DSL — классные вещи, но мне не было ясно, для чего они хороши.
Тогда я понял, что они хороши для:
- избавиться от сложных интерфейсов
что значит
- более быстрый способ делать вещи
Вот и все. Я пришел к такому выводу, когда я прочитал этот блог .
Если ваш пользователь технарь и не боится SQL-подобного синтаксического подхода, DSL отлично подойдут, если
- у вас есть подсветка синтаксиса
- у вас есть завершение кода
В противном случае DSL вроде отстой.
Итак, я должен был представить некоторые доказательства концепции для клиента. У него нечеткие требования, и нелегко извлечь именно то, что нужно его команде (им нужно много вещей, а он очень занят), поэтому DSL может очень помочь в этом процессе, потому что люди вынуждены думать именно то, что им нужно, когда они сталкиваются с грамматикой (даже маленькой).
Итак, я пошел с этими технологиями:
- JSF библиотека Primefaces расширения для кода зеркала
- ANTLR4 (большое улучшение по сравнению с ANTLR3, и книга великолепна)
К сожалению, я не смог повторно использовать грамматику в обоих инструментах. На самом деле, я не мог найти решение, которое могло бы сделать это. По крайней мере, для веб-решения JSF. И не было времени учиться. Поэтому мне пришлось немного взломать.
Во-первых, нам нужна грамматика. ANTLR4 намного лучше, чем ANTLR3, потому что теперь код подключения выполняется через посетителей и слушателей. Нет больше кода Java внутри грамматики. Это здорово и намного проще работать.
Таким образом, вы можете иметь такую грамматику
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
grammar Grammar;options{ language = Java;}@lexer::header { package parsers;}@parser::header { package parsers;}eval : expr EOF;expr : 'JOB' (jobName)? type 'TARGET' targetList ('START' startExpr)?startExpr : 'AT' cronTerm | 'AFTER' timeAmount timeUnits;timeAmount: INT; jobName: STRING; targetList: STRING (',' STRING)*; type : deleteUser | createUser;deleteUser: opDelete userName;createUser: opCreate userName;opDelete: 'DELETE';opCreate: 'CREATE';userName: STRING; cronTerm: '!'? (INT | '-' | '/' | '*' | '>' | '<')+;timeUnits : 'MINUTES' | 'HOURS' | 'DAYS' | 'WEEKS' | 'MONTHS';WS : [ \t\r\n]+ -> skip;STRING : '"' ( ESC_SEQ | ~('\\'|'"') )* '"' ;fragmentHEX_DIGIT : ('0'..'9'|'a'..'f'|'A'..'F') ;fragmentESC_SEQ : '\\' ('b'|'t'|'n'|'f'|'r'|'\"'|'\''|'\\') | UNICODE_ESC | OCTAL_ESC ;fragmentOCTAL_ESC : '\\' ('0'..'3') ('0'..'7') ('0'..'7') | '\\' ('0'..'7') ('0'..'7') | '\\' ('0'..'7') ;fragmentUNICODE_ESC : '\\' 'u' HEX_DIGIT HEX_DIGIT HEX_DIGIT HEX_DIGIT ;ID : ('a'..'z'|'A'..'Z'|'_') ('a'..'z'|'A'..'Z'|'0'..'9'|'_')* ;INT : '0'..'9'+ ; |
Чтобы скомпилировать свою грамматику, попробуйте
|
1
2
3
4
|
public static void main(String[] args) { String[] arg0 = {"-visitor","/pathto/Grammar.g4"}; org.antlr.v4.Tool.main(arg0); } |
Тогда ANTLR сгенерирует классы для вас.
В нашем случае мы хотим посетить дерево разбора и получить нужные значения. Мы делаем это, расширяя сгенерированный абстрактный класс.
|
001
002
003
004
005
006
007
008
009
010
011
012
013
014
015
016
017
018
019
020
021
022
023
024
025
026
027
028
029
030
031
032
033
034
035
036
037
038
039
040
041
042
043
044
045
046
047
048
049
050
051
052
053
054
055
056
057
058
059
060
061
062
063
064
065
066
067
068
069
070
071
072
073
074
075
076
077
078
079
080
081
082
083
084
085
086
087
088
089
090
091
092
093
094
095
096
097
098
099
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
|
import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;import java.util.StringTokenizer;import org.antlr.v4.runtime.tree.ErrorNode;import bsh.EvalError;import bsh.Interpreter;public class MyLoader2 extends GrammarBaseVisitor<Void> { private String jobName,cronTerm,timeUnits,userName,jobType; private List<String> targetList; private boolean now,errorFound; private int timeAmount; private Interpreter bsh = new Interpreter(); private String eval(String s) throws EvaluationException{ try { if (!s.startsWith("\"")){ return s; } bsh.eval("String s="+s); return (String)bsh.eval("s"); } catch (EvalError e) { throw new EvaluationException(s); } } @Override public Void visitTimeAmount(TimeAmountContext ctx) { try{ this.timeAmount = Integer.parseInt(ctx.getText()); }catch(java.lang.NumberFormatException nfe){ throw new InvalidTimeAmountException(ctx.getText()); } return super.visitTimeAmount(ctx); } @Override public Void visitUserName(UserNameContext ctx) { this.userName = eval(ctx.getText()); return super.visitUserName(ctx); } @Override public Void visitCronTerm(CronTermContext ctx) { this.cronTerm = eval(ctx.getText()); return super.visitCronTerm(ctx); } @Override public Void visitTimeUnits(TimeUnitsContext ctx) { this.timeUnits = ctx.getText(); return super.visitTimeUnits(ctx); } @Override public Void visitTargetList(TargetListContext ctx) { this.targetList = toStringList(ctx.getText()); return super.visitTargetList(ctx); } @Override public Void visitJobName(JobNameContext ctx) { this.jobName = eval(ctx.getText()); return super.visitJobName(ctx); } @Override public Void visitOpCreate(OpCreateContext ctx) { this.jobType = ctx.getText(); return super.visitOpCreate(ctx); } @Override public Void visitOpDelete(OpDeleteContext ctx) { this.jobType = ctx.getText(); return super.visitOpDelete(ctx); } private List<String> toStringList(String text) { List<String> l = new ArrayList<String>(); StringTokenizer st = new StringTokenizer(text," ,"); while(st.hasMoreElements()){ l.add(eval(st.nextToken())); } return l; } private Map<String, String> toMapList(String text) throws InvalidItemsException, InvalidKeyvalException { Map<String, String> m = new HashMap<String, String>(); if (text == null || text.trim().length() == 0){ return m; } String[] items = text.split(","); if (items.length == 0){ throw new InvalidItemsException(); } for(String item:items){ String[] keyval = item.split("="); if (keyval.length == 2){ m.put(keyval[0], keyval[1]); }else{ throw new InvalidKeyvalException(keyval.length); } } return m; } public String getJobName() { return jobName; } public String getCronTerm() { return cronTerm; } public String getTimeUnits() { return timeUnits; } public String getUserName() { return userName; } public String getJobType() { return jobType; } public List<String> getTargetList() { return targetList; } public boolean isNow() { return now; } public int getTimeAmount() { return timeAmount; } @Override public Void visitOpNow(OpNowContext ctx) { this.now = ctx.getText().equals("NOW"); return super.visitOpNow(ctx); } public boolean isErrorFound() { return errorFound; } @Override public Void visitErrorNode(ErrorNode node) { this.errorFound = true; return super.visitErrorNode(node); }} |
Обратите внимание, что интерпретатор beanhell используется для оценки строки типа «xyz» как xyz. Это особенно полезно для строк, которые содержат экранированные кавычки и символы внутри.
Итак, у вас есть ваша грамматика и ваш компонент посетитель / загрузчик, тогда мы можем проверить это:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
private static MyLoader getLoader(String str){ ANTLRInputStream input = new ANTLRInputStream(str); GrammarLexer lexer = new GrammarLexer(input); CommonTokenStream tokens = new CommonTokenStream(lexer); GrammarParser parser = new GrammarParser(tokens); ParseTree tree = parser.eval(); MyLoader loader = new MyLoader(); loader.visit(tree); return loader;}public static void main(String[] args){ MyLoader loader = getLoader("JOB \"jobName\" CREATE \"myuser\" TARGET \"site1\",\"site2\" START AFTER 1 DAY"); System.out.println(loader.getJobName()); System.out.println(loader.getJobType());} |
Отлично. Теперь это взломать. Code Mirror поддерживает пользовательские грамматики, но отсутствует в расширении JSF Primefaces . Поэтому я открыл файл resources-codemirror-1.2.0.jar, открыл файл /META-INF/resources/primefaces-extensions/codemirror/mode/modes.js, отформатировал его (чтобы я мог его прочитать) и я просто выбрал самый простой язык, чтобы стать моим новым пользовательским подсветчиком синтаксиса!
Я переименовал этот
|
1
2
3
4
5
6
7
8
|
(...)}, "xml"), CodeMirror.defineMIME("text/x-markdown", "markdown"), CodeMirror.defineMode("mylanguage", function (e) {(...) var t = e.indentUnit, n, i = r(["site", "type", "targetList"]), s = r(["AT","AFTER","CREATE","MINUTES","HOURS","TARGET","MONTHS","JOB","DAYS","DELETE","START","WEEKS" ]),(...)}), CodeMirror.defineMIME("text/x-mylanguage", "mylanguage"), CodeMirror.defineMode("ntriples", function () {(...) |
эти парни в верхнем регистре в «s = r» — токены, которые будут подсвечены, в то время как те, кто в «i = r» — токены, которые не будут выделены. Почему мы хотим оба? Поскольку второй тип является «заполнителем», я имею в виду, мы будем использовать их для автозаполнения.
хорошо, тогда ваша страница JSF XHTML будет выглядеть так
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><h:body><h:form id="form"><pe:codeMirror id="codeMirror" style="width:600px;" mode="myLanguage" widgetVar="myCodeMirror" theme="eclipse" value="#{myMB.script}" lineNumbers="true" completeMethod="#{myMB.complete}" extraKeys="{ 'Ctrl-Space': function(cm) { PF('myCodeMirror').complete(); }}"/> <p:commandButton value="Verify" action="#{myMB.verify}" />(...) |
Теперь нам нужны вещи для автозаполнения. Это скучная часть. Вы должны сделать большую часть работы по завершению вручную, потому что там нет контекстной информации (помните, у меня нет времени на изучение…), поэтому быстрый и грязный способ сделать это так
|
001
002
003
004
005
006
007
008
009
010
011
012
013
014
015
016
017
018
019
020
021
022
023
024
025
026
027
028
029
030
031
032
033
034
035
036
037
038
039
040
041
042
043
044
045
046
047
048
049
050
051
052
053
054
055
056
057
058
059
060
061
062
063
064
065
066
067
068
069
070
071
072
073
074
075
076
077
078
079
080
081
082
083
084
085
086
087
088
089
090
091
092
093
094
095
096
097
098
099
100
101
102
103
104
105
106
107
108
109
110
111
|
in myMB public List<String> complete(final CompleteEvent event) { try { return this.myEJB.complete(event.getToken()); } catch (Exception e) { jsfUtilEJB.addErrorMessage(e,"Could not complete"); return null; } } in myEJBprivate static final String SITE = "site_";public List<String> complete(String token) throws Exception { if (token == null || token.trim().length() == 0){ return null; }else{ List<String> suggestions = new ArrayList<String>(); switch(token){ //first search variables case "targetlist": for(String v:TARGETS){ suggestions.add(v); } break; case "site": List<Site> allSites = this.baseService.getSiteDAO().getAll(); for(Site s:allSites){ suggestions.add("\""+SITE+s.getName()+"\""); } break; case "type": suggestions.add("DELETE \"userName\""); suggestions.add("CREATE \"userName\""); break; case "AT": suggestions.add("AT \"cronExpression\""); suggestions.add("AT \"0 * * * * * * *\""); break; case "AFTER": for(int a:AMOUNTS){ for(String u:UNITS){ if (a == 1){ suggestions.add("AFTER"+" "+a+" "+u); }else{ suggestions.add("AFTER"+" "+a+" "+u+"S"); } } } break; case "TARGET": for(String v:TARGETS){ suggestions.add("TARGET "+v+""); } break; case "JOB": suggestions.add("JOB \"jobName\" \ntype \nTARGET targetlist \nSTART"); break; case "START": suggestions.add("START AT \"cronExpression\""); suggestions.add("START AT \"0 * * * * * * *\""); for(int a:AMOUNTS){ for(String u:UNITS){ if (a == 1){ suggestions.add("START AFTER"+" "+a+" "+u); }else{ suggestions.add("START AFTER"+" "+a+" "+u+"S"); } } } suggestions.add("START NOW"); break; case "DELETE": suggestions.add("DELETE \"userName\""); break; case "CREATE": suggestions.add("CREATE \"userName\""); break; default: if (token.startsWith(SITE)){ List<Site> matchedSites = this.baseService.getSiteDAO().getByPattern(token.substring(SITE.length())+"*"); for(Site s:matchedSites){ suggestions.add("\""+SITE+s.getName()+"\""); } }else{ //then search substrings for(String kw:KEYWORDS){ if (kw.toLowerCase().startsWith(token.toLowerCase())){ suggestions.add(kw); } } } }//end switch //remove dups and sort Set<String> ts = new TreeSet<String>(suggestions); return new ArrayList<String>(ts); }}private static final int[] AMOUNTS = {1,5,10};private static final String[] UNITS = {"MINUTE","HOUR","DAY","WEEK","MONTH"};private static final String[] TARGETS = {"site"};/* * KEYWORDS are basic suggestions */private static final String[] KEYWORDS = {"AT","AFTER","CREATE","MINUTES","HOURS","TARGET","MONTHS","JOB","DAYS","DELETE","START","WEEKS"}; |
таким образом, автозаполнение для ключевых слов просто покажет вам поля и больше ключевых слов, в то время как «заполнители» (помните эти строчные ключевые слова в javascript codemirror из jar?) дополнены динамическими значениями, полученными из БД, для фактических значений. Кроме того, вы можете использовать частичные строки для извлечения тех, которые начинаются с подстроки, например:
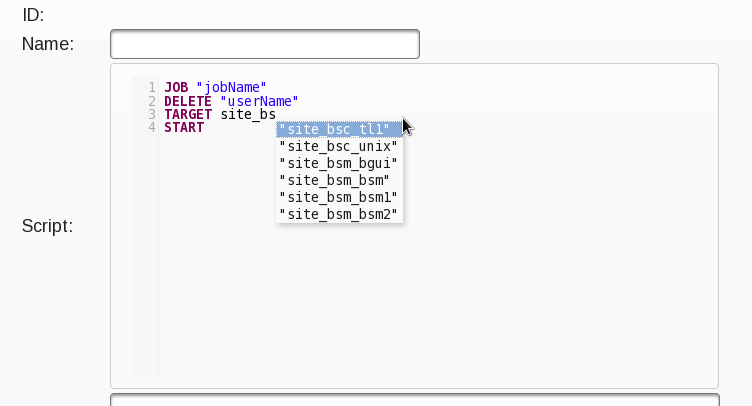
Конечно, поиск по шаблону в JPA может выполняться следующим образом:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
public abstract class GenericDAO<E> { protected EntityManager entityManager; private Class<E> clazz; private EntityType<E> pClass; @SuppressWarnings("unchecked") public GenericDAO(EntityManager entityManager) { this.entityManager = entityManager; ParameterizedType genericSuperclass = (ParameterizedType) getClass().getGenericSuperclass(); this.clazz = (Class<E>) genericSuperclass.getActualTypeArguments()[0]; EntityManagerFactory emf = this.entityManager.getEntityManagerFactory(); Metamodel metamodel = emf.getMetamodel(); this.pClass = metamodel.entity(clazz); } public List<E> getByPattern(String pattern) { pattern = pattern.replace("?", "_").replace("*", "%"); CriteriaBuilder cb = entityManager.getCriteriaBuilder(); CriteriaQuery<E> q = cb.createQuery(clazz); Root<E> entity = q.from(clazz); SingularAttribute<E, String> singularAttribute = (SingularAttribute<E, String>) pClass.getDeclaredSingularAttribute(getNameableField(clazz)); Path<String> path = entity.get(singularAttribute); q.where(cb.like(path, pattern)); q.select(entity); TypedQuery<E> tq = entityManager.createQuery(q); List<E> all = tq.getResultList(); return all; } private String getNameableField(Class<E> clazz) { for(Field f : clazz.getDeclaredFields()) { for(Annotation a : f.getAnnotations()) { if(a.annotationType() == Nameable.class) { return f.getName(); } } } return null; }(...) |
где Nameable — аннотация для ваших классов сущностей:
|
1
2
3
4
|
@Retention(RetentionPolicy.RUNTIME)@Target({ElementType.FIELD})public @interface Nameable {} |
Используйте его, чтобы аннотировать один столбец из вашего класса сущностей, строковый. Как это:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
@Entity@Table(uniqueConstraints=@UniqueConstraint(columnNames={"name"}))public class Site implements Serializable { /** * */ private static final long serialVersionUID = 8008732613898597654L; @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; @Nameable @Column(nullable=false) private String name;(...) |
А кнопка «проверить», конечно же, просто получает ваш скрипт и толкает в загрузчик.