После запуска приложения-прототипа одним из приоритетов является инициализация базы данных, а также управление изменениями схемы базы данных.
Игра дает нам эволюцию . Используя эволюции, мы можем создавать нашу базу данных и управлять любыми изменениями схемы в будущем.
Для начала нам нужно добавить зависимость jdbc и зависимость evolutions.
|
1
2
|
libraryDependencies += evolutionslibraryDependencies += jdbc |
Затем мы будем использовать простую базу данных h2, сохраненную на диске, в качестве базы данных по умолчанию для нашего приложения воспроизведения.
Мы редактируем файл conf / application.conf и добавляем следующие строки.
|
1
2
|
db.default.driver=org.h2.Driverdb.default.url="jdbc:h2:/tmp/defaultdatabase" |
Обратите особое внимание на то, что наша база данных находится в каталоге tmp, поэтому все изменения должны быть удалены после перезагрузки нашей рабочей станции.
После того, как мы настроили нашу базу данных, мы готовы создать наш первый SQL-оператор.
Наши скрипты должны находиться в каталоге conf / evolutions / {имя вашей базы данных}, поэтому в нашем случае
/ CONF / эволюции / по умолчанию.
Наш первый скрипт «1.sql» должен создать таблицу пользователей.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
# Users schema# --- !UpsCREATE TABLE users ( id bigint(20) NOT NULL AUTO_INCREMENT, email varchar(255) NOT NULL, first_name varchar(255) NOT NULL, last_name varchar(255) NOT NULL, PRIMARY KEY (id), UNIQUE KEY (email));# --- !DownsDROP TABLE users; |
Как мы видим, у нас есть взлеты и падения. За что они стоят? Как вы уже догадались, описывают преобразования, в то время как описывают, как их вернуть.
Таким образом, следующий вопрос: как эта функциональность используется?
Предположим, у вас есть два разработчика, работающих над 2.sql. Локально они успешно перенесли свою базу данных после завершения, однако результат слияния значительно отличается от файла, который они выполнили в своей базе данных.
Что эволюция делает, так это обнаруживает, если файл отличается, и возвращает старую версию, применяя даунс, а затем применяя последнюю версию.
Теперь мы готовы запустить наше приложение.
|
1
|
sbt run |
Как только мы переместимся на localhost: 9000, мы увидим экран, который заставляет нас запускать обнаруженные эволюции.
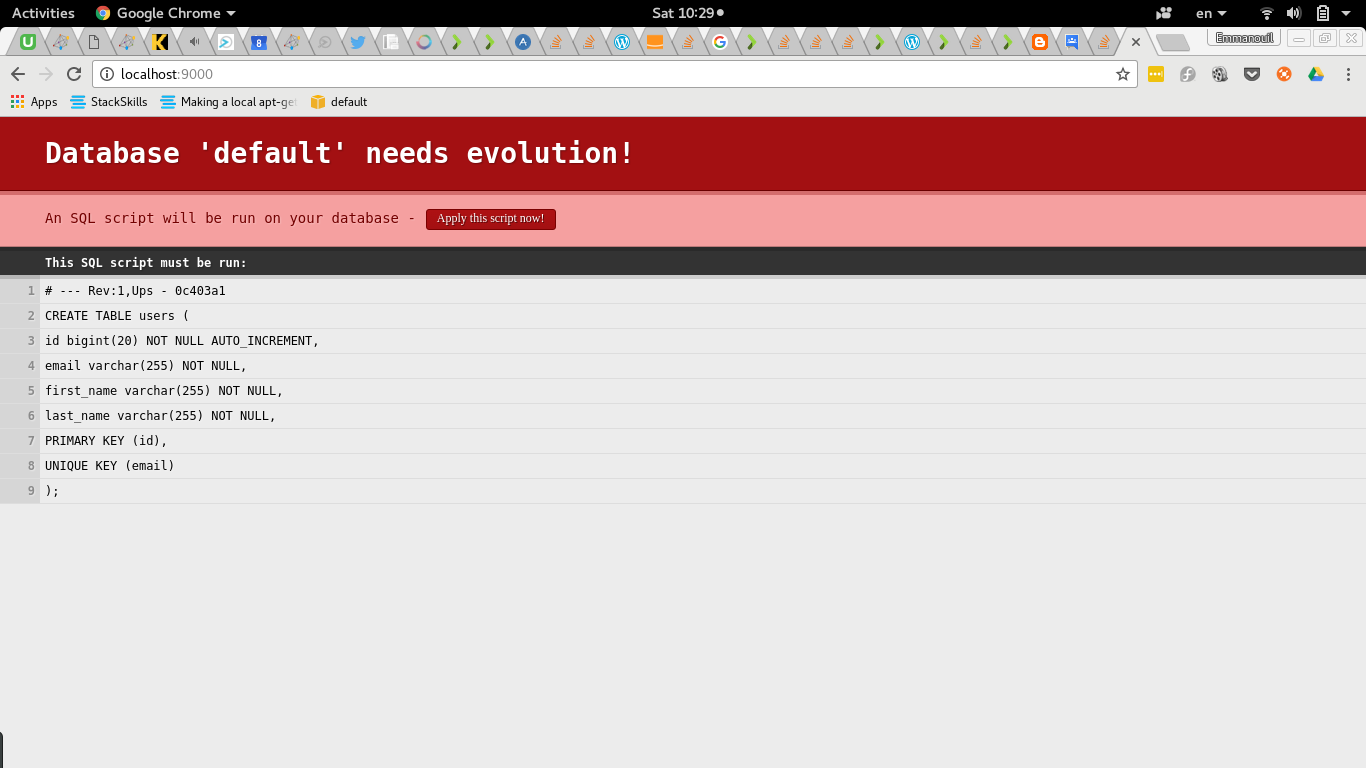
Давайте сделаем еще один шаг и посмотрим, что было сделано с нашей схемой базы данных. Мы можем легко изучить базу данных h2, используя dbeaver или your ide.
При выдаче таблиц показа результаты содержат одну дополнительную таблицу.
|
1
2
3
4
5
|
>SHOW TABLES;TABLE_NAME,TABLE_SCHEMAPLAY_EVOLUTIONS,PUBLICUSERS,PUBLIC |
Таблица PLAY_EVOLUTIONS отслеживает наши изменения
Идентификатор — это номер сценария эволюции, который мы создали. Поля применяются и возвращаются — это взлеты и падения, которые мы создали ранее.
Хеш поля используется для обнаружения изменений в нашем файле. В случае эволюции, которая имеет хеш, отличающийся от примененного, предыдущая эволюция отменяется и применяет новый сценарий.
Например, давайте улучшим наш предыдущий скрипт и добавим еще одно поле. Поле имени пользователя.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
# Users schema# --- !UpsCREATE TABLE users ( id bigint(20) NOT NULL AUTO_INCREMENT, email varchar(255) NOT NULL, username varchar(255) NOT NULL, first_name varchar(255) NOT NULL, last_name varchar(255) NOT NULL, PRIMARY KEY (id), UNIQUE KEY (email));# --- !DownsDROP TABLE users; |
Как только мы запустим наше приложение, нам будет представлен экран, который заставляет нас выпустить эволюцию для нашей другой ревизии. Если мы нажмем применить, таблица пользователей должна содержать поле имени пользователя.
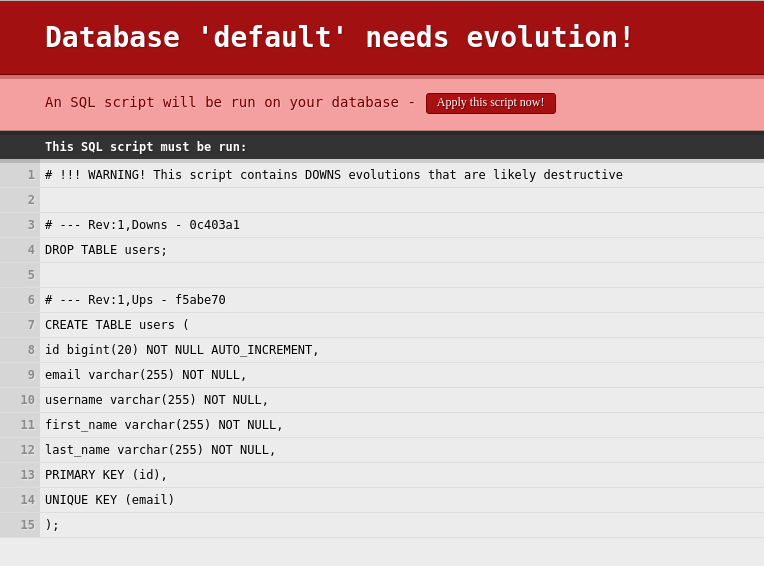
Таким образом, процесс новой редакции довольно прост.
Хеш из нового файла 1.sql извлекается. Затем запрос проверяет, был ли файл 1.sql уже применен. Если он был применен, выдается проверка, если хэши совпадают. Если это не так, выполняется скрипт downs из текущей записи базы данных. После завершения новый скрипт применяется.
| Ссылка: | Инициализация базы данных с помощью play и Scala от нашего партнера по JCG Эммануила Гкациоураса в блоге gkatzioura . |