В блоге Apache PDFBox 2 я продемонстрировал использование Apache PDFBox 2 в качестве библиотеки, вызываемой из Java-кода для манипулирования PDF-файлами. Оказывается, что Apache PDFBox 2 также предоставляет инструменты командной строки, которые можно использовать непосредственно из командной строки, как есть, без необходимости дополнительного кодирования Java. Доступно несколько инструментов командной строки, и я продемонстрирую некоторые из них в этом посте.
Инструменты командной строки PDFBox выполняются с использованием исполняемого файла JAR java -jar ( java -jar с Main-Class: org.apache.pdfbox.tools.PDFBox ). Это JAR с именем «app» в названии и для этого конкретного сообщения в блоге pdfbox-app-2.0.2.jar . Общий формат, используемый для вызова этих инструментов в java -jar pdfbox-app-2.0.2.jar <Command> [options] [files] .
Когда исполняемый JAR-файл выполняется без аргументов, предоставляется форма справки, в которой перечислены доступные команды. Это показано на следующем снимке экрана.
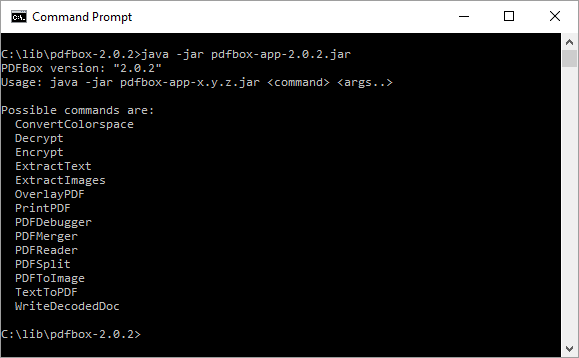
Этот снимок экрана показывает, что эта версия Apache PDFBox (2.0.2) объявляет о поддержке «Возможных команд» ConvertColorspace, Decrypt , Encrypt , ExtractText , ExtractImages , OverlayPDF , PrintPDF , PDFDebugger , PDFMerger , PDFReader, PDFSplit , PDFToImage , TextToPDF , и WriteDecodedDoc .
Извлечение текста: «ExtractText»
Первый инструмент командной строки, на который я смотрю, — это извлечение текста из PDF. Я продемонстрировал использование PDFBox для этого из кода Java в моем предыдущем сообщении в блоге . Здесь я буду использовать PDFBox, чтобы делать то же самое прямо из командной строки, без исходного кода Java. Следующая операция извлекает текст из PDF Scala по Примеру . В моем предыдущем посте код Java получил доступ к этому PDF-документу онлайн и использовал PDFBox для извлечения текста из него. В этом случае я скачал Scala by Example и запускаю инструмент командной строки PDFBox ExtractText для этого загруженного PDF-файла, хранящегося на моем жестком диске в C:\pdf\ScalaByExample.pdf .
Команда для извлечения текста из PDF из командной строки с использованием PDFBox: java -jar pdfbox-app-2.0.2.jar ExtractText C:\pdf\ScalaByExample.pdf . Следующие два снимка экрана демонстрируют выполнение этой команды и файла, который она генерирует. Из этих снимков экрана видно, что текстовый файл, созданный этой командой по умолчанию, имеет то же имя, что и исходный PDF, но с расширением .txt . Эта команда поддерживает несколько опций, включая возможность указать имя текстового файла, поместив это имя после имени файла исходного PDF-файла и возможность записать текст в консоль, а не в файл с помощью флага -console (из которого вывод может быть перенаправлен). Примеры того, как указать произвольное имя текстового файла и как направить текст на консоль вместо файла, показаны далее.
- Явное указание имени текстового файла:
-
java -jar pdfbox-app-2.0.2.jar ExtractText C:\pdf\ScalaByExample.pdf C:\pdf\dustin.txt
-
- Рендеринг текста на консоли
-
java -jar pdfbox-app-2.0.2.jar ExtractText -console C:\pdf\ScalaByExample.pdf
-
PDF из текста: «TextToPDF»
Когда желательно пойти другим путем (начать с текста в качестве источника и сгенерировать PDF), подходит команда TextToPDF . Чтобы продемонстрировать это, я использую исходный текстовый файл с именем doi.txt который содержит часть Декларации независимости США :
|
1
2
3
4
5
|
The unanimous Declaration of the thirteen united States of America,When in the Course of human events, it becomes necessary for one people to dissolve the political bands which have connected them with another, and to assume among the powers of the earth, the separate and equal station to which the Laws of Nature and of Nature's God entitle them, a decent respect to the opinions of mankind requires that they should declare the causes which impel them to the separation.We hold these truths to be self-evident, that all men are created equal, that they are endowed by their Creator with certain unalienable Rights, that among these are Life, Liberty and the pursuit of Happiness |
С образцом текстового файла на C:\pdf\doi.txt , PDFBox TextToPDF может быть запущен против него. Команда java -jar pdfbox-app-2.0.2.jar TextToPDF C:\pdf\doi.pdf C:\pdf\doi.txt (обратите внимание, что целевой PDF указан в качестве первого аргумента, а исходный текстовый файл в указан в качестве второго аргумента). Следующие три снимка экрана демонстрируют выполнение этой команды успешной генерации PDF из исходного текстового файла.


Извлечение изображений из PDF-файлов: «ExtractImages»
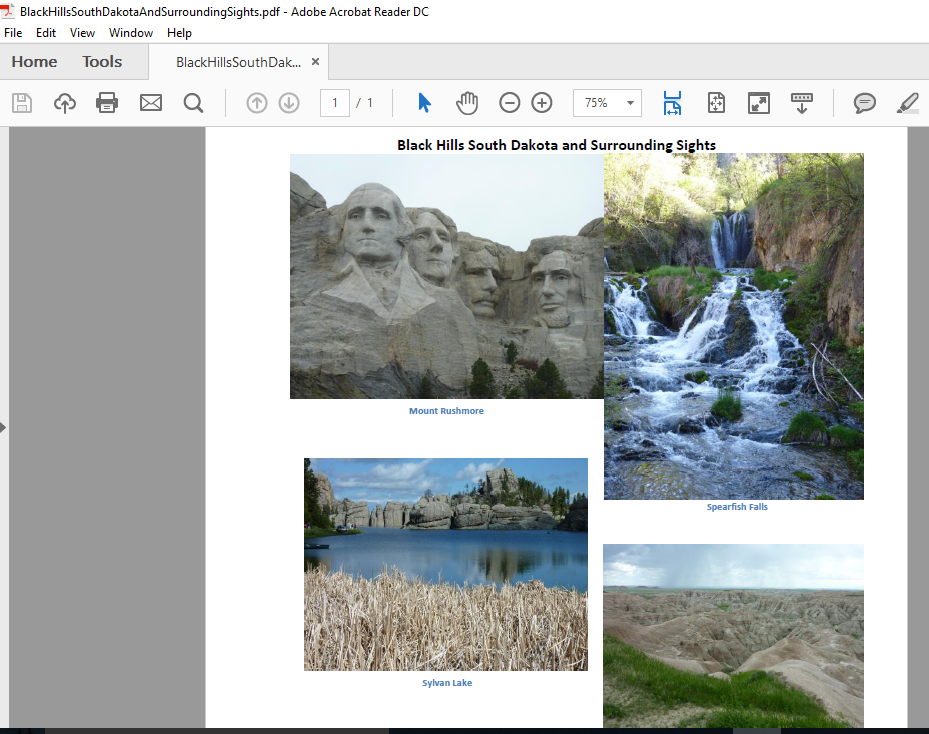
Инструмент командной строки PDFBox ExtractImages позволяет извлекать изображения из PDF так же просто, как и инструмент командной строки «ExtractText» для извлечения текста из PDF. Моя демонстрация этой возможности извлечет четыре изображения из PDF-файла, созданного мной с изображениями из Блэк-Хилс (и окрестности) в Южной Дакоте, который называется BlackHillsSouthDakotaAndSurroundingSights.pdf . Снимок экрана этого PDF показан ниже.
PDFBox можно использовать для извлечения четырех фотографий из этого PDF-файла с помощью команды java -jar pdfbox-app-2.0.2.jar ExtractImages C:\pdf\BlackHillsSouthDakotaAndSurroundingSights.pdf как показано на следующем снимке экрана.
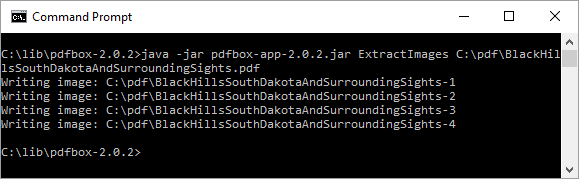
Выполнение этой команды, как показано на последнем снимке экрана, извлекает четыре изображения из PDF. Каждое извлеченное изображение названо в честь исходного PDF с дефисом и целым числом, добавленным в конце имени. Сгенерированные изображения также являются файлами JPEG с расширениями .jpg . В этом случае имена сгенерированных файлов, таким образом, представляют собой BlackHillsSouthDakotaAndSurroundingSights-1.jpg, BlackHillsSouthDakotaAndSurroundingSights-2.jpg, BlackHillsSouthDakotaAndSurroundingSights-3.jpg, и BlackHillsSouthDakotaAndSurroundingSights извлекается из каждого из следующих PDF-файлов.
| BlackHillsSouthDakotaAndSurroundingSights-1.jpg | BlackHillsSouthDakotaAndSurroundingSights-2.jpg |
|---|---|
 |
 |
| BlackHillsSouthDakotaAndSurroundingSights-3.jpg | BlackHillsSouthDakotaAndSurroundingSights-4.jpg |
 |
 |
Шифрование PDF: «Шифрование»
Apache PDFBox позволяет легко зашифровать PDF. Например, я могу зашифровать PDF-файл, использованный в примере «ExtractImages», с помощью следующей команды: java -jar pdfbox-app-2.0.2.jar Encrypt -O DustinWasHere -U DustinWasHere C:\pdf\BlackHillsSouthDakotaAndSurroundingSights.pdf как показано в следующий снимок экрана:

После запуска команды шифрования мне нужен пароль, чтобы открыть этот PDF-файл в Adobe Reader:
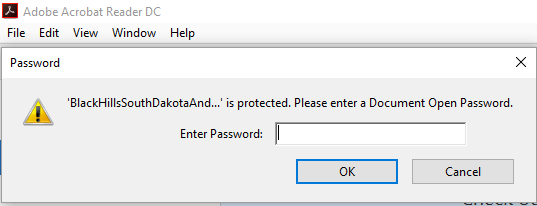
Расшифровка PDF: «Расшифровать»
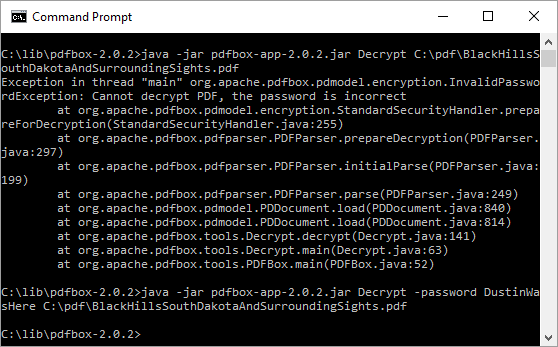
java -jar pdfbox-app-2.0.2.jar Decrypt -password DustinWasHere C:\pdf\BlackHillsSouthDakotaAndSurroundingSights.pdf этот PDF-файл также просто, как команда java -jar pdfbox-app-2.0.2.jar Decrypt -password DustinWasHere C:\pdf\BlackHillsSouthDakotaAndSurroundingSights.pdf как показано на следующем снимке экрана. Изображение демонстрирует, что InvalidPasswordException генерируется, когда пароль не предоставлен (или введен неверный пароль) для расшифровки PDF, а затем он показывает успешное дешифрование, и я снова могу открыть PDF в Adobe Reader без пароля.
Объединение PDF-файлов: «PDFMerger»
PDFBox позволяет объединять несколько PDF-файлов в один PDF-файл с помощью команды «PDFMerger». Это демонстрируется на следующих снимках экрана путем объединения двух упомянутых ранее одностраничных PDF-файлов ( doi.pdf и BlackHillsSouthDakotaAndSurroundingSights.pdf в новый PDF-файл third.pdf с помощью команды java -jar pdfbox-app-2.0.2.jar PDFMerger C:\pdf\doi.pdf C:\pdf\BlackHillsSouthDakotaAndSurroundingSights.pdf C:\pdf\third.pdf .


Разделение PDF-файлов: «PDFSplit»
Я могу разделить third.pdf PDF-файл, только что созданный с помощью PDFMerger с помощью команды PDFSplit . Это особенно простой случай, потому что разделение PDF занимает всего две страницы. Команда демонстрируется со следующими снимками экрана.


third.pdf демонстрируют, что PDF-файлы, third.pdf из third.pdf , называются third.pdf third-1.pdf и third-2.pdf .
Вывод
В этом посте я показал несколько доступных из командной строки утилит командной строки без необходимости Java-кодирования. Есть несколько других доступных утилит командной строки, которые здесь не демонстрировались. Все эти команды легко используются при запуске исполняемого файла JAR «app», поставляемого с дистрибутивом PDFBox. Как утилиты командной строки, эти инструменты обладают преимуществами инструментов командной строки, в том числе быстротой запуска и возможностью включения в сценарии и другие автоматизированные инструменты. Еще одним преимуществом этих инструментов является то, что, поскольку они реализованы с открытым исходным кодом, разработчики могут использовать исходный код этих инструментов, чтобы увидеть, как использовать API-интерфейсы PDFBox в своих собственных приложениях и инструментах. Инструменты командной строки Apache PDFBox являются свободно доступными и простыми в использовании инструментами манипулирования PDF, которые можно использовать без написания дополнительного кода Java.
| Ссылка: | Apache PDFBox Инструменты командной строки: не требуется Java-кодирование от нашего партнера JCG Дастина Маркса в блоге Inspired by Actual Events . |