Почему производственные журналы не могут помочь вам найти истинную причину ваших ошибок?
Спрашивать, используете ли вы файлы журналов для мониторинга своего приложения, почти все равно, что спрашивать … пьете ли вы воду. Мы все используем логи, но КАК мы их используем — это совсем другой вопрос.
В следующем посте мы более подробно рассмотрим журналы и посмотрим, как они используются и что им написано. Поехали.
Большое спасибо Авиву Данцигеру (Aviv Danziger) из нашей команды по исследованиям и разработкам за огромную помощь в получении и обработке данных для нас.
Основы
Наш поиск ответов требует большого количества данных, и поэтому мы обратились к Google BigQuery. Несколько месяцев назад мы впервые использовали его, чтобы увидеть, как ведущие Java-проекты GitHub используют журналы .
Для нашего текущего поста мы взяли 400 000 лучших репозиториев Java на GitHub, ранжированных по количеству звезд, которые они получили в 2016 году. Из этих репозиториев мы отфильтровали Android, примеры проектов и простые тестеры, в результате чего у нас осталось 15 797 репозиториев.
Затем мы извлекли репозитории, в которых было более 100 операторов регистрации, что позволило нам работать с 1463 репозиториями. Теперь самое время найти ответы на все те вопросы, которые не давали нам спать по ночам.
TL; DR: основные блюда на вынос
Если вам не нравятся круговые, столбчатые или гистограммы, и вы хотите пропустить основное блюдо и отправиться прямо к десерту, вот пять ключевых моментов, которые мы узнали о регистрации и как она на самом деле делается:
1. В журналах на самом деле не так много информации, как мы думаем, хотя они могут составлять до сотен гигабайт в день. Более 50% заявлений не имеют информации о состоянии переменной приложения
2. В производственном процессе 64% общих отчетов о регистрации отключены
3. Операторы журналирования, которые достигают производства, имеют на 35% меньше переменных, чем оператор журналирования среднего уровня развития
4. «Этого никогда не должно быть» всегда происходит
5. Есть лучший способ устранения ошибок в производстве
Теперь давайте подкрепим эти пункты некоторыми данными.
1. Сколько операторов логирования фактически содержит переменные?
Первое, что мы хотели проверить, это то, сколько переменных отправляется в каждом операторе. Мы выбрали срезать данные по шкале от 0 переменных до 5 и выше в каждом хранилище. Затем мы взяли общее количество и получили представление о средней разбивке по всем проектам в исследовании.
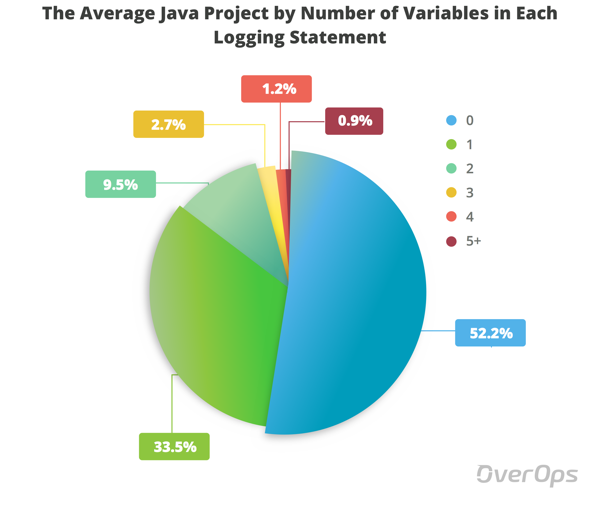
Средний Java-проект по количеству переменных
Как вы можете видеть, средний Java-проект не регистрирует никаких переменных в более чем 50% своих операторов логирования. Мы также видим, что только 0,95% операторов логирования отправляют 5 или более переменных.
Это означает, что существует ограниченная информация о приложении, которое фиксируется в журнале, и выяснение того, что на самом деле произошло, может выглядеть как поиск иглы в файле журнала.
2. Сколько записей в журнале активируется в производстве?
Среды разработки и производства различаются по многим причинам, одной из которых является их отношение к ведению журнала. В разработке все уровни журнала активированы. Однако в производстве активируются только ОШИБКА и ПРЕДУПРЕЖДЕНИЕ. Посмотрим, как выглядит эта разбивка.
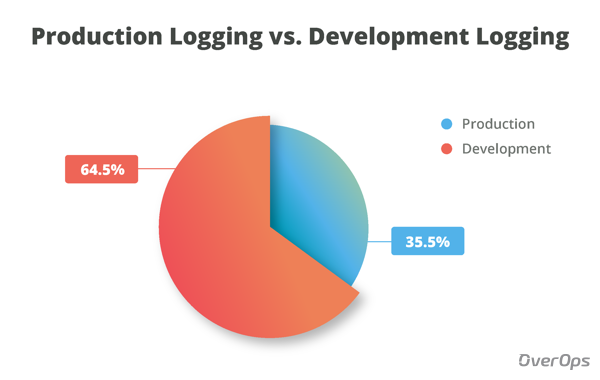
Производство против разработки
Диаграмма показывает, что среднее Java-приложение имеет 35,5% уникальных операторов ведения журналов, которые могут быть активированы в производственной среде (ERROR, WARN), и 64,5% операторов, которые активируются только в разработке (TRACE, INFO, DEBUG).
Большая часть информации потеряна. Уч.
3. Каково среднее количество переменных на каждом уровне журнала?
Таким образом, разработчики не только экономят на переменных в своих операторах, но и на среднем Java-приложении не отправляют так много операторов в рабочие журналы.
Теперь мы решили рассмотреть каждый уровень журнала отдельно и вычислить среднее количество переменных в соответствующих выражениях.
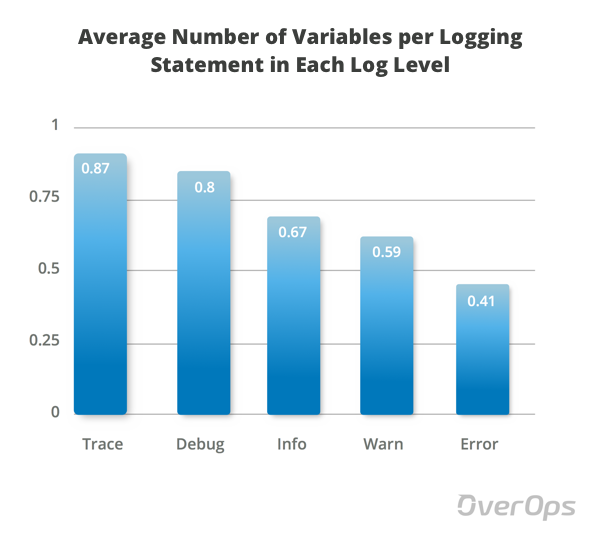
Среднее количество переменных в отчете о регистрации
Среднее значение показывает, что операторы TRACE, DEBUG и INFO содержат больше переменных, чем WARN и ERROR. «Еще» — вежливое слово, учитывая, что среднее число переменных в первых трех — 0,78, а в последних 2 — 0,5.
Это означает, что операторы ведения журнала производства содержат на 35% меньше переменных, чем операторы ведения журнала разработки. Кроме того, как мы видели ранее, их общее количество также намного ниже.
Если вы ищете в журнале подсказки о том, что случилось с вашим приложением, но не нашли нужного результата — вот почему это происходит. Не волнуйтесь, есть лучший способ.
OverOps позволяет вам видеть переменные, стоящие за любым исключением, зарегистрированной ошибкой или предупреждением, не полагаясь на информацию, которая была фактически зарегистрирована. Вы сможете увидеть полный исходный код и состояние переменной по всему стеку вызовов события. Даже если это не было напечатано в файл журнала. OverOps также показывает вам 250 операторов уровня DEBUG, TRACE и INFO, которые были зарегистрированы до ошибки в работе, даже если они отключены и никогда не достигают файла журнала.
Мы будем рады показать вам, как это работает, нажмите здесь, чтобы запланировать демонстрацию .
4. Это никогда не должно случиться
Поскольку у нас уже есть информация обо всех этих операторах, мы решили немного повеселиться. Мы нашли 58 упоминаний «Этого никогда не должно случиться».
Все, что мы можем сказать, это то, что, если это никогда не произойдет, хотя бы прилично распечатайте переменную или 2, так что вы все равно сможете понять, почему это произошло & # 55357; & # 56898;
Как мы это сделали?
Как мы уже упоминали, чтобы получить эти данные, мы сначала должны были отфильтровать нерелевантные репозитории Java и сосредоточиться на тех, у которых было более 100 операторов журналирования, что оставило нам 1463 репо, которые сделали разрез.
Затем мы добавили магию регулярных выражений и вытащили все строки журнала:
|
1
2
3
4
5
|
SELECT * FROM [java-log-levels-usage:java_log_level_usage.top_repos_java_contents_lines_no_android_no_arduino] WHERE REGEXP_MATCH(line, r'.*((LOGGER|Logger|logger|LOG|Log|log)[.](trace|info|debug|warn|warning|error|fatal|severe|config|fine|finer|finest)).*') OR REGEXP_MATCH(line, r'.*((Level|Priority)[.](TRACE|TRACE_INT|X_TRACE_INT|INFO|INFO_INT|DEBUG|DEBUG_INT|WARN|WARN_INT|WARNING|WARNING_INT|ERROR|ERROR_INT)).*') OR REGEXP_MATCH(line, r'.*((Level|Priority)[.](FATAL|FATAL_INT|SEVERE|SEVERE_INT|CONFIG|CONFIG_INT|FINE|FINE_INT|FINER|FINER_INT|FINEST|FINEST_INT|ALL|OFF)).*') |
Теперь, когда у нас были данные, мы начали их разбирать. Сначала мы отфильтровали количество переменных на уровне журнала:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
SELECT sample_repo_name ,log_level ,CASE WHEN parametersCount + concatenationCount = 0 THEN "0" WHEN parametersCount + concatenationCount = 1 THEN "1" WHEN parametersCount + concatenationCount = 2 THEN "2" WHEN parametersCount + concatenationCount = 3 THEN "3" WHEN parametersCount + concatenationCount = 4 THEN "4" WHEN parametersCount + concatenationCount >= 5 THEN "5+" END total_params_tier ,SUM(parametersCount + concatenationCount) total_params ,SUM(CASE WHEN parametersCount > 0 THEN 1 ELSE 0 END) has_parameters ,SUM(CASE WHEN concatenationCount > 0 THEN 1 ELSE 0 END) has_concatenation ,SUM(CASE WHEN parametersCount = 0 AND concatenationCount = 0 THEN 1 ELSE 0 END) has_none ,SUM(CASE WHEN parametersCount > 0 AND concatenationCount > 0 THEN 1 ELSE 0 END) has_both ,COUNT(1) logging_statements ,SUM(parametersCount) parameters_count ,SUM(concatenationCount) concatenation_count ,SUM(CASE WHEN isComment = true THEN 1 ELSE 0 END) comment_count ,SUM(CASE WHEN shouldNeverHappen = true THEN 1 ELSE 0 END) should_never_happen_count FROM [java-log-levels-usage:java_log_level_usage.top_repos_java_log_lines_no_android_no_arduino_attributes] GROUP BY sample_repo_name ,log_level ,total_params_tier |
Затем рассчитывается среднее использование каждого уровня. Вот как мы получили средний процент от общего количества заявлений о репозиториях.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
SELECT total_params_tier ,AVG(logging_statements / total_repo_logging_statements) percent_out_of_total_repo_statements ,SUM(total_params) total_params ,SUM(logging_statements) logging_statements ,SUM(has_parameters) has_parameters ,SUM(has_concatenation) has_concatenation ,SUM(has_none) has_none ,SUM(has_both) has_both ,SUM(parameters_count) parameters_count ,SUM(concatenation_count) concatenation_count ,SUM(comment_count) comment_count ,SUM(should_never_happen_count) should_never_happen_count FROM (SELECT sample_repo_name ,total_params_tier ,SUM(total_params) total_params ,SUM(logging_statements) logging_statements ,SUM(logging_statements) OVER (PARTITION BY sample_repo_name) total_repo_logging_statements ,SUM(has_parameters) has_parameters ,SUM(has_concatenation) has_concatenation ,SUM(has_none) has_none ,SUM(has_both) has_both ,SUM(parameters_count) parameters_count ,SUM(concatenation_count) concatenation_count ,SUM(comment_count) comment_count ,SUM(should_never_happen_count) should_never_happen_count FROM [java-log-levels-usage:java_log_level_usage.top_repos_java_log_lines_no_android_no_arduino_attributes_counters_with_params_count] GROUP BY sample_repo_name ,total_params_tier) WHERE total_repo_logging_statements >= 100 GROUP BY total_params_tier ORDER BY 1,2 |
Вы можете проверить расчеты в нашем файле необработанных данных .
Последние мысли
Мы все используем файлы журналов, но большинство из нас воспринимает их как должное. Благодаря многочисленным инструментам управления журналами мы забываем взять под контроль наш собственный код и сделать его понятным для нас, отладки и исправления.
| Ссылка: | Исследование GitHub: более 50% заявлений о ведении журнала Java написаны неверно от нашего партнера JCG Хенна Идана в блоге OverOps . |