В этой статье я собираюсь использовать сервис AWS MapReduce (называемый ElasticMapReduce ), используя CLI для EMR.
Процесс использования EMR можно разделить на три этапа на высоком уровне:
- установить и заполнить ведра S3
- создать и запустить работу EMR
- получить результаты из ведра S3
Прежде чем вы сможете начать с этих трех шагов высокого уровня, необходимо выполнить некоторые другие действия:
- вам нужно будет иметь учетную запись AWS
- вам нужно будет установить клиент S3 на свой компьютер
- вам нужно будет установить EMR CLI на вашем компьютере
Что ж, для аккаунта AWS я просто предполагаю, что он есть, иначе самое время найти себе
В качестве клиента S3 я использую s3cmd, установку которого я описал здесь .
Чтобы установить EMR CLI (на моем MacBook с Lion в моем случае), я следовал инструкциям, описанным здесь . Как сказано в инструкции, CLI работает с версией Ruby 1.8.7. и не более поздние версии. Поскольку мой MacOS поставляется с Ruby 1.9.3 по умолчанию, он действительно не работает. Но не паникуйте, просто получите последнюю версию CLI здесь от GitHub (я предпочитаю это вместо понижения стандартной установки Ruby).
Когда EMR установлен, его необходимо настроить. Первым шагом является создание файла ‘credentials.json’ в корневом каталоге каталога EMR CLI. Содержание моего credentials.json:
|
1
2
3
4
5
6
7
8
|
{"access_id": "XXXXXXXXXXXXXXX","private_key": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX","keypair": "4synergy_palma","key-pair-file": "/Users/pascal/4synergy_palma.pem","log_uri": "S3://map-reduce-intro/log","region": "eu-west-1"} |
Когда CLI установлены, мы можем начать с реальной работы. Я просто придерживаюсь примера в Руководстве для разработчиков EMR .
1. Установить и заполнить ведра S3
Откройте окно терминала.
Создайте S3 bucket из командной строки:
|
1
|
s3cmd mb s3://map-reduce-intro |
Создайте входной файл для использования с тестовым заданием в качестве входного:
|
1
|
nano input.txt |
И поместите в него текст:
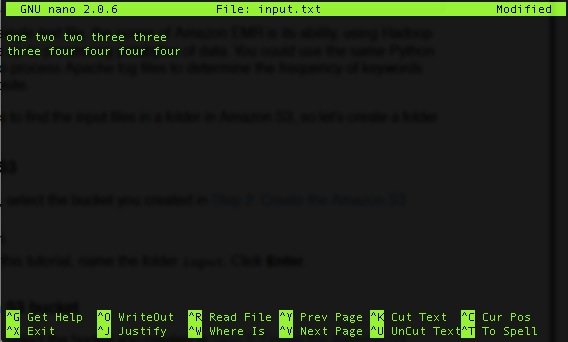
Затем загрузите этот файл в корзину в новую папку в корзине:
|
1
|
s3cmd put input.txt s3://map-reduce-intro/input/ |
Затем создайте функцию отображения (скрипт Python) и загрузите ее в корзину S3:
|
1
|
nano wordsplitter.py |
и поместите в него пример сценария из руководства разработчика:
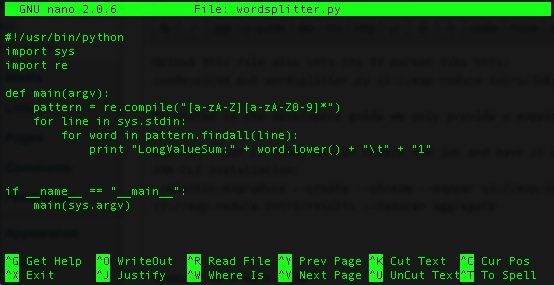
Загрузите этот файл также в корзину S3 следующим образом:
|
1
|
s3cmd put wordsplitter.py s3://map-reduce-intro/job/ |
Как указано в руководстве для разработчиков, мы предоставляем только сценарий отображения, так как мы используем стандартную функцию сокращения Hadoop, «агрегат».
Теперь ввод готов, мы можем создать задание и выполнить его.
2. Создайте и запустите задание EMR
Мы делаем это, выполняя следующую команду из корня установки EMR CLI:
|
1
|
./elastic-mapreduce --create --stream --mapper s3://map-reduce-intro/job/wordsplitter.py --input s3://map-reduce-intro/input --output s3://map-reduce-intro/results --reducer aggregate |
Выход в терминале будет просто идентификатором задания, например:
|
1
|
Created job flow j-2MO24NGGNMC5N |
Получить результаты от S3 ковша
Если мы перейдем к корзине S3 и выведем список «результатов», то увидим следующее (обратите внимание, что может пройти несколько минут, прежде чем кластер будет запущен, выполнен и завершен):
|
1
2
3
4
|
MacBook-Air-van-Pascal:~ pascal$ s3cmd ls s3://map-reduce-intro/results/2013-05-06 20:03 0 s3://map-reduce-intro/results/_SUCCESS2013-05-06 20:03 27 s3://map-reduce-intro/results/part-00000MacBook-Air-van-Pascal:~ pascal$ |
Файл _SUCCESS просто говорит нам, что работа прошла нормально. Файл ‘part-00000’ содержит выходные данные нашего «агрегатного» действия, которое мы выполнили. Чтобы получить это сделать:
|
1
|
s3cmd get s3://map-reduce-intro/results/part-00000 |
Теперь, если мы посмотрим на ожидаемое содержимое:
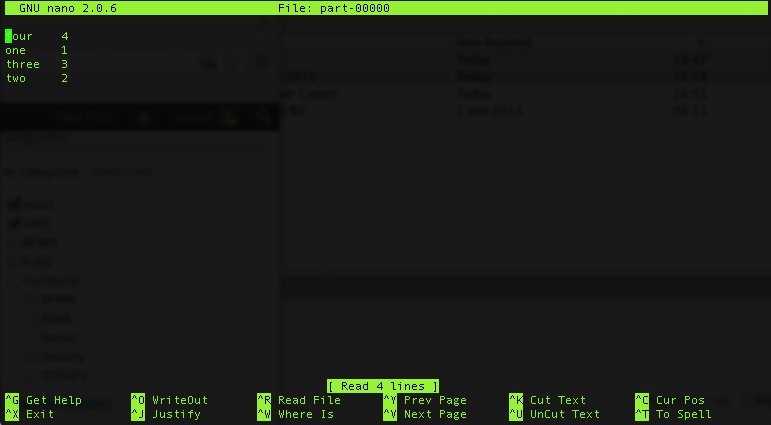
Я знаю, что это очень простой пример, и о EMR можно показать гораздо больше, но, по крайней мере, это должно дать вам возможность поиграть с ним самостоятельно.
Следует иметь в виду, что плата взимается за час, и если вы используете кластер всего несколько секунд, с вас будет взиматься плата за полный час. Час стоит около 0,015 цента сверх затрат EC2 кластера.