Graphify — это неуправляемое расширение Neo4j, которое обеспечивает классификацию текста по принципу «включай и работай» на естественном языке .
Graphify дает вам механизм для обучения моделям синтаксического анализа естественного языка, которые извлекают особенности текста, используя глубокое обучение . При обучении модели распознавать значение текста вы можете отправить текстовую статью с предоставленным набором меток, которые описывают природу текста. Со временем модель синтаксического анализа естественного языка в Neo4j будет расширяться, чтобы идентифицировать те функции, которые оптимально устраняют неоднозначность текста для набора классов.
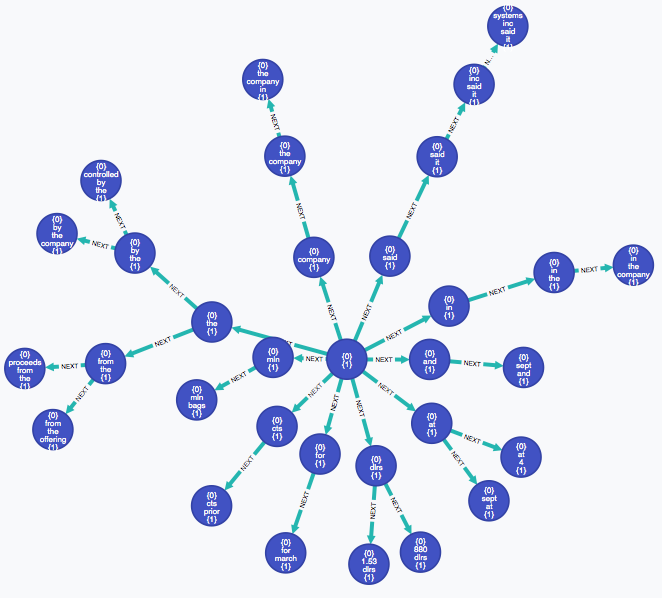
Иерархия функции генерируются вероятностным в результате статистического анализа соседних слов особенности. Благодаря этому становится возможным распознавать большой набор функций в тестовых данных, исключая возможности на каждом уровне.
Представление объекта самого низкого уровня ближе всего к корневому шаблону. В случае Graphify корневым шаблоном является символ пробела. По мере того как обучение увеличивает количество примеров, которые соответствуют символу пробела, более глубокие уровни представлений будут генерироваться путем выбора объектов с наибольшей вероятностью совпадения слева или справа от объекта. Этот вид глубокого обучения не требует нейронной сети из-за характера модели данных графа свойств Neo4j , предоставляя способ генерировать модель векторного пространства для извлеченных объектов и связывать их с векторами объектов посредством косинусного сходства классов, которые отображаются на подмножество узлов объектов в иерархии.
Преимущество использования Neo4j для этого состоит в том, что вы можете прикреплять классы к функциям, которые сопоставляют текст с этими классами, применяемыми в качестве меток во время обучения.
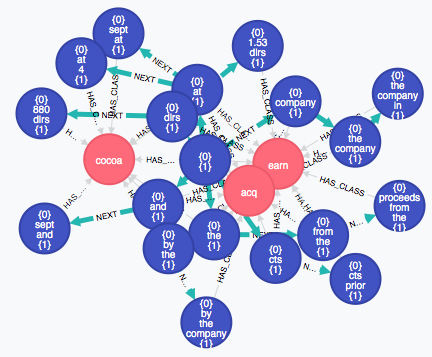
Используя инструмент трехмерной визуализации UbiGraph , визуализация иерархии объектов показывает, как глубинные представления объектов растут со временем.

Модель векторного пространства
Graphify генерирует модель векторного пространства при классификации текста на тренировочных данных. Есть две конечные точки, которые обеспечивают функции классификации и сходства.
Классифицируйте немаркированный текст
Первой конечной точкой является http: // localhost: 7474 / service / graphify / classify, которая поддерживает HTTP-метод POST. После публикации следующей модели JSON свойство text будет автоматически классифицировано по вектору признаков всех ранее обученных классов и отсортировано по косинусному сходству между этими векторами.
{
"text": "Interoperability is the ability of making systems work together."
}
Результатом, который будет возвращен из Neo4j, будет отсортированный список совпадений, упорядоченных по косинусному подобию векторов объектов для каждого класса в базе данных.
{
"classes": [
{
"class": "Interoperability",
"similarity": 0.01478629324290398
},
{
"class": "Natural language",
"similarity": 0.014352533094325508
},
{
"class": "Artificial intelligence",
"similarity": 0.008389954131481638
},
{
"class": "Graph database",
"similarity": 0.006780234851792194
},
{
"class": "Inference engine",
"similarity": 0.005775135975571818
},
{
"class": "Neo4j",
"similarity": 0.005011493979094744
},
{
"class": "Expert system",
"similarity": 0.0045493507614881076
},
{
"class": "Knowledge representation and reasoning",
"similarity": 0.0035488311479422202
},
{
"class": "Speech recognition",
"similarity": 0.0035459146405026746
},
{
"class": "Knowledge acquisition",
"similarity": 0.0033585907499658666
},
{
"class": "Memory",
"similarity": 0.003286652624915932
},
{
"class": "Cognitive robotics",
"similarity": 0.0026605991849062826
},
{
"class": "Hierarchical control system",
"similarity": 0.0024852750266223995
},
{
"class": "NoSQL",
"similarity": 0.002359964627061625
},
{
"class": "Hierarchical database model",
"similarity": 0.0016629332691377717
},
{
"class": "Never-Ending Language Learning",
"similarity": 0.0014433749914281816
},
{
"class": "Multilayer perceptron",
"similarity": 0.0014070718231579983
},
{
"class": "Sentence (linguistics)",
"similarity": 0.0012682029230640021
},
{
"class": "Argument",
"similarity": 0.0012446298877431268
},
{
"class": "Deep learning",
"similarity": 0.0011171501184315629
},
{
"class": "Inductive reasoning",
"similarity": 0.0010671296082781958
},
{
"class": "Machine translation",
"similarity": 0.0010150803638098256
},
{
"class": "Automatic Language Translator",
"similarity": 0.001008811074376599
},
{
"class": "Relational database",
"similarity": 0.0009875922800915275
},
{
"class": "Storage (memory)",
"similarity": 0.000980910572273953
},
{
"class": "Clause",
"similarity": 0.0009355842513276578
},
{
"class": "Dependency grammar",
"similarity": 0.0006764745128168179
},
{
"class": "Autoencoder",
"similarity": 0.0005224831369792641
},
{
"class": "Phrase",
"similarity": 0.00029583989661492754
}
]
}
Получить похожие классы
Чтобы получить большинство связанных классов, которые были предоставлены во время обучения в виде меток, следующая конечная точка: http: // localhost: 7474 / service / graphify / Similar / {class} предоставляет способ получить наиболее похожие классы для указанного имени класса. Опять же, здесь используется модель векторного пространства, созданная из иерархии объектов, добытых в дереве распознавания образов.
Результатом является отсортированный список классов, упорядоченный по косинусному подобию каждого из векторов признаков, связанных с классом.
Например, отправка запроса HTTP GET для следующей конечной точки, http: // localhost: 7474 / service / graphify / Similar / NoSQL, возвращает следующие результаты:
{
"classes": [
{
"class": "Graph database",
"similarity": 0.09574535643836013
},
{
"class": "Relational database",
"similarity": 0.07991318266439677
},
{
"class": "Machine translation",
"similarity": 0.07693041732140395
},
{
"class": "Deep learning",
"similarity": 0.07027180553561777
},
{
"class": "Speech recognition",
"similarity": 0.06491846260229797
},
{
"class": "Knowledge representation and reasoning",
"similarity": 0.061825794099321346
},
{
"class": "Artificial intelligence",
"similarity": 0.059426927894936345
},
{
"class": "Multilayer perceptron",
"similarity": 0.056943365042175544
},
{
"class": "Hierarchical database model",
"similarity": 0.05617955585333319
},
{
"class": "Interoperability",
"similarity": 0.05541367925131132
},
{
"class": "Memory",
"similarity": 0.05514558364443694
},
{
"class": "Expert system",
"similarity": 0.04869202636766413
},
{
"class": "Inductive reasoning",
"similarity": 0.04542968846354395
},
{
"class": "Argument",
"similarity": 0.04473621436021445
},
{
"class": "Clause",
"similarity": 0.03686385050753761
},
{
"class": "Dependency grammar",
"similarity": 0.035584209032388084
},
{
"class": "Sentence (linguistics)",
"similarity": 0.03329025076397098
},
{
"class": "Inference engine",
"similarity": 0.031225512897898145
},
{
"class": "Neo4j",
"similarity": 0.03101280823703653
},
{
"class": "Storage (memory)",
"similarity": 0.02979918393661567
},
{
"class": "Hierarchical control system",
"similarity": 0.028800749676585427
},
{
"class": "Autoencoder",
"similarity": 0.02527201414259688
},
{
"class": "Cognitive robotics",
"similarity": 0.023697018076748396
},
{
"class": "Never-Ending Language Learning",
"similarity": 0.021246276238820964
},
{
"class": "Phrase",
"similarity": 0.019941608021991825
},
{
"class": "Natural language",
"similarity": 0.019809613865907624
},
{
"class": "Automatic Language Translator",
"similarity": 0.017520049172816868
},
{
"class": "Knowledge acquisition",
"similarity": 0.01264614704679436
}
]
}
Повышение квалификации
Конечная точка обучения находится по адресу http: // localhost: 7474 / service / graphify / training. Посылая HTTP-запрос POST к этой конечной точке со следующей моделью:
{
"text": [
"Interoperability is the ability of making systems and organizations work together."
],
"label": [
"Interoperability"
]
}
Особенности изучены через повторение. Чем больше текста содержит похожие фразы (
n-граммы ), тем больше вероятность того, что эти функции будут извлечены и связаны с любыми классами, содержащимися в предыдущих данных обучения.
связи
Если вы хотите стать пионером и протестировать это неуправляемое расширение , перейдите на страницу проекта GitHub и следуйте инструкциям по установке.
https://github.com/kbastani/graphify
Чтобы лучше представить примеры того, как реализовать это расширение для ваших случаев использования, я скоро напишу пример проекта, который создает модель векторного пространства из коллекции документов Википедии.
Если вы хотите помочь, пожалуйста, напишите мне на @kennybastani