-байтовый хэш SHA-1, который вычисляется из содержимого. Содержимое также упоминается как объект в терминологии Git, и, следовательно, хранилище данных также называется объектной базой данных .
Давайте посмотрим, как JGit можно использовать для хранения и извлечения контента.
Blobs
В JGit ObjectInserter используется для хранения контента в базе данных объектов. Это можно рассматривать как грубый эквивалент git hash-object в Git.
С его методом insert () вы можете записать объект в хранилище данных, тогда как его методы idFor () вычисляют только хэш SHA-1 заданных байтов. Следовательно, код для хранения строки выглядит так:
|
1
2
3
4
|
ObjectInserter objectInserter = repository.newObjectInserter();byte[] bytes = "Hello World!".getBytes( "utf-8" );ObjectId blobId = objectInserter.insert( Constants.OBJ_BLOB, bytes );objectInserter.flush(); |
Во всех примерах кода предполагается, что репозиторий varaible указывает на пустой репозиторий , созданный вне фрагмента.
Первый параметр обозначает тип объекта для вставляемого объекта, в данном случае тип BLOB-объекта. Существуют и другие типы объектов, о которых мы узнаем позже. Тип BLOB-объекта используется для хранения произвольного содержимого.
Полезная нагрузка должна быть задана во втором параметре, в этом случае в виде байтового массива. Перегруженный метод, который принимает InputStream, также доступен.
И наконец, ObjectInserter должен быть сброшен, чтобы сделать изменения видимыми для других, получающих доступ к хранилищу.
Метод insert () возвращает хеш SHA-1, который вычисляется из типа, длины содержимого и байтов содержимого. Однако в JGit хэш SHA-1 представлен через класс ObjectId, неизменную структуру данных, которая может быть преобразована в байты, целые числа и строки и обратно.
Теперь вы можете использовать возвращенный blobId для извлечения содержимого и, таким образом, убедиться, что приведенный выше код действительно записал содержимое.
|
1
2
3
4
5
|
ObjectReader objectReader = repository.newObjectReader();ObjectLoader objectLoader = objectReader.open( blobId );int type = objectLoader.getType(); // Constants.OBJ_BLOBbyte[] bytes = objectLoader.getBytes();String helloWorld = new String( bytes, "utf-8" ) // Hello World! |
Метод open () ObjectReader возвращает ObjectLoader, который можно использовать для доступа к объекту, идентифицированному данным идентификатором объекта. С помощью ObjectLoader вы можете получить тип объекта, его размер и, конечно, его содержимое в виде байтового массива или потока.
Чтобы убедиться, что объект, написанный JGit, совместим с собственным Git, вы можете получить его содержимое с помощью git cat-file .
|
1
2
3
4
|
$ git cat-file -p c57eff55ebc0c54973903af5f72bac72762cf4f4Hello World!git cat-file -t c57eff55ebc0c54973903af5f72bac72762cf4f4blob |
Если вы загляните в каталог .git/objects хранилища, вы найдете каталог с именем «c5» с файлом «7eff55ebc0c54973903af5f72bac72762cf4f4». Вот как содержимое хранится изначально: как отдельный файл на объект, названный с помощью хеша SHA-1 содержимого. Подкаталог именуется первыми двумя символами SHA-1, а имя файла состоит из оставшихся символов.
Теперь, когда вы можете сохранить содержимое файла, следующим шагом будет сохранение его имени. И, вероятно, также больше, чем один файл, поскольку коммит обычно состоит из группы файлов. Для хранения такого рода информации Git использует так называемые древовидные объекты.
Объекты дерева
Древовидный объект можно рассматривать как упрощенную структуру файловой системы, которая содержит информацию о файлах и каталогах.
Он содержит любое количество записей дерева. Каждая запись имеет путь, файловый режим и указывает либо на содержимое файла (объект blob), либо на другой (под) объект дерева, если она представляет каталог. Указатель, конечно, является хешем SHA-1 объекта blob или дерева.
Для начала вы можете создать дерево, содержащее одну запись для файла с именем ‘hello-world.txt’, который указывает на сохраненный выше ‘Hello World!’ содержание.
|
1
2
3
4
|
TreeFormatter treeFormatter = new TreeFormatter();treeFormatter.append( "hello-world.txt", FileMode.REGULAR_FILE, blobId );ObjectId treeId = objectInserter.insert( treeFormatter );objectInserter.flush(); |
TreeFormatter используется здесь для создания объекта дерева в памяти. При вызове append () добавляется запись с указанным именем пути, режимом и идентификатором, под которым хранится ее содержимое.
По сути, вы можете выбрать любой путь. Однако Git ожидает, что имя пути будет относительно рабочего каталога без начального символа ‘/’.
Режим файла, используемый здесь, указывает на нормальный файл. Другими режимами являются EXECUTABLE_FILE, что означает, что это исполняемый файл, и SYMLINK, который указывает символическую ссылку. Для записей каталога режим файла всегда TREE.
Опять же, вам понадобится ObjectInserter. Один из его перегруженных методов insert () принимает TreeFormatter и записывает его в базу данных объектов.
Теперь вы можете использовать TreeWalk для извлечения и изучения объекта дерева:
|
1
2
3
4
|
TreeWalk treeWalk = new TreeWalk( repository );treeWalk.addTree( treeId );treeWalk.next();String filename = treeWalk.getPathString(); // hello-world.txt |
На самом деле TreeWalk предназначен для перебора добавленных деревьев и их поддеревьев. Но поскольку мы знаем, что существует ровно одна запись, достаточно одного вызова next ().
Если вы посмотрите на только что написанный объект дерева с родным Git, вы увидите следующее:
|
1
2
|
$ git cat-file -p 44d52a975c793e5a4115e315b8d89369e2919e51100644 blob c57eff55ebc0c54973903af5f72bac72762cf4f4 hello-world.txt |
Теперь, когда у вас есть необходимые ингредиенты для фиксации, давайте создадим сам объект фиксации.
Зафиксировать объекты
Объект коммитов ссылается на файлы (через древовидный объект), которые составляют коммит, вместе с некоторыми метаданными. Подробно коммит состоит из:
- указатель на объект дерева
- указатели на ноль или более родительских коммитов (подробнее об этом позже)
- сообщение коммита
- и автор и коммиттер
Поскольку объект фиксации является просто еще одним объектом в базе данных объектов, он также запечатывается с помощью хеша SHA-1, который был вычислен по его содержимому.
Чтобы сформировать объект фиксации, JGit предлагает служебный класс CommitBuilder.
|
1
2
3
4
5
6
7
8
9
|
CommitBuilder commitBuilder = new CommitBuilder();commitBuilder.setTreeId( treeId );commitBuilder.setMessage( "My first commit!" );PersonIdent person = new PersonIdent( "me", "me@example.com" );commitBuilder.setAuthor( person );commitBuilder.setCommitter( person );ObjectInserter objectInserter = repository.newObjectInserter();ObjectId commitId = objectInserter.insert( commitBuilder );objectInserter.flush(); |
Использовать его просто, он имеет методы установки для всех атрибутов коммита.
Автор и коммиттер представлены через класс PersonIdent, который содержит имя, адрес электронной почты, метку времени и часовой пояс. Используемый здесь конструктор применяет имя и адрес электронной почты и принимает текущее время и часовой пояс.
А остальное должно быть уже знакомо: ObjectInserter используется для фактической записи объекта фиксации и возвращает идентификатор фиксации.
Чтобы извлечь объект фиксации из хранилища, вы снова можете использовать ObjectReader:
|
1
2
3
|
ObjectReader objectReader = repository.newObjectReader();ObjectLoader objectLoader = objectReader.open( commitId );RevCommit commit = RevCommit.parse( objectLoader.getBytes() ); |
Результирующий RevCommit представляет коммит с теми же атрибутами, которые были указаны в CommitBuilder.
И еще раз — перепроверить — вывод git cat-file :
|
1
2
3
4
5
6
|
$ git cat-file -p 783341299c95ddda51e6b2393c16deaf0c92d5a0tree 4b825dc642cb6eb9a060e54bf8d69288fbee4904author me <me@example.com> 1412872859 +0200committer me <me@example.com> 1412872859 +0200My first commit! |
Родители
Цепочка родителей формирует историю Git-репозитория и моделирует направленный ациклический граф . Это означает, что коммиты следуют в одном направлении
Коммит может иметь ноль или более родителей. Первый коммит в репозитории не имеет родителя (он же корневой коммит). Второй коммит, в свою очередь, имеет первый в качестве родителя и так далее.
Совершенно законно создавать более одного корневого коммита. Если вы используете git checkout --orphan new_branch то будет создана git checkout --orphan new_branch ветвь и переключена на git checkout --orphan new_branch . Первый коммит, сделанный в этой ветке, не будет иметь родителей и сформирует корень новой истории, которая не связана со всеми другими коммитами.
Если вы начинаете ветвление и в конечном итоге объединяете расходящиеся линии изменений, это обычно приводит к фиксации слияния . И такой коммит имеет главные комитеты расходящихся ветвей, как и его родители.
Чтобы создать родительский коммит, необходимо указать идентификатор родительского коммита в CommitBuilder.
|
1
|
commitBuilder.setParents( parentId ); |
Класс RevCommit, представляющий коммит в репозитории, также может быть запрошен относительно его родителей. Его методы getParents () и getParent (int) возвращают все или n-й родительский RevCommit.
Имейте в виду, однако, что хотя методы возвращают RevCommits, они не полностью разрешены. Пока установлен их атрибут ID, все остальные атрибуты (fullMessage, автор, коммиттер и т. Д.) Не установлены. Таким образом, попытка вызвать parent.getFullMessage (), например, вызовет исключение NullPointerException. Чтобы фактически использовать родительский коммит, вам нужно либо получить полный RevCommit с помощью ObjectReader, как описано выше, либо использовать RevWalk для загрузки и анализа заголовка коммита:
|
1
2
|
RevWalk revWalk = new RevWalk( repository );revWalk.parseHeaders( parentCommit ); |
В общем, имейте в виду, что возвращенные родительские коммиты обрабатываются так, как если бы они были ObjectIds вместо RevCommits.
Подробнее о древовидных объектах
Если вы хотите хранить файлы в подкаталогах, вам нужно создать их самостоятельно. Скажем, вы хотите сохранить содержимое файла ‘file.txt’ в папке ‘folder’.
Сначала создайте и сохраните TreeFormatter для поддерева, в котором есть запись для файла:
|
1
2
3
|
TreeFormatter subtreeFormatter = new TreeFormatter();subtreeFormatter.append( "file.txt", FileMode.REGULAR_FILE, blobId );ObjectId subtreeId = objectInserter.insert( subtreeFormatter ); |
Затем создайте и сохраните TreeFormatter с записью, которая обозначает папку и указывает на только что созданное поддерево.
|
1
2
3
|
TreeFormatter treeFormatter = new TreeFormatter();treeFormatter.append( "folder", FileMode.TREE, subtreeId );ObjectId treeId = objectInserter.insert( treeFormatter ); |
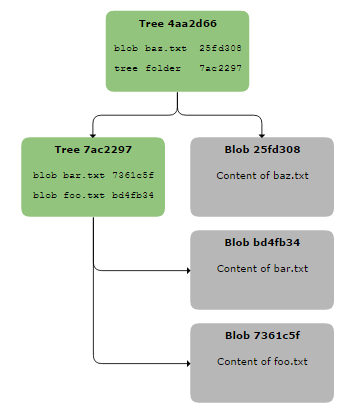
Файловым режимом записи является TREE для указания каталога и его идентификатора, указывающего на поддерево, содержащее запись файла. Возвращенный treeId — это тот, который будет передан в CommitBuilder.
Git требует определенного порядка сортировки для записей в древовидных объектах. Документ ‘Git Data Formats’, который я нашел здесь, утверждает, что:
Записи дерева сортируются по последовательности байтов, которая содержит имя записи. Однако для целей сравнения сортировки записи для объектов дерева сравниваются, как если бы последовательность байтов имени записи имела завершающий ASCII ‘/’ (0x2f).
Для чтения содержимого объекта дерева вы снова можете использовать TreeWalk. Но на этот раз вам нужно указать это, чтобы перейти в поддеревья, если вы хотите посетить все записи. А также не забудьте установить для postOrderTraversal значение true, если вы хотите видеть записи, указывающие на дерево. В противном случае они будут пропущены.
В конечном итоге весь цикл TreeWalk будет выглядеть так:
|
01
02
03
04
05
06
07
08
09
10
|
TreeWalk treeWalk = new TreeWalk( repository );treeWalk.addTree( treeId );treeWalk.setRecursive( true );treeWalk.setPostOrderTraversal( true );while( treeWalk.next() ) { int fileMode = Integer.parseInt( treeWalk.getFileMode( 0 ).toString() ); String objectId = treeWalk.getObjectId( 0 ).name(); String path = treeWalk.getPathString(); System.out.println( String.format( "%06d %s %s", fileMode, objectId, path ) );} |
… и приведет к такому выводу:
|
1
2
|
100644 6b584e8ece562ebffc15d38808cd6b98fc3d97ea folder/file.txt 040000 541550ddcf8a29bcd80b0800a142a7d47890cfd6 folder |
Хотя я нахожу, что API не очень интуитивно понятен, он выполняет свою работу и раскрывает все детали объекта дерева.
Заключительные Git Internals
Нет сомнений, что для распространенных случаев использования высокоуровневые команды Add- и CommitCommands являются рекомендуемым способом фиксации файлов в хранилище. Тем не менее, я посчитал целесообразным углубиться в более глубокие уровни JGit и Git и надеюсь, что вы тоже это сделали. И в — по общему признанию менее распространенном — случае, когда вам необходимо зафиксировать файлы в хранилище без рабочего каталога и / или индекса, приведенная здесь информация может помочь.
Если вы хотите попробовать примеры, перечисленные здесь, для себя, я рекомендую настроить JGit с доступом к его источникам и JavaDoc так, чтобы у вас была значимая контекстная информация, справка по контенту, источники отладки и т. Д.
- Полный исходный код размещен здесь: https://gist.github.com/rherrmann/02d8d4fe81bb60d9049e.
Для краткости примеры, показанные здесь, опускают код для освобождения выделенных ресурсов. Пожалуйста, обратитесь к полному исходному коду, чтобы получить все детали.
| Ссылка: | Исследуйте Git Internals с помощью JGit API от нашего партнера JCG Рудигера Херрманна в блоге Code Affine . |