Автор Джош Лонг в весеннем блоге
Приложения генерируют все больше и больше данных, чем когда-либо прежде, и огромная часть задачи — прежде чем ее можно будет даже проанализировать — прежде всего справляется с нагрузкой. Apache’s Kafka отвечает на этот вызов. Первоначально он был разработан LinkedIn и впоследствии был открыт в 2011 году. Проект направлен на создание унифицированной высокопроизводительной платформы с низкой задержкой для обработки потоков данных в реальном времени. На дизайн сильно влияют журналы транзакций. Это система обмена сообщениями, похожая на традиционные системы обмена сообщениями, такие как RabbitMQ, ActiveMQ, MQSeries, но она идеально подходит для агрегации журналов, постоянного обмена сообщениями, быстрого (_ сотни сотен мегабайт в секунду!) Чтения и записи и может вместить множество клиентов. Естественно, это делает его идеальным для облачных архитектур!
Кафка работает на многих крупных производственных системах, LinkedIn использует его для данных об активности и рабочих метрик для обеспечения новостной ленты LinkedIn и LinkedIn Today, а также для офлайн-аналитики в Hadoop. Twitter использует его как часть своей инфраструктуры потоковой обработки. Kafka поддерживает обмен сообщениями между онлайн и офлайн в Foursquare. Он используется для интеграции систем мониторинга и производства Foursquare с автономными инфраструктурами на основе Hadoop. Square использует Kafka в качестве шины для перемещения всех системных событий через различные дата-центры Square. Это включает в себя метрики, журналы, пользовательские события и так далее. На стороне потребителя он выводит в режиме реального времени Splunk, Graphite или Esper-подобные предупреждения. Netflix использует его для 300-600BN сообщений в день. Он также используется Airbnb, Mozilla, Goldman Sachs, Tumblr, Yahoo, PayPal, Coursera, Urban Airship, Hotels.com,и, казалось бы, бесконечный список других звезд большой сети. Понятно, что он зарабатывает на некоторых мощных системах!
Установка Apache Kafka
Существует множество способов установить Apache Kafka. Если вы используете OSX и используете Homebrew, это может быть просто brew install kafka. Вы также можете скачать последнюю версию дистрибутива от Apache . Я скачал kafka_2.10-0.8.2.1.tgz, разархивировал его, а затем внутри вы обнаружите дистрибутив Apache Zookeeper и Kafka, так что больше ничего не требуется. Я установил Apache Kafka в своем $HOME каталоге, в другом каталоге bin, затем создал переменную окружения KAFKA_HOME, которая указывает на $HOME/bin/kafka.
Сначала запустите Apache Zookeeper, указав, где требуется файл свойств конфигурации:
$KAFKA_HOME/bin/zookeeper-server-start.sh $KAFKA_HOME/config/zookeeper.properties
Дистрибутив Apache Kafka поставляется с файлами конфигурации по умолчанию для Zookeeper и Kafka, что облегчает начало работы. В более сложных случаях вам необходимо настроить эти файлы.
Затем запустите Apache Kafka. Для этого также требуется файл конфигурации, например:
$KAFKA_HOME/bin/kafka-server-start.sh $KAFKA_HOME/config/server.properties
Этот server.properties файл содержит, помимо прочего, значения по умолчанию для того, где подключаться к Apache Zookeeper ( zookeeper.connect), сколько данных следует отправлять через сокеты, сколько разделов существует по умолчанию и идентификатор брокера ( broker.id — который должен быть уникальным в кластере). ).
В том же каталоге есть и другие скрипты, которые можно использовать для отправки и получения фиктивных данных, что очень удобно для определения того, что все работает!
Теперь, когда Apache Kafka запущен и работает, давайте посмотрим на работу с Apache Kafka из нашего приложения.
Некоторые концепции высокого уровня ..
Брокерный кластер Kafka состоит из одного или нескольких серверов, на каждом из которых может быть запущен один или несколько брокерских процессов. Apache Kafka предназначен для высокой доступности; нет мастер- узлов. Все узлы являются взаимозаменяемыми. Данные реплицируются с одного узла на другой, чтобы обеспечить их доступность в случае сбоя.
В Kafka тема — это категория, похожая на JMS-адресат или обмен и очередь AMQP. Разделы разделены на разделы, и выбор раздела раздела, в который следует отправлять сообщение, производит производитель сообщений. Каждому сообщению в разделе присваивается уникальный последовательный идентификатор, его смещение . Чем больше разделов, тем больше параллелизм для потребления, но это также приведет к увеличению количества файлов между брокерами.
Производители отправляют сообщения темам брокера Apache Kafka и указывают раздел, который будет использоваться для каждого создаваемого сообщения. Производство сообщений может быть синхронным или асинхронным. Производители также указывают, какой тип гарантии репликации они хотят.
Потребители прослушивают сообщения по темам и обрабатывают поток опубликованных сообщений. Как и следовало ожидать, если вы использовали другие системы обмена сообщениями, это обычно (и полезно!) Асинхронный.
Как и Spring XD и многие другие распределенные системы, Apache Kafka использует Apache Zookeeper для координации информации о кластере. Apache Zookeeper предоставляет общее иерархическое пространство имен (называемое znodes ), которое узлы могут совместно использовать, чтобы понять топологию и доступность кластера (еще одна причина, по которой Spring Cloud будет поддерживать его в будущем).
Zookeeper очень присутствует в ваших взаимодействиях с Apache Kafka. Apache Kafka имеет, например, два разных API для работы в качестве потребителя. API более высокого уровня проще начать, и он обрабатывает все нюансы обработки разделов и так далее. Для сохранения состояния координации потребуется ссылка на экземпляр Zookeeper.
Давайте теперь обратимся к использованию Apache Kafka с Spring.
Использование Apache Kafka с Spring Integration
Недавно выпущенный адаптер Apache Kafka 1.1 Spring Integration является очень мощным и предоставляет входящие адаптеры для работы как с API-интерфейсом Apache Kafka более низкого уровня, так и с API более высокого уровня.
Адаптер, в настоящее время, сначала является XML-конфигурацией, хотя работа над DSL конфигурации Spring Integration Java для адаптера уже ведется, и доступны этапы. Мы посмотрим на оба здесь, сейчас.
Чтобы все эти примеры работали, я добавил репозиторий libs-milestone-local Maven и использовал следующие зависимости:
- org.apache.kafka: kafka_2.10: 0.8.1.1
- org.springframework.boot: весна-загрузка-стартер-интеграция: 1.2.3.RELEASE
- org.springframework.boot: весна-загрузка стартер: 1.2.3.RELEASE
- org.springframework.integration: весна-интегрально-Кафка: 1.1.1.RELEASE
- org.springframework.integration: весна-интеграция-ява-DSL: 1.1.0.M1
Использование Spring Integration Apache Kafka с XML DSL Spring Integration
Сначала давайте рассмотрим, как использовать исходящий адаптер Spring Integration для отправки Message<T>экземпляров из потока Spring Integration во внешний экземпляр Apache Kafka. Пример довольно прост: Spring Integration с channel именем inputToKafka действует как канал, который пересылает Message<T> сообщения в исходящий адаптер kafkaOutboundChannelAdapter. Сам адаптер может использовать свою конфигурацию из значений по умолчанию, указанных в kafka:producer-context элементе, или из локальных настроек конфигурации адаптера. В данном kafka:producer-context элементе может быть одна или несколько конфигураций .
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:int="http://www.springframework.org/schema/integration"
xmlns:int-kafka="http://www.springframework.org/schema/integration/kafka"
xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="http://www.springframework.org/schema/integration/kafka http://www.springframework.org/schema/integration/kafka/spring-integration-kafka.xsd
http://www.springframework.org/schema/integration http://www.springframework.org/schema/integration/spring-integration.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task.xsd">
<int:channel id="inputToKafka">
<int:queue/>
</int:channel>
<int-kafka:outbound-channel-adapter
id="kafkaOutboundChannelAdapter"
kafka-producer-context-ref="kafkaProducerContext"
channel="inputToKafka">
<int:poller fixed-delay="1000" time-unit="MILLISECONDS" receive-timeout="0" task-executor="taskExecutor"/>
</int-kafka:outbound-channel-adapter>
<task:executor id="taskExecutor" pool-size="5" keep-alive="120" queue-capacity="500"/>
<int-kafka:producer-context id="kafkaProducerContext">
<int-kafka:producer-configurations>
<int-kafka:producer-configuration broker-list="localhost:9092"
topic="event-stream"
compression-codec="default"/>
</int-kafka:producer-configurations>
</int-kafka:producer-context>
</beans>
Вот код Java из приложения Spring Boot для запуска отправки сообщений с использованием исходящего адаптера путем отправки сообщений во входящие inputToKafka MessageChannel.
package xml;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.DependsOn;
import org.springframework.context.annotation.ImportResource;
import org.springframework.integration.config.EnableIntegration;
import org.springframework.messaging.MessageChannel;
import org.springframework.messaging.support.GenericMessage;
@SpringBootApplication
@EnableIntegration
@ImportResource("/xml/outbound-kafka-integration.xml")
public class DemoApplication {
private Log log = LogFactory.getLog(getClass());
@Bean
@DependsOn("kafkaOutboundChannelAdapter")
CommandLineRunner kickOff(@Qualifier("inputToKafka") MessageChannel in) {
return args -> {
for (int i = 0; i < 1000; i++) {
in.send(new GenericMessage<>("#" + i));
log.info("sending message #" + i);
}
};
}
public static void main(String args[]) {
SpringApplication.run(DemoApplication.class, args);
}
}
Использование новой конфигурации Apache Kafka Spring для интеграции Java DSL
Вскоре после выпуска Spring Integration 1.1 рок-звезда Spring Integration Артем Билан приступил к работе над добавлением аналога DSL-конфигурации Spring Integration Java Configuration, и результат — вещь прекрасная! Это еще не GA (вам нужно добавить libs-milestone репозиторий на данный момент), но я призываю вас попробовать его и пнуть шины. Это хорошо работает для меня, и команда Spring Integration всегда заинтересована в получении ранней обратной связи, когда это возможно! Вот пример, который демонстрирует как отправку сообщений, так и потребление их от двух разных IntegrationFlows. Производитель похож на пример XML выше.
Новым в этом примере является потребитель опроса. Он ориентирован на пакетную обработку и удаляет все сообщения, которые он видит, с фиксированным интервалом. В нашем коде полученное сообщение будет картой, которая содержит в качестве своих ключей тему, а в качестве значения — другую карту с идентификатором раздела и пакетом (в данном случае из 10 записей) прочитанных записей. Существует MessageListenerContainerальтернатива на основе, которая обрабатывает сообщения по мере их поступления.
package jc;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.DependsOn;
import org.springframework.integration.IntegrationMessageHeaderAccessor;
import org.springframework.integration.config.EnableIntegration;
import org.springframework.integration.dsl.IntegrationFlow;
import org.springframework.integration.dsl.IntegrationFlows;
import org.springframework.integration.dsl.SourcePollingChannelAdapterSpec;
import org.springframework.integration.dsl.kafka.Kafka;
import org.springframework.integration.dsl.kafka.KafkaHighLevelConsumerMessageSourceSpec;
import org.springframework.integration.dsl.kafka.KafkaProducerMessageHandlerSpec;
import org.springframework.integration.dsl.support.Consumer;
import org.springframework.integration.kafka.support.ZookeeperConnect;
import org.springframework.messaging.MessageChannel;
import org.springframework.messaging.support.GenericMessage;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.Map;
/**
* Demonstrates using the Spring Integration Apache Kafka Java Configuration DSL.
* Thanks to Spring Integration ninja <a href="http://spring.io/team/artembilan">Artem Bilan</a>
* for getting the Java Configuration DSL working so quickly!
*
* @author Josh Long
*/
@EnableIntegration
@SpringBootApplication
public class DemoApplication {
public static final String TEST_TOPIC_ID = "event-stream";
@Component
public static class KafkaConfig {
@Value("${kafka.topic:" + TEST_TOPIC_ID + "}")
private String topic;
@Value("${kafka.address:localhost:9092}")
private String brokerAddress;
@Value("${zookeeper.address:localhost:2181}")
private String zookeeperAddress;
KafkaConfig() {
}
public KafkaConfig(String t, String b, String zk) {
this.topic = t;
this.brokerAddress = b;
this.zookeeperAddress = zk;
}
public String getTopic() {
return topic;
}
public String getBrokerAddress() {
return brokerAddress;
}
public String getZookeeperAddress() {
return zookeeperAddress;
}
}
@Configuration
public static class ProducerConfiguration {
@Autowired
private KafkaConfig kafkaConfig;
private static final String OUTBOUND_ID = "outbound";
private Log log = LogFactory.getLog(getClass());
@Bean
@DependsOn(OUTBOUND_ID)
CommandLineRunner kickOff(
@Qualifier(OUTBOUND_ID + ".input") MessageChannel in) {
return args -> {
for (int i = 0; i < 1000; i++) {
in.send(new GenericMessage<>("#" + i));
log.info("sending message #" + i);
}
};
}
@Bean(name = OUTBOUND_ID)
IntegrationFlow producer() {
log.info("starting producer flow..");
return flowDefinition -> {
Consumer<KafkaProducerMessageHandlerSpec.ProducerMetadataSpec> spec =
(KafkaProducerMessageHandlerSpec.ProducerMetadataSpec metadata)->
metadata.async(true)
.batchNumMessages(10)
.valueClassType(String.class)
.<String>valueEncoder(String::getBytes);
KafkaProducerMessageHandlerSpec messageHandlerSpec =
Kafka.outboundChannelAdapter(
props -> props.put("queue.buffering.max.ms", "15000"))
.messageKey(m -> m.getHeaders().get(IntegrationMessageHeaderAccessor.SEQUENCE_NUMBER))
.addProducer(this.kafkaConfig.getTopic(),
this.kafkaConfig.getBrokerAddress(), spec);
flowDefinition
.handle(messageHandlerSpec);
};
}
}
@Configuration
public static class ConsumerConfiguration {
@Autowired
private KafkaConfig kafkaConfig;
private Log log = LogFactory.getLog(getClass());
@Bean
IntegrationFlow consumer() {
log.info("starting consumer..");
KafkaHighLevelConsumerMessageSourceSpec messageSourceSpec = Kafka.inboundChannelAdapter(
new ZookeeperConnect(this.kafkaConfig.getZookeeperAddress()))
.consumerProperties(props ->
props.put("auto.offset.reset", "smallest")
.put("auto.commit.interval.ms", "100"))
.addConsumer("myGroup", metadata -> metadata.consumerTimeout(100)
.topicStreamMap(m -> m.put(this.kafkaConfig.getTopic(), 1))
.maxMessages(10)
.valueDecoder(String::new));
Consumer<SourcePollingChannelAdapterSpec> endpointConfigurer = e -> e.poller(p -> p.fixedDelay(100));
return IntegrationFlows
.from(messageSourceSpec, endpointConfigurer)
.<Map<String, List<String>>>handle((payload, headers) -> {
payload.entrySet().forEach(e -> log.info(e.getKey() + '=' + e.getValue()));
return null;
})
.get();
}
}
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
Пример интенсивно использует лямбды Java 8.
Производитель тратит немного времени, определяя, сколько сообщений будет отправлено за одну операцию отправки, как кодируются ключи и значения (в byte[] конце концов, Кафка знает только о массивах) и следует ли отправлять сообщения синхронно или асинхронно. В следующей строке мы настраиваем сам исходящий адаптер, а затем определяем так IntegrationFlow , чтобы все сообщения отправлялись через исходящий адаптер Kafka.
Потребитель тратит немного времени на определение экземпляра Zookeeper, к которому нужно подключиться, сколько сообщений получать (10) в пакете и т. Д. После получения пакетов сообщений они передаются handle методу, который я передал в лямбда, которая будет перечислять тело полезной нагрузки и распечатывать его. Ничего фантастического.
Использование Apache Kafka с Spring XD
Apache Kafka — это шина сообщений, и она может быть очень мощной при использовании в качестве шины интеграции. Тем не менее, он действительно работает сам по себе, потому что он достаточно быстрый и достаточно масштабируемый, чтобы его можно было использовать для маршрутизации больших данных через конвейеры обработки. И если вы занимаетесь обработкой данных, вам действительно нужен Spring XD ! Spring XD упрощает использование Apache Kafka (поскольку поддержка построена на адаптере Apache Kafka Spring Integration!) В сложных конвейерах потоковой обработки. Apache Кафка подвергается как Spring XD источник — где данные поступают от — и раковина — где данные идут.
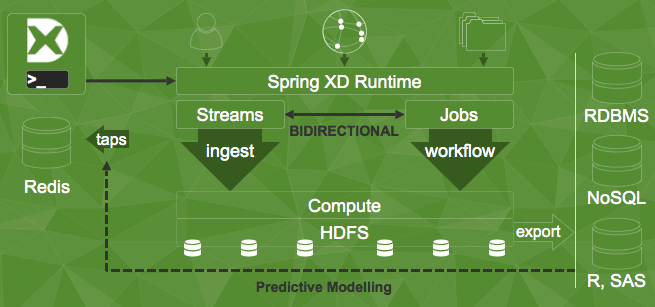
Spring XD предоставляет супер удобный DSL для создания bashпотоков, подобных каналам и фильтрам. Spring XD — это централизованная среда выполнения, которая управляет, масштабирует и контролирует задания по обработке данных. Он построен на основе Spring Integration, Spring Batch, Spring Data и Spring для Hadoop, чтобы быть универсальным центром обработки данных. Spring XD Jobs считывает данные из источников , обрабатывает их через компоненты обработки, которые могут считать, фильтровать, обогащать или преобразовывать данные, а затем записывать их в приемники.
Ниндзя Spring Integration и Spring XD Мариус Богоевич , который проделал большую часть недавней работы по реализации Apache Kafka в Spring Integration и Spring XD, собрал действительно хороший пример, демонстрирующий, как заставить работать полноценный поток Spring XD и Kafka . Здесь README вы найдете информацию о настройке Apache Kafka, Spring XD и необходимых тем. Суть, однако, заключается в том, что вы используете оболочку Spring XD и оболочку DSL для создания потока. Компоненты Spring XD являются именованными компонентами, которые предварительно настроены, но имеют множество параметров, которые можно переопределить с --.. помощью аргументов через оболочку XD и DSL. (Кстати, этот DSL написан замечательным Энди Клементом славы языка Spring Expression!) Вот пример, который конфигурирует поток для чтения данных из источника Apache Kafka, а затем пишет сообщение компоненту log, который называется приемником. logВ этом случае могут быть syslogd, Splunk, HDFS и т. д.
xd> stream create kafka-source-test --definition "kafka --zkconnect=localhost:2181 --topic=event-stream | log"--deploy
Вот и все! Естественно, это всего лишь игра Spring XD, но, надеюсь, вы согласитесь, что возможности дразнят.
Развертывание сервера Kafka с решеткой и Docker
Легко получить пример установки Kafka со всеми настройками с использованием Lattice , распределенной среды выполнения, которая поддерживает, среди других форматов контейнеров, очень популярный формат изображений Docker. Spotify предоставляет изображение Docker, которое устанавливает совместно расположенное изображение Zookeeper и Kafka . Вы можете легко развернуть это в кластере решетки следующим образом:
ltc create --run-as-root m-kafka spotify/kafkaОттуда вы можете легко масштабировать экземпляры Apache Kafka и еще проще использовать Apache Kafka из ваших облачных сервисов.
Следующие шаги
Вы можете найти код для этого блога в моей учетной записи GitHub .
Мы только поцарапали поверхность!
Если вы хотите узнать больше (а почему бы и нет?), То обязательно посетите предстоящий вебинар Мариуса Богоевича и доктора Марка Поллака по Reactive data-pipelines с использованием Spring XD и Apache Kafka, где они продемонстрируют, насколько это легко. можно использовать RxJava, Spring XD и Apache Kafka!