Эта статья была первоначально написана Полом Трембертом
Что такое MusicBrainz?
Цитируя
Википедию ,
MusicBrainz — это «музыкальная база данных с открытым контентом, [которая] была основана в ответ на ограничения, наложенные на CDDB. (…) MusicBrainz собирает информацию об артистах, их записанных работах и отношениях между ними».
 |
| http://en.wikipedia.org/wiki/MusicBrainz |
Любой может просмотреть базу данных по адресу
http://musicbrainz.org/ . Если вы создадите с ними учетную запись, вы сможете добавить новые данные или исправить данные существующих записей, отследить длительность, отправить в отсканированные изображения ваших любимых альбомов и т. Д. Изменения рецензируются, и любой участник может проголосовать за или против. Есть много общего с Википедией.
В этом первом посте мы хотим показать вам, как импортировать данные Musicbrainz в Neo4j для дальнейшего анализа с
Cypher во втором посте. Смотрите ниже, что мы получим в итоге:
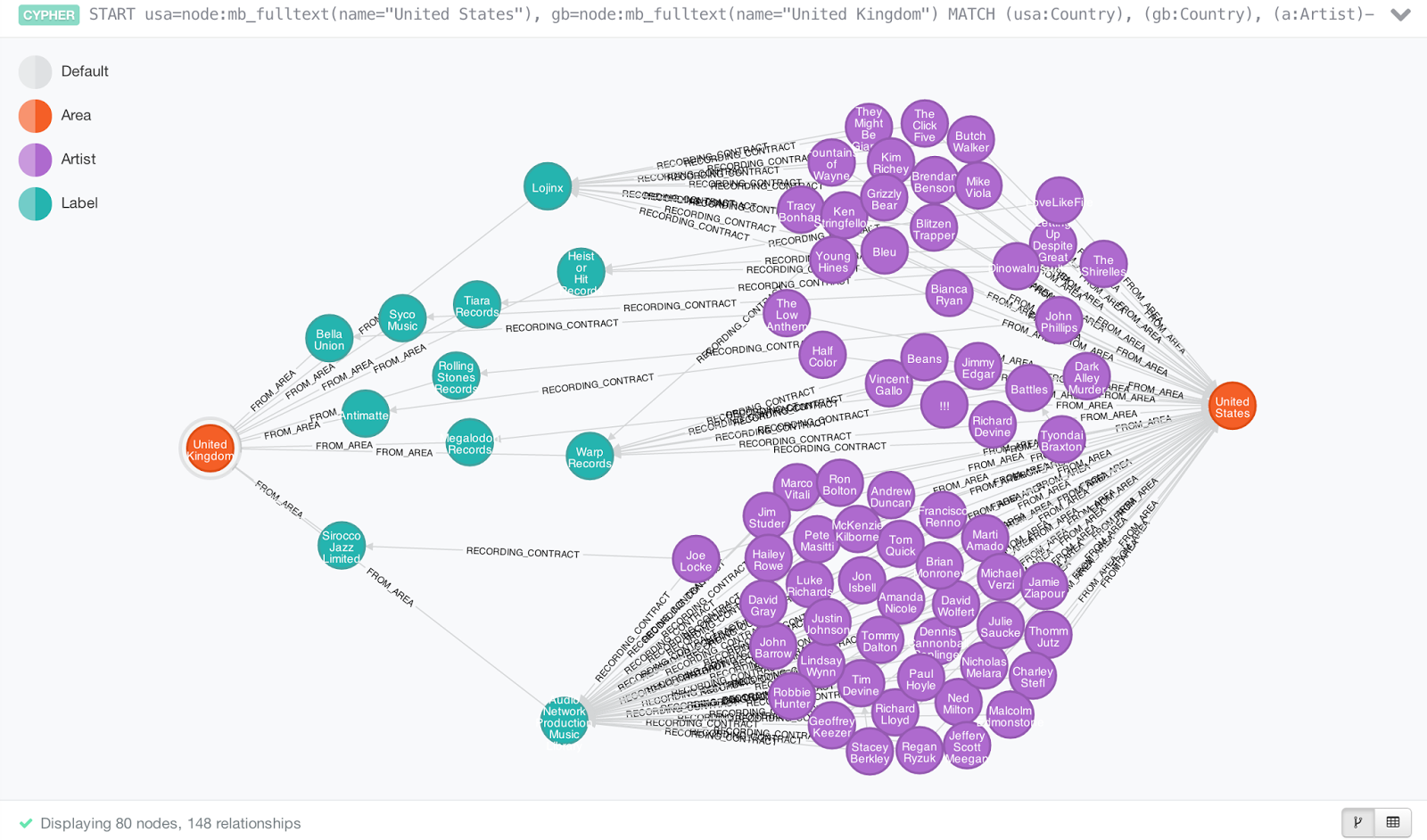 |
| Американские артисты подписались на британские лейблы |
Приведенный выше запрос является результатом этого запроса Cypher, в котором перечислены американские исполнители, подписанные на британских лейблах:
START usa=node:mb_fulltext(name="United States"), gb=node:mb_fulltext(name="United Kingdom") MATCH (usa:Country), (gb:Country), (a:Artist)-[:FROM_AREA]-(usa), (a:Artist)-[:RECORDING_CONTRACT]-(l:Label), (l)-[:FROM_AREA]-(gb) RETURN a,l,usa,gb
MusicBrainz Data
MusicBrainz в настоящее время насчитывает
около 1000 активных пользователей , около 800 000 исполнителей, 75 000 звукозаписывающих лейблов, около 1 200 000 релизов, более 12 000 000 треков и короткие URL-адреса менее 2 000 000 для этих объектов (страниц Википедии, официальных домашних страниц, каналов YouTube и т. Д.) Ежедневные исправления сообщества делает их данные, вероятно, самыми свежими и точными в Интернете.
Вы можете проверить текущие номера
здесь и
здесь .
Это много взаимосвязанных данных! Что делает его идеальным кандидатом на Neo4j.
Все объекты (исполнители, лейблы, релизы и т. Д.) Идентифицируются по их
идентификатору MusicBrainz (MBID. Вероятно, он наиболее близок к универсальному UUID для индустрии звукозаписи. Чтобы найти MBID своей любимой группы, выполните поиск на главной странице сайта). В строке поиска вверху щелкните по нужному исполнителю (может быть много омонимов), а в адресной строке вашего браузера MBID является последней частью URL-адреса. Например, это URL-адрес страницы Maxïmo Park на MusicBrainz:
Их MBID — «
92e634a7-6023-4be8-be15-ebba822f5b34 ».
MBID стал де-факто точкой отсчета для музыкальных данных, с , например , Last.fm и многие другие , используя его
Лицензия данных Musicbrainz
Когда речь идет об общедоступных источниках данных, вопрос об их лицензии всегда является одним из первых вопросов, на которые следует обратить внимание. В случае с Musicbrainz это две интерпретации.
Основные данные
Основные данные, как отмечалось выше, лицензируются в рамках
CC0 , который фактически помещает данные в общественное достояние. Это означает, что каждый может загружать и использовать основные данные любым удобным для них способом. Никаких ограничений, никаких забот!
Из Википедии,
Начиная с 2003 года
[10] Основные данные MusicBrainz ( в художники, записи, альбомы и т.д.) находятся в
общественном достоянии , и дополнительного контента, включая данные модерации ( по сути каждый
оригинальный контент , пополняемая пользователями и его проработок), находится под
Лицензия Creative Commons
CC-BY-NC-SA -2.0.
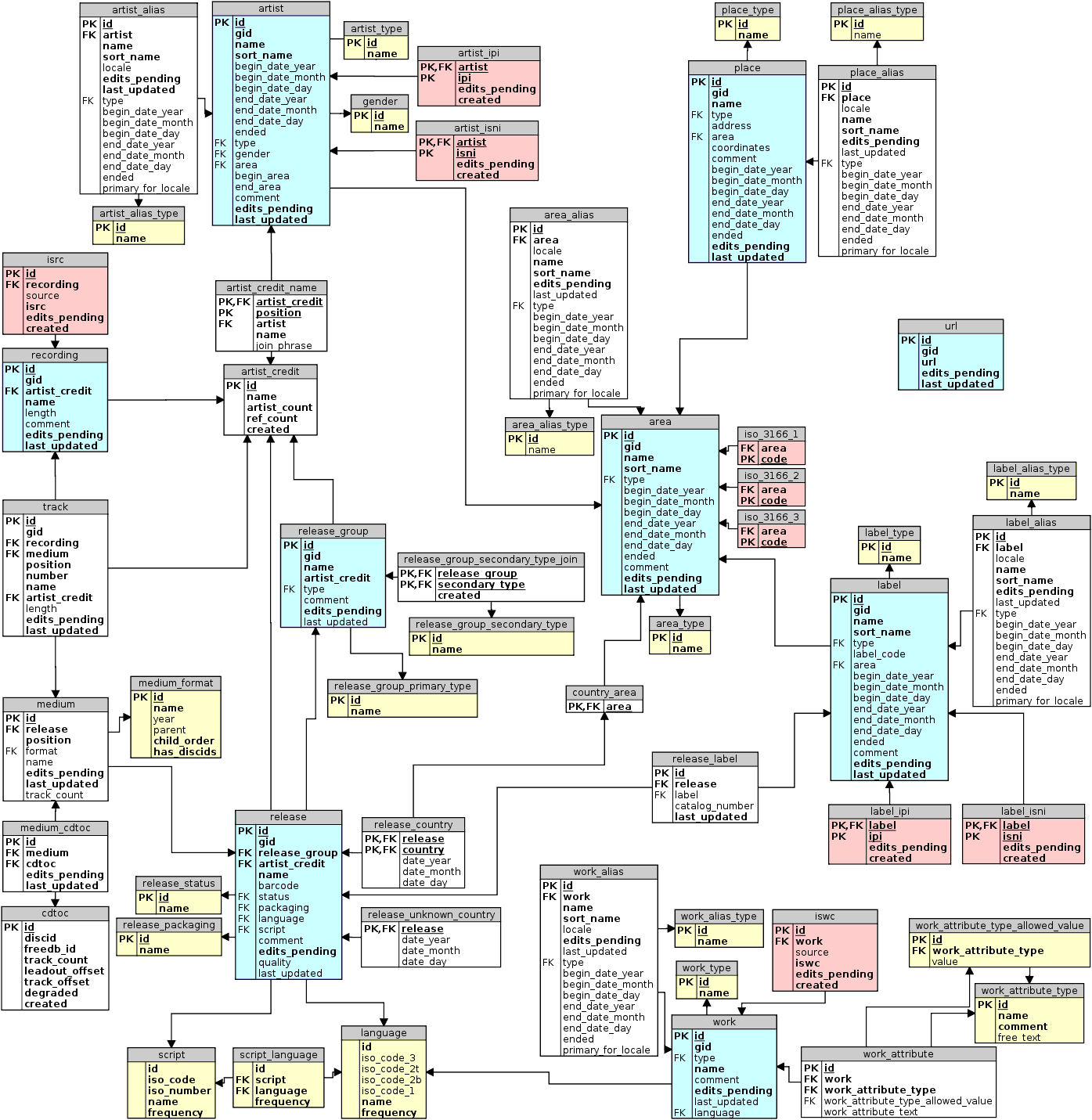
Реляционная модель
Сервер MusicBrainz написан на Perl с бэкэндом PostgreSQL. Это на самом деле с открытым исходным кодом. и вы можете взглянуть на схему таблицы на github:
https://github.com/metabrainz/musicbrainz-server/blob/master/admin/sql/CreateTables.sql
Вот как разные таблицы связаны в реляционной модели MusicBrainz:

{kind=link}
Как вы можете видеть, таблицы глубоко нормализованы, и это немного пугает, когда вы начинаете в них погружаться. (так называемая NGS, схема следующего поколения,
http://wiki.musicbrainz.org/Next_Generation_Schema )
Как бы выглядели данные MusicBrainz на графике?
Сущностям на нашем графике будут назначены метки Neo4j, которые приблизительно соответствуют именам таблиц SQL (именам в пузырьках). Ниже приведено упрощенное представление о том, как сущности MusicBrainz связаны в графовой модели Neo4j:
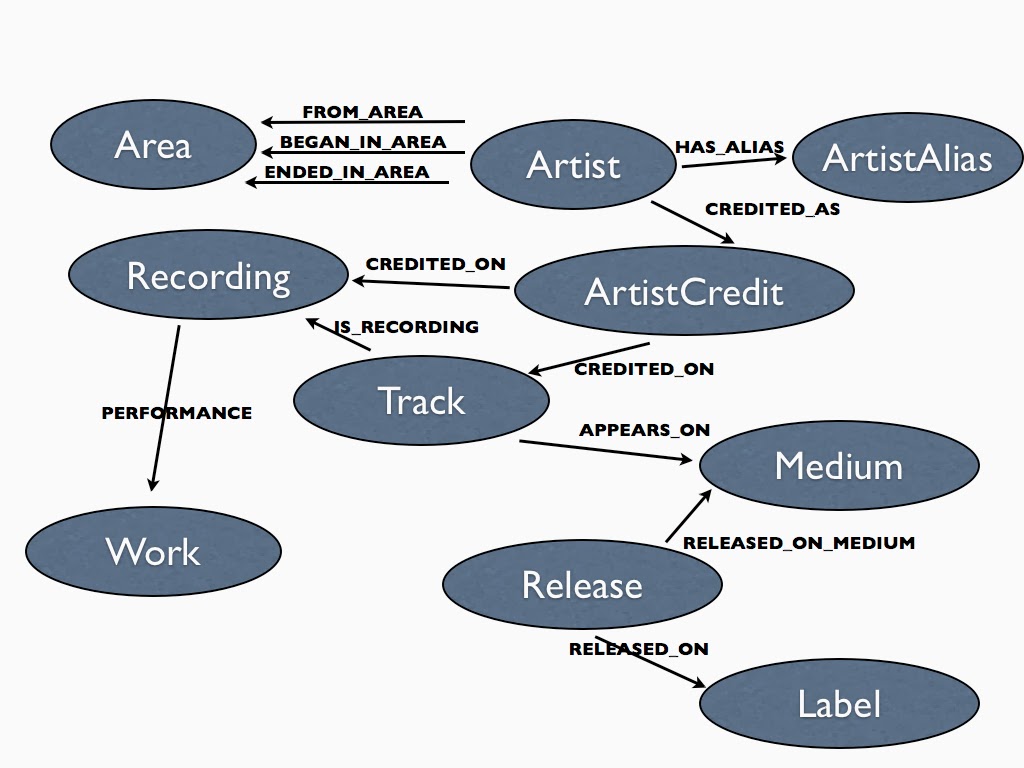 |
| Neo4j Musicbrainz Схема |
Что с компанией «Artist Credit»?
Ну, это когда несколько исполнителей работали или играли на треке или записи.
Например, «Телефон» Леди Гага также включает в себя Бейонсе (
http://musicbrainz.org/recording/4daf26b7-7cf3-4752-bebc-9bb23a4648e1 ), так что в этой записи упоминается два художника, Леди Гага (MBID 650e7db6- b795-4eb5-a702-5ea2fc46c848) и Бейонсе (MBID 859d0860-d480-4efd-970c-c05d5f1776b8). Но заслуга трека — «Lady Gaga feat. Бейонсе». Вы можете найти более подробную информацию здесь:
http://musicbrainz.org/doc/Artist_Credit
Как импортировать данные MusicBrainz в Neo4j?
«Это все красиво и красиво, но как мне получить этот замечательный набор данных в Neo4j?»
Инструмент SQL2GRAPH
подробные инструкции см. Здесь .
Шаг 1 — получить локальную копию базы данных
Вы можете иметь свое собственное зеркало PostgreSQL базы данных MusicBrainz, используя изящный проект Python под названием «mbslave» Лукаша Лалинского ( https://bitbucket.org/lalinsky/mbslave ) и передать его дампом
базы данных MusicBrainz (получите этот дамп после инструкции от
http://wiki.musicbrainz.org/MusicBrainz_Database/Download ). Основной дамп данных
mbdump.tar.bz2 находится в открытом доступе и составляет 1,5 ГБ. Пожалуйста, используйте зеркало, которое наиболее близко к вам (ЕС или США). Вы должны быть хороши, чтобы пойти с этим.
См.
Http://musicbrainz.org/doc/MusicBrainz_Database/Download для других способов получения данных (виртуальная машина, зеркало MySQL).
Шаг 2 — Экспорт данных в CSV / TSV с помощью sql2graph
Для такого объема данных (около 30 миллионов основных объектов и множества взаимосвязей между ними) мы рекомендуем инструмент, который мы предлагаем: проект пакетного импорта Майкла Хангера
(сейчас выберите ветку «20» для поддержки Neo4j 2.0)
.
Это инструмент, который принимает TAB-файлы значений в качестве входных данных и заполняет хранилище данных Neo4j. Формат довольно прост и обычно требует всего два файла: первый с узлами и их свойствами, а второй — для связи между этими узлами.
Вы можете создать эти файлы несколькими способами, но я написал модуль Python, чтобы помочь вам с этим: sql2graph (
https://github.com/redapple/sql2graph )
Как работает sql2graph
sql2graph также нуждается в небольшой помощи от вас, поскольку он принимает в качестве входных данных (Python) представление схемы, сопоставляющей таблицы SQL с узлами, свойствами и связями графа. (Классы Python, используемые в отображении схемы sql2graph, заимствованы из кода mbslave для экспорта MusicBrainz в Solr.)
Для каждой основной сущности, которую мы хотели бы использовать в качестве узлов на нашем графике, мы преобразовываем соответствующую схему таблицы SQL в сущность и ее свойства.
Например, таблица «Artist» (
https://github.com/metabrainz/musicbrainz-server/blob/master/admin/sql/CreateTables.sql#L95 ) сопоставлена с:
Entity('artist',
[
IntegerProperty('pk', Column('id')),
Property('mbid', Column('gid')),
Property('disambiguation', Column('comment')),
Property('name', Column('name')),
],
Все экземпляры Entity () имеют:
-
имя, здесь «исполнитель», которое станет меткой: Artist для узлов.
-
список экземпляров Property (), которые также имеют имя, которое станет свойствами узла
-
обязательное свойство первичного ключа, называемое «pk», которое используется sql2graph для разрешения связей между сущностями при создании отношений; обычно это имя столбца «id» в таблицах SQL (это свойство «pk» не очень полезно в конечном графике)
Каждое свойство () может ссылаться на столбец SQL в той же таблице или в связанной таблице (через экземпляр ForeignColumn () в качестве второго параметра)
А как насчет отношений?
Субъекты могут иметь отношения с другими сущностями (вот и весь смысл в том, чтобы поместить их в график, верно?). Вы определяете их после списка свойств для своих узлов, как список экземпляров Relation ().
Давайте продолжим с примером сущности «Artist»,
Entity('artist',
[
IntegerProperty('pk', Column('id')),
Property('mbid', Column('gid')),
Property('disambiguation', Column('comment')),
Property('name', Column('name', ForeignColumn('artist_name', 'name'))),
],
[
Relation(
'FROM_AREA',
start=Reference('artist', Column('id')),
end=Reference('area', Column('area')),
properties=[]
),
Relation(
'BEGAN_IN_AREA',
start=Reference('artist', Column('id')),
end=Reference('area', Column('begin_area')),
properties=[]
),
Relation(
'ENDED_IN_AREA',
start=Reference('artist', Column('id')),
end=Reference('area', Column('end_area')),
properties=[]
),
],
),
Мы только что определили 3 типа отношений:
-
«ОТ»: представляет связь между таблицей «художник» и таблицей «площадь», представляющую, откуда художник (родился или построил свою карьеру)
-
«BEGAN_IN» и «ENDED_IN» также представляют собой связь между таблицами «Artist» и «Area», но они представляют место рождения и место смерти исполнителя (или группы иногда)
Все отношения должны иметь «начальную сущность» и «конечную сущность», используя класс Reference (), который очень похож на класс Property ().
Наконец, отношения также могут иметь свои собственные свойства. Таким образом, вы можете добавить объекты Property () в качестве четвертого параметра в Relation. Пример с таблицей release_label, которая связывает выпуск с лейблом звукозаписи, который выпустил его (очевидно;), и эта таблица может содержать информацию о номере по каталогу. Это переводится на:
Entity('release_label',
[],
[
Relation(
'RELEASED_ON',
start=Reference('release', Column('release')),
end=Reference('label', Column('label')),
properties=[
Property('catalog_number', Column('catalog_number')),
]
),
]
),
Для таблицы «release_label» нам не нужно создавать узлы в Neo4j, нас интересует только связь между двумя сущностями «release» и «label», поэтому параметры Properties оставлены в пустом списке Python, [ ].
Экспорт узлов и отношений с использованием запросов SQL
Как только вы определили это отображение схемы, вы можете запустить sql2graph, и он выведет хороший SQL-скрипт, который вы дадите psql, который можно экспортировать напрямую в TSV.
sql2graph был вдохновлен постами Макса Де Марци в блоге об использовании пакетного импорта: часть 1 (
http://maxdemarzi.com/2012/02/28/batch-importer-part-1/ ) и часть 2 (
http: // maxdemarzi) .com / 2012/02/28 / партия-импортер-часть-2 / )
Работает в 3 этапа:
-
во-первых, он создает временную таблицу (в самой СУБД), сопоставляющую значения первичных ключей объекта с идентификаторами узлов в Neo4j. Эта таблица SQL имеет 3 столбца: «entity», «pk» и «node_id»
-
затем он сбрасывает данные узлов для всех таблиц, для которых вы определили свойства узлов в формате TSV (PostgreSQL может сделать это, см.
http://maxdemarzi.com/2012/02/28/batch-importer-part-2/ )
-
наконец, он экспортирует отношения как TSV, используя экземпляры Relation () и Property (), которые вы определили в приведенном выше сопоставлении, и обрабатывает идентификаторы узлов с использованием временной таблицы.
|
SQL таблица «художник»:
Таблица SQL «метка»:
|
Временный картографический стол:
|
«О, чувак, но у MusicBrainz так много таблиц … Нужно ли мне самому определять эту вещь для перевода схемы? а в питоне ?? На самом деле мы сделали всю работу за вас. Либо настройте отображение, чтобы добавить или удалить несколько свойств или сущностей, и запустите sql2graph… или просто захватите сценарий экспорта SQL и отправьте его в psql.
$ git clone git@github.com: redapple / sql2graph.git
$ cd sql2graph
$ ./musicbrainz2neo4j-export.py> musicbrainz2neo4j.sql
Предварительно сгенерированный файл SQL доступен по адресу sql2graph / examples / musicbrainz / musicbrainz2neo4j.sql
batch-import поддерживает автоматическую индексацию, если столбцы вашего CSV-заголовка содержат тип и имя индекса, например «name: string: mb», если поле «name» в узлах является строкой, которую вы хотите проиндексировать в индексе с именем «mb» ,
$ cd / path / to / mbslave
$ cat /path/to/musicbrainz2neo4j.sql | ./mbslave-psql.py
Сгенерированный выше скрипт экспорта MusicBrainz SQL предполагает 2 индекса: «mb_fulltext» в качестве полнотекстового индекса и «mb_exact» в качестве точного индекса. Убедитесь, что ваш файл batch.properties объявляет эти 2 индекса (см. Ниже «Импорт с использованием batch-import»):
-
Столбцы «mbid» будут проиндексированы в индексе «mb_exact», а столбцы «type» станут метками на узлах.
-
«Имя» будет проиндексировано в индексе «mb_fulltext»
По умолчанию сценарий экспорта SQL сообщает psql выводить два файла в каталог / tmp, один для узлов и один для отношений: musicbrainz__full__nodes.csv и musicbrainz__full__rels.csv.
Шаг 3 — Импорт с использованием пакетного импорта Neo4j
Запуск пакетного импорта с этими двумя файлами должен дать вам что-то вроде: (на маленьком компьютере Пола это занимает примерно 1 час и 30 минут, на лучшем MacBookPro около 20 минут). Обязательно настройте конфигурацию neo4j так, чтобы у импортера были хорошие ресурсы. Файл Peters
batch.properties выглядит примерно так
batch_import.keep_db=true batch_import.mapdb_cache.disable=true batch_import.node_index.mb_fulltext=fulltext batch_import.node_index.mb_exact=exact batch_import.csv.quotes=false cache_type=none use_memory_mapped_buffers=true neostore.nodestore.db.mapped_memory=300M neostore.relationshipstore.db.mapped_memory=3G neostore.propertystore.db.mapped_memory=500M neostore.propertystore.db.strings.mapped_memory=500M neostore.propertystore.db.arrays.mapped_memory=0M neostore.propertystore.db.index.keys.mapped_memory=15M neostore.propertystore.db.index.mapped_memory=15M
При этом мы можем импортировать файлы (используя кодировку UTF-8) с помощью:
cd / path / to / jexp / batch-import
MAVEN_OPTS = «- server -Xmx10G -Dfile.encoding = UTF-8» mvn exec: java -Dfile .encoding = UTF-8 -Dexec.mainClass = «org.neo4j.batchimport.Importer» -Dexec.args = «batch.properties musicbrainz.db /tmp/musicbrainz__nodes__full.csv /tmp/musicbrainz__rels__full.csv: get: ccs»
:
Использование java -jar batchimport.jar data / dir node.csv relationss.csv [node_index имя-индекса-узла полный текст | точные узлы-индексы.csv rel_index-имя-индекса полное имя-текста | точное значение rels_index.csv ….]
Использование существующего файла конфигурации
Импорт musicbrainz__nodes__full.csv …
………………………………………….. ………………………………………….. 512172 мс для 10000000
………………………………………….. ………………………………………….. 608539 мс для 10000000
………………………………………….. ………………………………………….. 588464 мс для 10000000
………………………………………….. ..
Импорт 35294004 узлов занял 2057 секунд
Импорт musicbrainz__rels__full.csv …
………………………………………….. ………………………………………….. 438932 мс для 10000000
………………………………………….. ………………………………………….. 338665 мс для 10000000
………………………………………….. ………………………………………….. 194668 мс на 10000000
………………………………………….. ………………………………………….. 421573 мс для 10000000
………………………………………….. ………………………………………….. 535700 мс для 10000000
………………………………………….. ………………………………………….. 529039 мс для 10000000
………………………………………….. ………………………………………….. 634684 мс на 10000000
…………………..
Импорт 72373185 отношений занял 3249 секунд
Общее время импорта: 5595 секунд
Пол @ хриплый: / путь / к / Neo4j / MusicBrainz $
Теперь давайте нацелим наш сервер Neo4j на нашу недавно созданную базу данных Musicbrainz в ее
neo4j-server.properties и рассмотрим пример запроса: Вуаля!
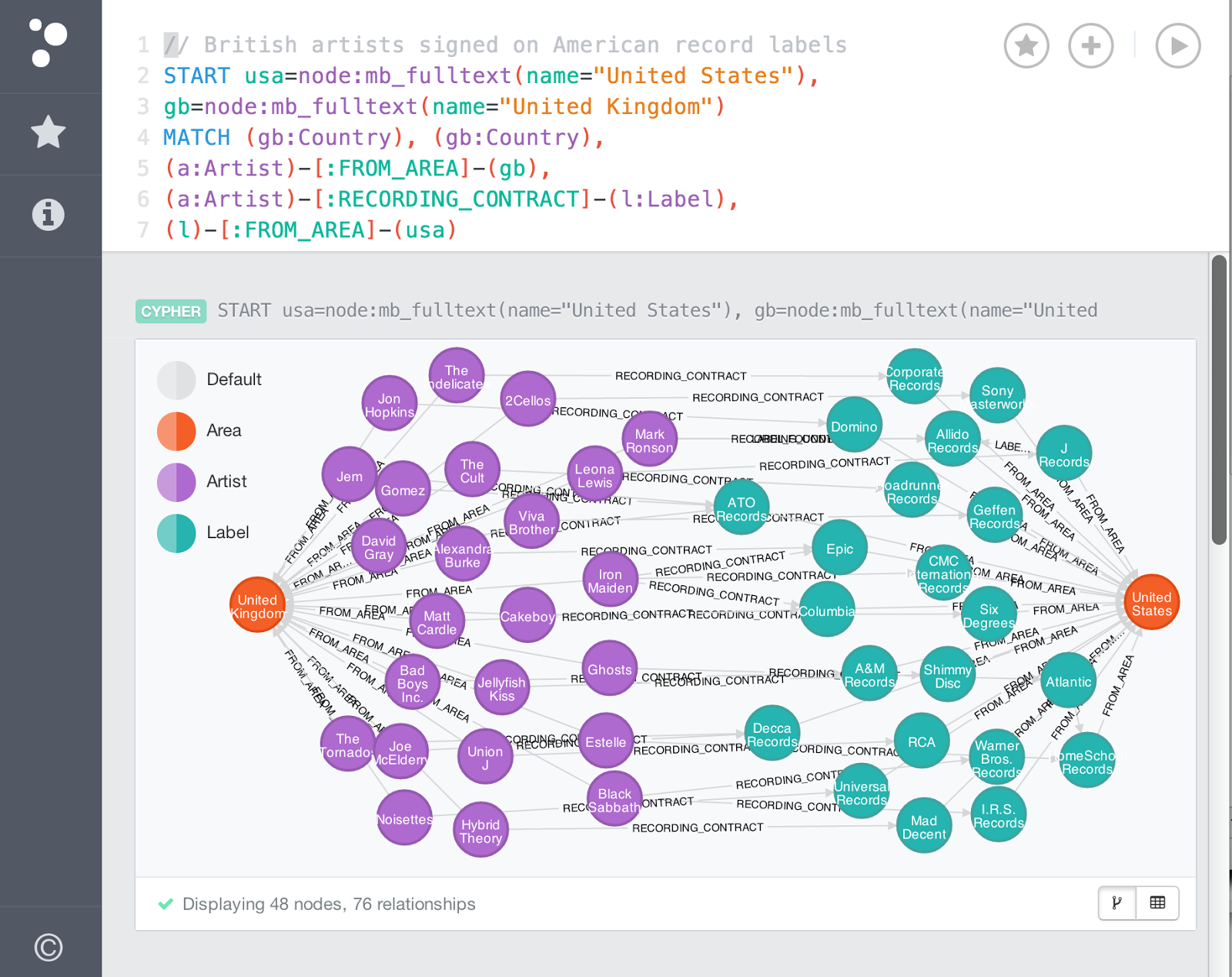 |
| Британские артисты подписались на американских звукозаписывающих лейблах |
Запрос Cypher для этого результата:
START usa=node:mb_fulltext(name="United States"), gb=node:mb_fulltext(name="United Kingdom") MATCH (gb:Country), (gb:Country), (a:Artist)-[:FROM_AREA]-(gb), (a:Artist)-[:RECORDING_CONTRACT]-(l:Label), (l)-[:FROM_AREA]-(usa) RETURN a,l,usa,gb
В следующем посте мы рассмотрим несколько интересных запросов по этим данным, следите за обновлениями!
Большое спасибо Michael Hunger, Peter Neubauer, Max DeMarzi и фантастическому сообществу Neo4j за помощь и вдохновение для этого блога!