Много раз нам приходилось получать данные из базы данных или другого веб-сервиса или загружать их из файловой системы. В случаях, когда это связано с сетевым вызовом, будут присутствовать сетевые задержки, ограничения пропускной способности сети. Один из подходов к решению этой проблемы заключается в том, чтобы иметь кэш, локальный для приложения.
Если ваше приложение охватывает несколько узлов, то кэш будет локальным для каждого узла, вызывая несогласованность данных. Это несоответствие данных может быть заменено для лучшей пропускной способности и меньших задержек. Но иногда, если несогласованность данных имеет существенное значение, тогда можно уменьшить ttl (время жизни) для объекта кэша, тем самым уменьшая продолжительность, в течение которой может возникать несогласованность данных.
Среди множества подходов к реализации локального кэша один из тех, которые я использовал в среде с высокой нагрузкой, — это кеш Guava. Мы использовали кеш guava для обслуживания более 80 000 запросов в секунду. И 90-й процентиль задержек составлял ~ 5 мс. Это помогло нам масштабироваться при ограниченных требованиях к пропускной способности сети.
В этом посте я покажу, как можно добавить слой кэша Guava, чтобы избежать частых сетевых вызовов. Для этого я выбрал очень простой пример получения сведений о книге по номеру ISBN с помощью API Google Книг .
Пример запроса для получения сведений о книге с использованием строки ISBN13: https://www.googleapis.com/books/v1/volumes?q=isbn:9781449370770&key= enjAPI_KEY}
Часть ответа, которая нам полезна, выглядит так:
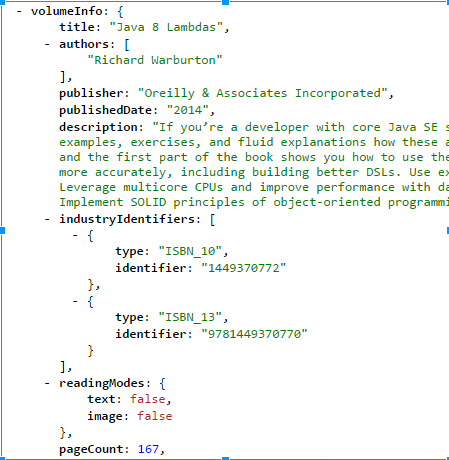
Очень подробное объяснение возможностей Guava Cache можно найти здесь . В этом примере я буду использовать LoadingCache. LoadingCache принимает блок кода, который он использует для загрузки данных в кеш на предмет отсутствия ключа. Поэтому, когда вы выполняете кеширование с несуществующим ключом, LoadingCache извлекает данные с помощью CacheLoader, устанавливает их в кеш и возвращает вызывающей стороне.
Давайте теперь посмотрим на классы моделей, которые нам понадобятся для представления деталей книги:
- Книжный класс
- Авторский класс
Класс Book определяется как:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
|
//Book.javapackage info.sanaulla.model;import java.util.ArrayList;import java.util.Date;import java.util.List;public class Book { private String isbn13; private List<Author> authors; private String publisher; private String title; private String summary; private Integer pageCount; private String publishedDate; public String getIsbn13() { return isbn13; } public void setIsbn13(String isbn13) { this.isbn13 = isbn13; } public List<Author> getAuthors() { return authors; } public void setAuthors(List<Author> authors) { this.authors = authors; } public String getPublisher() { return publisher; } public void setPublisher(String publisher) { this.publisher = publisher; } public String getTitle() { return title; } public void setTitle(String title) { this.title = title; } public String getSummary() { return summary; } public void setSummary(String summary) { this.summary = summary; } public void addAuthor(Author author){ if ( authors == null ){ authors = new ArrayList<Author>(); } authors.add(author); } public Integer getPageCount() { return pageCount; } public void setPageCount(Integer pageCount) { this.pageCount = pageCount; } public String getPublishedDate() { return publishedDate; } public void setPublishedDate(String publishedDate) { this.publishedDate = publishedDate; }} |
И класс Author определяется как:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
//Author.javapackage info.sanaulla.model;public class Author { private String name; public String getName() { return name; } public void setName(String name) { this.name = name; } |
Теперь давайте определим сервис, который будет извлекать данные из API REST Google Книг и будет называть его BookService. Этот сервис делает следующее:
- Получите HTTP-ответ из REST API.
- Использование ObjectMapper Джексона для анализа JSON в карте.
- Получить соответствующую информацию с карты, полученной на шаге-2.
Я извлек несколько операций из BookService в класс Util, а именно:
- Чтение файла application.properties, который содержит ключ API Google Книг (я не поместил этот файл в репозиторий git. Но его можно добавить в папку src / main / resources и назвать этот файл как application.properties и Util API сможет прочитать это для вас)
- Создание HTTP-запроса к REST API и возврат ответа JSON.
Ниже показано, как определяется класс Util:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
//Util.java package info.sanaulla;import com.fasterxml.jackson.databind.ObjectMapper;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStream;import java.io.InputStreamReader;import java.net.HttpURLConnection;import java.net.ProtocolException;import java.net.URL;import java.util.ArrayList;import java.util.List;import java.util.Properties;public class Util { private static ObjectMapper objectMapper = new ObjectMapper(); private static Properties properties = null; public static ObjectMapper getObjectMapper(){ return objectMapper; } public static Properties getProperties() throws IOException { if ( properties != null){ return properties; } properties = new Properties(); InputStream inputStream = Util.class.getClassLoader().getResourceAsStream("application.properties"); properties.load(inputStream); return properties; } public static String getHttpResponse(String urlStr) throws IOException { URL url = new URL(urlStr); HttpURLConnection conn = (HttpURLConnection) url.openConnection(); conn.setRequestMethod("GET"); conn.setRequestProperty("Accept", "application/json"); conn.setConnectTimeout(5000); //conn.setReadTimeout(20000); if (conn.getResponseCode() != 200) { throw new RuntimeException("Failed : HTTP error code : " + conn.getResponseCode()); } BufferedReader br = new BufferedReader(new InputStreamReader( (conn.getInputStream()))); StringBuilder outputBuilder = new StringBuilder(); String output; while ((output = br.readLine()) != null) { outputBuilder.append(output); } conn.disconnect(); return outputBuilder.toString(); }} |
И вот наш класс обслуживания выглядит так:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
//BookService.javapackage info.sanaulla.service;import com.fasterxml.jackson.databind.ObjectMapper;import com.google.common.base.Optional;import com.google.common.base.Strings;import info.sanaulla.Constants;import info.sanaulla.Util;import info.sanaulla.model.Author;import info.sanaulla.model.Book;import java.io.IOException;import java.text.ParseException;import java.text.SimpleDateFormat;import java.util.Arrays;import java.util.List;import java.util.Map;import java.util.Properties;public class BookService { public static Optional<Book> getBookDetailsFromGoogleBooks(String isbn13) throws IOException{ Properties properties = Util.getProperties(); String key = properties.getProperty(Constants.GOOGLE_API_KEY); String response = Util.getHttpResponse(url); Map bookMap = Util.getObjectMapper().readValue(response,Map.class); Object bookDataListObj = bookMap.get("items"); Book book = null; if ( bookDataListObj == null || !(bookDataListObj instanceof List)){ return Optional.fromNullable(book); } List bookDataList = (List)bookDataListObj; if ( bookDataList.size() < 1){ return Optional.fromNullable(null); } Map bookData = (Map) bookDataList.get(0); Map volumeInfo = (Map)bookData.get("volumeInfo"); book = new Book(); book.setTitle(getFromJsonResponse(volumeInfo,"title","")); book.setPublisher(getFromJsonResponse(volumeInfo,"publisher","")); List authorDataList = (List)volumeInfo.get("authors"); for(Object authorDataObj : authorDataList){ Author author = new Author(); author.setName(authorDataObj.toString()); book.addAuthor(author); } book.setIsbn13(isbn13); book.setSummary(getFromJsonResponse(volumeInfo,"description","")); book.setPageCount(Integer.parseInt(getFromJsonResponse(volumeInfo, "pageCount", "0"))); book.setPublishedDate(getFromJsonResponse(volumeInfo,"publishedDate","")); return Optional.fromNullable(book); } private static String getFromJsonResponse(Map jsonData, String key, String defaultValue){ return Optional.fromNullable(jsonData.get(key)).or(defaultValue).toString(); }} |
Добавление кэширования поверх вызова API Google Книг
Мы можем создать объект кэша, используя API CacheBuilder, предоставляемый библиотекой Guava. Он предоставляет методы для установки свойств, таких как
- максимальное количество элементов в кеше,
- время жизни объекта кэша на основе его последнего времени записи или последнего времени доступа,
- TTL для обновления объекта кеша,
- запись статистики в кеш, например, сколько попаданий, промахов, времени загрузки и
- предоставление кода загрузчика для извлечения данных в случае отсутствия или обновления кэша.
Итак, в идеале нам бы хотелось, чтобы при отсутствии кэша использовался наш API, написанный выше, т.е. getBookDetailsFromGoogleBooks. И мы хотели бы хранить максимум 1000 предметов и срок их действия истекает через 24 часа. Итак, фрагмент кода, который создает кеш, выглядит так:
|
01
02
03
04
05
06
07
08
09
10
|
private static LoadingCache<String, Optional<Book>> cache = CacheBuilder.newBuilder() .maximumSize(1000) .expireAfterAccess(24, TimeUnit.HOURS) .recordStats() .build(new CacheLoader<String, Optional<Book>>() { @Override public Optional<Book> load(String s) throws IOException { return getBookDetailsFromGoogleBooks(s); } }); |
Важно отметить, что максимальное количество элементов, которые вы хотите сохранить в кэше, влияет на кучу, используемую вашим приложением. Таким образом, вы должны тщательно определить это значение в зависимости от размера каждого объекта, который вы собираетесь кэшировать, и максимальной кучи памяти, выделенной вашему приложению.
Давайте применим это к действию, а также посмотрим, как статистика кеша сообщает статистику:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
package info.sanaulla;import com.google.common.cache.CacheStats;import info.sanaulla.model.Book;import info.sanaulla.service.BookService;import java.io.IOException;import java.util.Properties;import java.util.concurrent.ExecutionException;public class App { public static void main( String[] args ) throws IOException, ExecutionException { Book book = BookService.getBookDetails("9780596009205").get(); System.out.println(Util.getObjectMapper().writeValueAsString(book)); book = BookService.getBookDetails("9780596009205").get(); book = BookService.getBookDetails("9780596009205").get(); book = BookService.getBookDetails("9780596009205").get(); book = BookService.getBookDetails("9780596009205").get(); CacheStats cacheStats = BookService.getCacheStats(); System.out.println(cacheStats.toString()); }} |
И результат, который мы получили бы:
|
1
2
|
{"isbn13":"9780596009205","authors":[{"name":"Kathy Sierra"},{"name":"Bert Bates"}],"publisher":"\"O'Reilly Media, Inc.\"","title":"Head First Java","summary":"An interactive guide to the fundamentals of the Java programming language utilizes icons, cartoons, and numerous other visual aids to introduce the features and functions of Java and to teach the principles of designing and writing Java programs.","pageCount":688,"publishedDate":"2005-02-09"}CacheStats{hitCount=4, missCount=1, loadSuccessCount=1, loadExceptionCount=0, totalLoadTime=3744128770, evictionCount=0} |
Это очень простое использование кэша Guava, и я написал его, когда учился его использовать. В этом я использовал другие API-интерфейсы Guava, такие как Optional, который помогает обернуть существующие или несуществующие (нулевые) значения в объекты. Этот код доступен на git hub — https://github.com/sanaulla123/Guava-Cache-Demo . Будут проблемы, такие как то, как он обрабатывает параллелизм, в которые я не вдавался подробно. Но под капотом он использует сегментированную карту хэша Concurrent, так что запросы всегда неблокируются, но количество одновременных записей будет зависеть от количества сегментов.
Некоторые полезные ссылки, связанные с этим: http://guava-libraries.googlecode.com/files/ConcurrentCachingAtGoogle.pdf
| Ссылка: | Использование Google Guava Cache для локального кэширования от нашего партнера JCG Мохамеда Санауллы в блоге Experiences Unlimited . |