Google предоставляет довольно интересные данные о гриппе в формате CSV , и я хотел отобразить их на графике в Dash . Однако необработанные данные не совсем подходят для моих нужд:
- Он содержит несколько вводных / заголовочных текстов (авторские права, описание данных и т. Д.), А Dash нужны только необработанные данные.
- Он показывает десятки штатов / регионов / городов, и я просто хочу показать общие данные США и мой родной штат.
К счастью, Dash может читать данные с любой общедоступной конечной точки, поэтому я решил собрать быстрое
приложение Node.js , чтобы преобразовать данные в то, что мне нужно. Наиболее простым решением было, вероятно, загрузить весь файл, прочитать его построчно, создать массив данных, а затем записать его. А поскольку объем данных в настоящее время составляет чуть менее 400 КБ, возможно, это было бы хорошо. Но лучшая модель (и более увлекательная, IMO) — это использование потоков узлов. Пока мы используем потоки на протяжении всего процесса, мы можем быть уверены, что в любой момент времени в памяти сохраняется только небольшой буфер.
Если вы просто хотите увидеть полное приложение,
оно на GitHub . В противном случае, читайте дальше, чтобы увидеть мой мыслительный процесс.
Отфильтровать вступление / заголовок текста
Сначала мы напишем поток, который отфильтровывает информацию об авторском праве / обзоре и передает остальные:
var stream = require('stream')
, util = require('util')
function CleanIntro(options) {
stream.Transform.call(this, options)
}
util.inherits(CleanIntro, stream.Transform)
CleanIntro.prototype._transform = function (chunk, enc, cb) {
if (this.readingData) {
this.push(chunk, enc)
} else {
// Ignore all text until we find a line beginning with 'Date,''
var start = chunk.toString().search(/^Date,/m)
if (start !== -1) {
this.readingData = true
this.push(chunk.slice(start), enc)
}
}
cb()
}
Поток Transform просто берет данные, которые были переданы из другого потока, делает с ним все, что хочет, а затем выталкивает обратно все, что хочет. В нашем случае мы просто игнорируем что-либо до начала фактических данных, а затем отбрасываем оставшиеся данные обратно. Легко.
Разобрать данные CSV
Теперь, когда у нас есть фильтр для получения только необработанных данных CSV, мы можем начать его анализ. Есть много библиотек разбора CSV; Мне нравится
CSV-поток, потому что, ну, это поток. Итак, наш основной процесс — сделать HTTP-запрос, направить его в наш фильтр очистки заголовка, затем направить его в csv-stream и начать работать с данными:
var request = require('request')
, csv = require('csv-stream')
, util = require('util')
, _ = require('lodash')
, moment = require('moment')
, OutStream = require('./out-stream')
, CleanIntroFilter = require('./clean-intro-filter')
// Returns a Stream that emits CSV records from Google Flu Trends.
// options:
// - regions: an array of regions for which data should be generated.
// See http://www.google.org/flutrends/us/data.txt for possible values
module.exports = function (options) {
options = _.extend({
regions: ['United States']
}, options)
var earliest = moment().subtract('years', 1)
request('http://www.google.org/flutrends/us/data.txt')
.pipe(new CleanIntroFilter())
.pipe(csv.createStream({}))
.on('error',function(err){
// Oops, got an error
})
.on('data',function(data) {
var date = moment(data.Date)
// Only return data from the past year
if (date.isAfter(earliest) || date.isSame(earliest)) {
// Let's build the output String...
console.log(data.Date + ',' + _.map(options.regions, function (region) {
return data[region]
}).join())
}
})
.on('end', function () {
// Okay we're done, now what?
})
}
Хорошо, теперь мы приближаемся. Мы создали выход CSV, но что нам с ним делать? Поместить все это в массив и вернуть это?
НЕТ! Помните, что мы потеряем преимущества тонкой памяти потоков, если не будем использовать их до конца.
Выпиши в другой поток
Вместо этого давайте просто сделаем наш собственный поток для записи:
var stream = require('stream')
var OutStream = function() {
stream.Transform.call(this,{objectMode: false})
}
OutStream.prototype = Object.create(
stream.Transform.prototype, {constructor: {value: OutStream}} )
OutStream.prototype._transform = function(chunk, encoding, callback) {
this.push(chunk, encoding)
callback && callback()
}
OutStream.prototype.write = function () {
this._transform.apply(this, arguments)
}
OutStream.prototype.end = function () {
this._transform.apply(this, arguments)
this.emit('end')
}
И теперь наша функция синтаксического анализа может вернуть этот поток и записать в него:
module.exports = function (options) {
options = _.extend({
regions: ['United States']
}, options)
var out = new OutStream()
out.write('Date,' + options.regions.join())
var earliest = moment().subtract('years', 1)
request('http://www.google.org/flutrends/us/data.txt')
.pipe(new CleanIntroFilter())
.pipe(csv.createStream({}))
.on('error',function(err){
out.emit('error', err)
})
.on('data',function(data) {
var date = moment(data.Date)
// Only return data from the past year
if (date.isAfter(earliest) || date.isSame(earliest)) {
out.write(data.Date + ',' + _.map(options.regions, function (region) {
return data[region]
}).join())
}
})
.on('end', function () {
out.end()
})
return out
}
Подайте это
Наконец, мы будем использовать
Express для предоставления наших данных в качестве веб-конечной точки:
var express = require('express')
, data = require('./lib/data')
, _ = require('lodash')
var app = express()
app.get('/', function(req, res){
var options = {}
if (req.query.region) {
options.regions = _.isArray(req.query.region) ? req.query.region : [req.query.region]
}
res.setHeader('Content-Type', 'text/csv')
data(options)
.on('data', function (data) {
res.write(data)
res.write('\n')
})
.on('end', function (data) {
res.end()
})
.on('error', function (err) {
console.log('error: ', error)
})
})
var port = process.env.PORT || 5000
app.listen(port)
console.log('Listening on port ' + port)
Еще раз отметим, что как только мы получаем данные из нашего потока, мы манипулируем и записываем их в другой поток (в данном случае HTTP-ответ). Это удерживает нас от ненужного хранения большого количества данных в памяти.
Теперь, если мы запустим сервер, мы можем использовать curl, чтобы увидеть его в действии:
$ curl 'http://localhost:5000' Date,United States 2012-11-04,2492 2012-11-11,2913 2012-11-18,3040 2012-11-25,3641 2012-12-02,4427 [and so on] $ curl 'http://localhost:5000?region=United%20States®ion=Pennsylvania' Date,United States,Pennsylvania 2012-11-04,2492,2579 2012-11-11,2913,2889 2012-11-18,3040,2785 2012-11-25,3641,3248 2012-12-02,4427,3679 [and so on]
Пока сервер работает в каком-то месте, доступном для общественности, мы можем перейти к
Dash и подключить его к виджету Custom Chart, что даст нам что-то вроде этого:
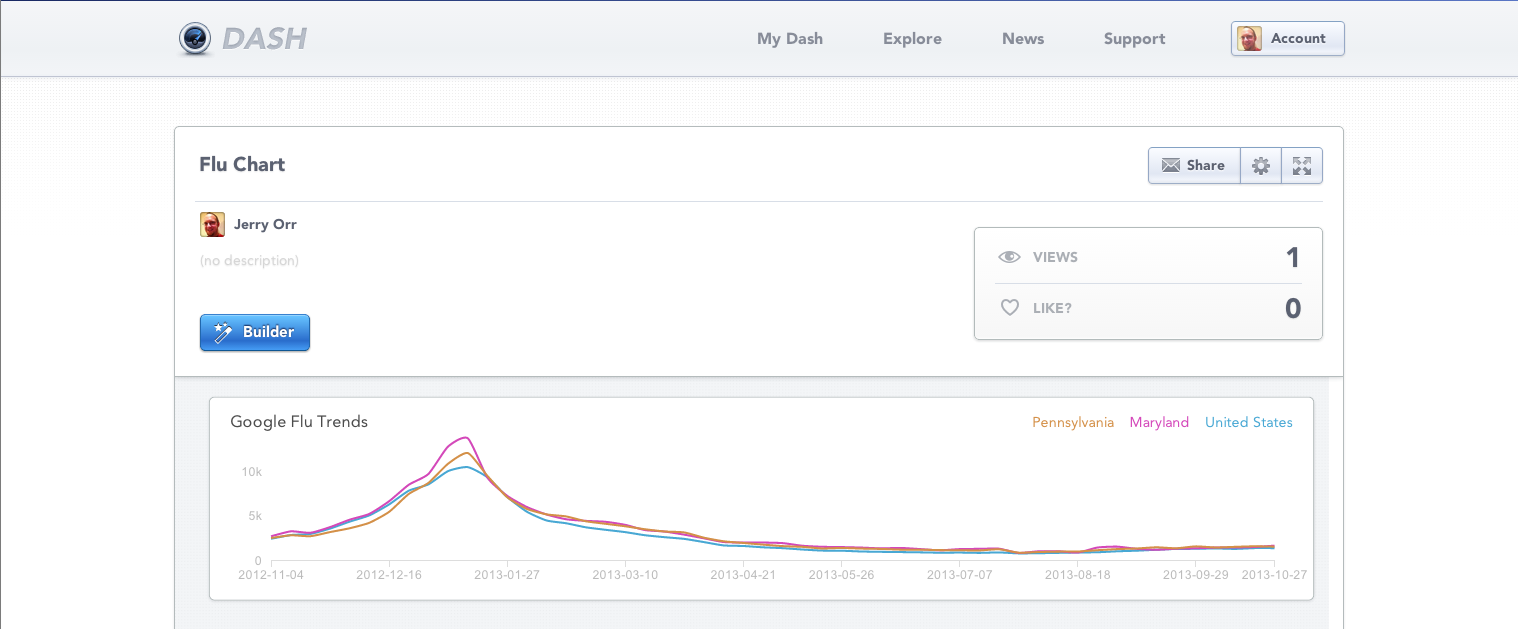
Эй, похоже, декабрь и январь — большие месяцы для гриппа в США. Кто знал?
Хотите попробовать это сами? Полный исходный код этого приложения
находится на GitHub вместе с пошаговыми инструкциями по запуску проекта и созданию виджета в Dash. Наслаждайтесь!