Чтение и запись двоичных данных с помощью Java иногда может быть проблемой. Прочтите эту статью и узнайте, как использовать байты хроники, тем самым делая эти задачи быстрее и проще.
Недавно я участвовал в проекте с открытым исходным кодом «Chronicle Decentred», который представляет собой высокопроизводительную децентрализованную бухгалтерскую книгу, основанную на технологии блокчейна. Для нашего двоичного доступа мы использовали библиотеку «Хроники байтов», которая привлекла мое внимание. В этой статье я поделюсь некоторыми знаниями, которые я получил, используя библиотеку Bytes.
Что такое байты?
Bytes — это библиотека, которая обеспечивает функциональность, аналогичную встроенной в Java
ByteBuffer но, очевидно, с некоторыми расширениями. Оба предоставляют базовую абстракцию буфера для хранения байтов с дополнительными функциями по сравнению с необработанными массивами байтов. Они также являются ПРОСМОТРАМИ базовых байтов и могут быть подкреплены необработанным массивом байтов, а также собственной памятью (вне кучи) или, возможно, даже файлом.
Вот краткий пример использования байтов:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
// Allocate off-heap memory that can be expanded on demand.Bytes bytes = Bytes.allocateElasticDirect();// Write databytes.writeBoolean(true) .writeByte((byte) 1) .writeInt(2) .writeLong(3L) .writeDouble(3.14) .writeUtf8("Foo") .writeUnsignedByte(255);System.out.println("Wrote " + bytes.writePosition() + " bytes");System.out.println(bytes.toHexString()); |
Запуск приведенного выше кода приведет к следующему выводу:
|
1
2
3
|
Wrote 27 bytes00000000 59 01 02 00 00 00 03 00 00 00 00 00 00 00 1f 85 Y······· ········00000010 eb 51 b8 1e 09 40 03 46 6f 6f ff ·Q···@·F oo· |
Мы также можем прочитать данные, как показано ниже:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
// Read databoolean flag = bytes.readBoolean();byte b = bytes.readByte();int i = bytes.readInt();long l = bytes.readLong();double d = bytes.readDouble();String s = bytes.readUtf8();int ub = bytes.readUnsignedByte();System.out.println("d = " + d);bytes.release(); |
Это даст следующий результат:
|
1
|
d = 3.14 |
HexDumpBytes
Байты также предоставляют HexDumpBytes который облегчает документирование вашего протокола.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
// Allocate off-heap memory that can be expanded on demand.Bytes bytes = new HexDumpBytes();// Write databytes.comment("flag").writeBoolean(true) .comment("u8").writeByte((byte) 1) .comment("s32").writeInt(2) .comment("s64").writeLong(3L) .comment("f64").writeDouble(3.14) .comment("text").writeUtf8("Foo") .comment("u8").writeUnsignedByte(255);System.out.println(bytes.toHexString()); |
Это даст следующий результат:
|
1
2
3
4
5
6
7
|
59 # flag01 # u802 00 00 00 # s3203 00 00 00 00 00 00 00 # s641f 85 eb 51 b8 1e 09 40 # f6403 46 6f 6f # textff # u8 |
Резюме
Как можно видеть, легко записывать и читать различные форматы данных, а байты поддерживают отдельные позиции записи и чтения, что делает его еще более простым в использовании (не нужно «переворачивать»
Buffer ). Приведенные выше примеры иллюстрируют «потоковые операции», в которых выполняются последовательные операции записи / чтения. Есть также «абсолютные операции», которые предоставляют нам произвольный доступ в пределах области памяти байтов.
Еще одна полезная особенность байтов заключается в том, что он может быть «эластичным» в том смысле, что его резервная память расширяется динамически и автоматически, если мы записываем больше данных, чем было выделено изначально. Это похоже на
ArrayList с начальным размером, который расширяется по мере добавления дополнительных элементов.
сравнение
Вот краткая таблица некоторых свойств, которые отличают
Bytes из ByteBuffer :
| ByteBuffer | Б | |
| Максимальный размер [байты] | 2 ^ 31 | 2 ^ 63 |
| Отдельная позиция для чтения и записи | нет | да |
| Эластичные буферы | нет | да |
| Атомные операции (CAS) | нет | да |
| Детерминированный выпуск ресурсов | Внутренний API (Очиститель) | да |
| Возможность обойти начальный обнуление | нет | да |
| Чтение / запись строк | нет | да |
| Порядок байтов | Большой и Маленький | Только родной |
| Стоп Бит сжатия | нет | да |
| Сериализация объектов | нет | да |
| Поддержка RPC сериализации | нет | да |
Как мне установить его?
Когда мы хотим использовать байты в нашем проекте, мы просто добавляем следующую зависимость Maven в наш файл pom.xml, и у нас есть доступ к библиотеке.
|
1
2
3
4
5
|
<dependency> <groupId>net.openhft</groupId> <artifactId>chronicle-bytes</artifactId> <version>2.17.27</version></dependency> |
Если вы используете другой инструмент сборки, например Gradle, вы можете увидеть, как зависеть от байтов, нажав на эту ссылку .
Получение байтовых объектов
Объект Bytes может быть получен многими способами, включая обертку существующего ByteBuffer. Вот некоторые примеры:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
// Allocate Bytes using off-heap direct memory// whereby the capacity is fixed (not elastic)Bytes bytes = Bytes.allocateDirect(8);// Allocate a ByteBuffer somehow, e.g. by calling// ByteBuffer's static methods or by mapping a fileByteBuffer bb = ByteBuffer.allocate(16);//// Create Bytes using the provided ByteBuffer// as backing memory with a fixed capacity.Bytes bytes = Bytes.wrapForWrite(bb);// Create a byte arraybyte[] ba = new byte[16];//// Create Bytes using the provided byte array// as backing memory with fixed capacity.Bytes bytes = Bytes.wrapForWrite(ba);// Allocate Bytes which wraps an on-heap ByteBufferBytes bytes = Bytes.elasticHeapByteBuffer(8);// Acquire the current underlying ByteBufferByteBuffer bb = bytes.underlyingObject();// Allocate Bytes which wraps an off-heap direct ByteBufferBytes bytes = Bytes.elasticByteBuffer(8);// Acquire the current underlying ByteBufferByteBuffer bb = bytes.underlyingObject();// Allocate Bytes using off-heap direct memoryBytes bytes = Bytes.allocateElasticDirect(8);// Acquire the address of the first byte in underlying memory// (expert use only)long address = bytes.addressForRead(0);// Allocate Bytes using off-heap direct memory// but only allocate underlying memory on demand.Bytes bytes = Bytes.allocateElasticDirect(); |
Освобождение байтов
С ByteBuffer мы обычно не имеем никакого контроля над тем, когда основная память фактически возвращается обратно в операционную систему или кучу. Это может быть проблематично, когда мы выделяем большие объемы памяти и когда фактические объекты ByteBuffer как таковые не являются сборщиком мусора.
Вот как проблема может проявиться: даже если
ByteBuffer объекты ByteBuffer малы, они могут содержать ByteBuffer ресурсы в основной памяти. Только когда ByteBuffers собирает мусор, возвращается основная память. Таким образом, мы можем оказаться в ситуации, когда у нас в куче небольшое количество объектов (скажем, у нас есть 10 байтовых буферов по 1 ГБ каждый). JVM не находит причин для запуска сборщика мусора с несколькими объектами в куче. Таким образом, у нас достаточно кучи памяти, но в любом случае может не хватить памяти процесса.
Байты предоставляют детерминистские средства быстрого высвобождения базовых ресурсов, как показано в этом примере ниже:
|
1
2
3
4
5
6
|
Bytes bytes = Bytes.allocateElasticDirect(8);try { doStuff(bytes);} finally { bytes.release();} |
Это обеспечит высвобождение основных ресурсов памяти сразу после использования.
Если вы забудете вызвать release() , Байты по-прежнему будут освобождать базовые ресурсы, когда сборка мусора происходит точно так же, как ByteBuffer , но вы можете ByteBuffer память, ожидая, что это произойдет.
Запись данных
Запись данных может быть выполнена двумя основными способами с использованием любого из них:
- Потоковые операции
- Абсолютные операции
Потоковые операции
Потоковые операции выполняются как последовательность операций, каждая из которых последовательно размещает свое содержимое в основной памяти. Это очень похоже на обычный последовательный файл, который увеличивается с нулевой длины и выше, когда содержимое записывается в файл.
|
1
2
3
4
|
// Write in sequential orderbytes.writeBoolean(true) .writeByte((byte) 1) .writeInt(2) |
Абсолютные Операции
Абсолютные операции могут осуществлять доступ к любой части базовой памяти способом произвольного доступа, очень похожим на файл произвольного доступа, где содержимое может быть записано в любом месте в любое время.
|
1
2
3
4
|
// Write in any orderbytes.writeInt(2, 2) .writeBoolean(0, true) .writeByte(1, (byte) 1); |
Вызов операций абсолютной записи не влияет на позицию записи, используемую для потоковых операций.
Чтение данных
Чтение данных также может выполняться с использованием потоковых или абсолютных операций.
Потоковые операции
Аналогично записи, вот так выглядит потоковое чтение:
|
1
2
3
|
boolean flag = bytes.readBoolean();byte b = bytes.readByte();int i = bytes.readInt(); |
Абсолютные Операции
Как и в случае абсолютного письма, мы можем читать с произвольных позиций:
|
1
2
3
|
int i = bytes.readInt(2);boolean flag = bytes.readBoolean(0);byte b = bytes.readByte(1); |
Вызов операций абсолютного чтения не влияет на позицию чтения, используемую для потоковых операций.
Разнообразный
Байты поддерживают написание строк, чего не делает ByteBuffer:
|
1
|
bytes.writeUtf8("The Rain in Spain stays mainly in the plain"); |
Есть также методы для атомарных операций:
|
1
|
bytes.compareAndSwapInt(16, 0, 1); |
Это будет атомарно устанавливать значение int в позиции 16 в 1, если и только если оно равно 0. Это обеспечивает поточно-ориентированные конструкции, которые будут сделаны с использованием байтов. ByteBuffer не может предоставить такие инструменты.
Бенчмаркинг
Как быстро это байты? Ну, как всегда, ваш пробег может варьироваться в зависимости от множества факторов. Давайте сравним ByteBuffer и Bytes которых мы выделяем область памяти, выполняем некоторые общие операции с ней и измеряем производительность с помощью JMH (код инициализации не показан для краткости):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
|
@Benchmarkpublic void serializeByteBuffer() { byteBuffer.position(0); byteBuffer.putInt(POINT.x()).putInt(POINT.y());}@Benchmarkpublic void serializeBytes() { bytes.writePosition(0); bytes.writeInt(POINT.x()).writeInt(POINT.y());}@Benchmarkpublic boolean equalsByteBuffer() { return byteBuffer1.equals(byteBuffer2);}@Benchmarkpublic boolean equalsBytes() { return bytes1.equals(bytes2);} |
Это дало следующий результат:
|
1
2
3
4
5
|
Benchmark Mode Cnt Score Error UnitsBenchmarking.equalsByteBuffer thrpt 3 3838611.249 ± 11052050.262 ops/sBenchmarking.equalsBytes thrpt 3 13815958.787 ± 579940.844 ops/sBenchmarking.serializeByteBuffer thrpt 3 29278828.739 ± 11117877.437 ops/sBenchmarking.serializeBytes thrpt 3 42309429.465 ± 9784674.787 ops/s |
Вот диаграмма различных тестов, показывающих относительную производительность (чем выше, тем лучше):
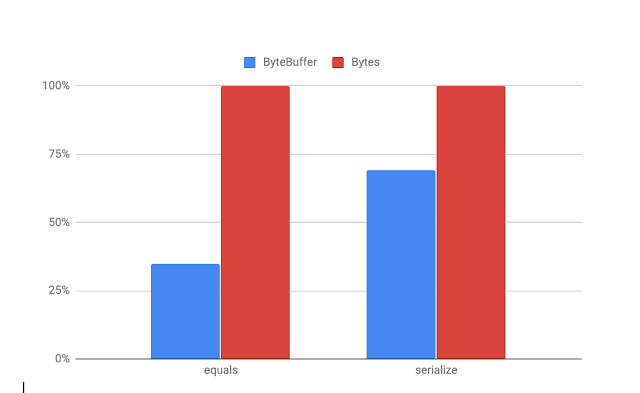
Bytes производительности лучше, чем ByteBuffer для запуска тестов.
Вообще говоря, имеет смысл повторно использовать прямые буферы вне кучи, поскольку их размещение относительно дорого. Повторное использование может быть сделано разными способами, включая переменные ThreadLocal и пул. Это верно для обоих
Bytes и ByteBuffer .
Тесты проводились на Mac Book Pro (середина 2015 года, 2,2 ГГц Intel Core i7, 16 ГБ) и на Java 8 с использованием всех доступных потоков. Следует отметить, что вы должны запустить свои собственные тесты, если вы хотите соответствующее сравнение, относящееся к конкретной проблеме.
API и потоковые вызовы RPC
Легко настроить всю структуру с удаленными вызовами процедур (RPC) и API, используя байты, которые поддерживают запись и воспроизведение событий. Вот короткий пример, где MyPerson является POJO, который реализует интерфейс BytesMarshable . Нам не нужно реализовывать какие-либо методы в BytesMarshallable поскольку он поставляется с реализациями по умолчанию.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
public final class MyPerson implements BytesMarshallable { private String name; private byte type; private double balance; public MyPerson(){} // Getters and setters not shown for brevity}interface MyApi { @MethodId(0x81L) void myPerson(MyPerson byteable);}static void serialize() { MyPerson myPerson = new MyPerson(); myPerson.setName("John"); yPerson.setType((byte) 7); myPerson.setBalance(123.5); HexDumpBytes bytes = new HexDumpBytes(); MyApi myApi = bytes.bytesMethodWriter(MyApi.class); myApi.myPerson(myPerson); System.out.println(bytes.toHexString());} |
Вызов serialize() выдаст следующий вывод:
|
1
2
3
4
|
81 01 # myPerson 04 4a 6f 68 6e # name 07 # type 00 00 00 00 00 e0 5e 40 # balance |
Как видно, очень легко увидеть, как составляются сообщения.
Байт с файловой поддержкой
Очень просто создать байты с отображением файлов, которые растут по мере добавления большего количества данных, как показано ниже:
|
1
2
3
4
5
6
7
|
try { MappedBytes mb = MappedBytes.mappedBytes(new File("mapped_file"), 1024); mb.appendUtf8("John") .append(4.3f);} catch (FileNotFoundException fnfe) { fnfe.printStackTrace();} |
Это создаст файл отображения памяти с именем «mapped_file».
|
1
2
3
4
5
|
$ hexdump mapped_file 0000000 4a 6f 68 6e 34 2e 33 00 00 00 00 00 00 00 00 000000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00*0001400 |
Лицензирование и зависимости
Bytes имеет открытый исходный код и лицензируется под дружественную для бизнеса лицензию Apache 2, что позволяет легко включать его в ваши собственные проекты, будь то коммерческие или нет.
Байты имеют три зависимости времени выполнения: chronicle-core , slf4j-api и
com.intellij:annotations которые, в свою очередь, лицензируются в соответствии с Apache 2, MIT и Apache 2.
Ресурсы
Хроника байтов: https://github.com/OpenHFT/Chronicle-Bytes
Библиотека Bytes предоставляет много интересных функций и обеспечивает хорошую производительность.
|
Смотреть оригинальную статью здесь: Java: Хроники байтов, пинать шины Мнения, высказанные участниками Java Code Geeks, являются их собственными. |