и превратить его в серию графиков, которые выглядят так:
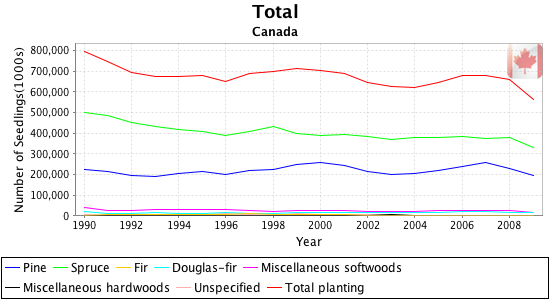
Недавно я искал возможность попрактиковаться с JFreeChart и в итоге посмотрел на набор данных, выпущенный канадским правительством в рамках их инициативы «Открытые данные» .
Конкретный набор данных называется «Количество саженцев, посаженных по формам собственности, видам» и поставляется в виде электронной таблицы Excel, поэтому для чтения данных необходима библиотека Apache POI . Как обычно, по крайней мере, в моем случае Как показывает опыт, электронная таблица Excel предназначена главным образом для потребления человеком, что повышает сложность анализа. К счастью, электронная таблица следует повторяющейся схеме, которую можно довольно легко объяснить, так что это не является непреодолимым. Тем не менее, мы хотим получить данные из Excel, чтобы сделать их более доступными для машинного потребления, поэтому первым шагом является преобразование их в представление JSON. Как только он окажется в этой гораздо более транспортабельной форме, мы сможем легко преобразовать данные в визуализации графа, используя JFreeChart.
Формат электронной таблицы
Excel как инструмент на рабочем месте очень хорошо зарекомендовал себя, может повысить индивидуальную производительность и, безусловно, является благом для среднего офисного работника. Проблема в том, что когда данные есть, они часто попадают в ловушку. Данные обычно располагаются на основе эстетики человека, а не парсинга, а это означает, что если вы не хотите использовать Excel для дальнейшего анализа, вариантов не так много. Экспорт в более нейтральные форматы, такие как csv, страдает от тех же проблем, а именно из-за того, что невозможно согласованно считывать данные без разработки собственного анализатора. В этом конкретном случае при разборе таблицы необходимо учитывать следующее:
- Объединенные ячейки, где один столбец предназначен для представления фиксированного значения для ряда последовательных строк.
- Заголовки столбцов, которые не представляют все фактические столбцы. Здесь у нас есть столбец «заметки» для каждой провинции, который следует сразу же за «столбцом данных». Поскольку ячейки заголовка объединены в обоих столбцах, их нельзя использовать непосредственно для анализа данных.
- Данные разбиты на несколько доменов, что приводит к повторениям в формате.
- Данные содержат набор чисел, где результаты доступны, и текст, где их нет. Значения текстовых записей описаны в таблице в конце электронной таблицы.
- Заголовки и заголовки разделов повторяются по всему документу, по-видимому, пытаясь соответствовать некоторому макету печати или, возможно, просто пытаясь помочь тем, кто просматривает длинный документ.
Данные в электронной таблице сначала делятся на отчеты по провинциальным коронам, частным землям, федеральным землям и, наконец, по всем из них.
В рамках каждого из этих разделов данные представляются для каждого вида деревьев на ежегодной основе по всем провинциям и территориям вместе с совокупными итогами этих цифр по всей Канаде.
Таблицы данных каждого из этих видов имеют идентичную структуру строк / столбцов, что позволяет нам создать единую структуру синтаксического анализа, достаточную для считывания данных из каждого из них в отдельности.
Преобразование электронной таблицы в JSON
Для анализа документа Excel я использую библиотеку Apache POI и класс-оболочку Groovy, чтобы помочь в обработке. Класс-обёртка очень прост, но позволяет абстрагироваться от большинства механизмов работы с документом Excel. Полный источник доступен в этом сообщении в блоге от автора Горана Эрссона . Основным преимуществом является возможность указать окно файла для обработки на основе параметров ‘offset’ и ‘max’, представленных в простой карте. Вот пример для чтения данных для таблицы текстовых символов в конце электронной таблицы.
Мы определяем карту, в которой указывается, с какого листа читать, с какой строки начинать (смещение) и сколько строк обрабатывать. Класс ExcelBuilder (который на самом деле вообще не является компоновщиком) берет путь к объекту File и под капотом считывает его в POI HSSFWorkbook, на который затем ссылается вызов метода eachLine .
|
1
2
3
4
5
6
7
|
public static final Map SYMBOLS = [sheet: SHEET1, offset: 910, max: 8]... final ExcelBuilder excelReader = new ExcelBuilder(data.absolutePath) Map<String, String> symbolTable = [:] excelReader.eachLine(SYMBOLS) { HSSFRow row -> symbolTable[row.getCell(0).stringCellValue] = row.getCell(1).stringCellValue } |
В конце концов, когда мы превратим это в JSON, это будет выглядеть так:
|
01
02
03
04
05
06
07
08
09
10
|
'Symbols': { '...': 'Figures not appropriate or not applicable', '..': 'Figures not available', '--': 'Amount too small to be expressed', '-': 'Nil or zero', 'p': 'Preliminary figures', 'r': 'Revised figures', 'e': 'Estimated by provincial or territorial forestry agency', 'E': 'Estimated by the Canadian Forest Service or by Statistics Canada'} |
Теперь обработка других блоков данных становится немного сложнее. Первый столбец состоит из 2 объединенных ячеек, и все, кроме одного из других заголовков, фактически представляют два столбца информации: счетчик и необязательное обозначение. Объединенный столбец обрабатывается простым заполнителем EMPTY и дополнительными столбцами путем обработки списка заголовков;
|
01
02
03
04
05
06
07
08
09
10
11
|
public static final List<String> HEADERS = ['Species', 'EMPTY', 'Year', 'NL', 'PE', 'NS', 'NB', 'QC', 'ON', 'MB', 'SK', 'AB', 'BC', 'YT', 'NT *a', 'NU', 'CA']/*** For each header add a second following header for a 'notes' column* @param strings* @return expanded list of headers*/private List<String> expandHeaders(List<String> strings){ strings.collect {[it, '${it}_notes']}.flatten()} |
Каждый блок данных соответствует определенному виду деревьев с разбивкой по годам и провинциям или территориям. Каждый вид представлен картой, которая определяет, где в документе содержится эта информация, поэтому мы можем легко перебирать коллекцию этих карт и собирать данные. Этот набор констант и кода достаточен для анализа всех данных в документе.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
public static final int HEADER_OFFSET = 3public static final int YEARS = 21public static final Map PINE = [sheet: SHEET1, offset: 6, max: YEARS, species: 'Pine']public static final Map SPRUCE = [sheet: SHEET1, offset: 29, max: YEARS, species: 'Spruce']public static final Map FIR = [sheet: SHEET1, offset: 61, max: YEARS, species: 'Fir']public static final Map DOUGLAS_FIR = [sheet: SHEET1, offset: 84, max: YEARS, species: 'Douglas-fir']public static final Map MISCELLANEOUS_SOFTWOODS = [sheet: SHEET1, offset: 116, max: YEARS, species: 'Miscellaneous softwoods']public static final Map MISCELLANEOUS_HARDWOODS = [sheet: SHEET1, offset: 139, max: YEARS, species: 'Miscellaneous hardwoods']public static final Map UNSPECIFIED = [sheet: SHEET1, offset: 171, max: YEARS, species: 'Unspecified']public static final Map TOTAL_PLANTING = [sheet: SHEET1, offset: 194, max: YEARS, species: 'Total planting']public static final List<Map> PROVINCIAL = [PINE, SPRUCE, FIR, DOUGLAS_FIR, MISCELLANEOUS_SOFTWOODS, MISCELLANEOUS_HARDWOODS, UNSPECIFIED, TOTAL_PLANTING]public static final List<String> AREAS = HEADERS[HEADER_OFFSET..-1]...final Closure collector = { Map species -> Map speciesMap = [name: species.species] excelReader.eachLine(species) {HSSFRow row -> //ensure that we are reading from the correct place in the file if (row.rowNum == species.offset) { assert row.getCell(0).stringCellValue == species.species } //process rows if (row.rowNum > species.offset) { final int year = row.getCell(HEADERS.indexOf('Year')).stringCellValue as int Map yearMap = [:] expandHeaders(AREAS).eachWithIndex {String header, int index -> final HSSFCell cell = row.getCell(index + HEADER_OFFSET) yearMap[header] = cell.cellType == HSSFCell.CELL_TYPE_STRING ? cell.stringCellValue : cell.numericCellValue } speciesMap[year] = yearMap.asImmutable() } } speciesMap.asImmutable()} |
Определенный коллектор Closure возвращает карту данных всех видов для одной из четырех группировок (провинциальные, частные, федеральные и итоговые). Единственное, что отличает эти группы, это их смещение в файле, поэтому мы можем определить карты для структуры каждой из них, просто обновив смещения первой.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
public static final List<Map> PROVINCIAL = [PINE, SPRUCE, FIR, DOUGLAS_FIR, MISCELLANEOUS_SOFTWOODS, MISCELLANEOUS_HARDWOODS, UNSPECIFIED, TOTAL_PLANTING]public static final List<Map> PRIVATE_LAND = offset(PROVINCIAL, 220)public static final List<Map> FEDERAL = offset(PROVINCIAL, 441)public static final List<Map> TOTAL = offset(PROVINCIAL, 662)private static List<Map> offset(List<Map> maps, int offset){ maps.collect { Map map -> Map offsetMap = new LinkedHashMap(map) offsetMap.offset = offsetMap.offset + offset offsetMap }} |
Наконец, мы можем перебрать эти простые структуры карт, применяя коллектор Closure, и в итоге мы получаем одну карту, представляющую все данные.
|
1
2
3
4
5
6
7
8
|
def parsedSpreadsheet = [PROVINCIAL, PRIVATE_LAND, FEDERAL, TOTAL].collect { it.collect(collector)}Map resultsMap = [:]GROUPINGS.eachWithIndex {String groupName, int index -> resultsMap[groupName] = parsedSpreadsheet[index]}resultsMap['Symbols'] = symbolTable |
А класс JsonBuilder предоставляет простой способ конвертировать любую карту в документ JSON, готовый для записи результатов.
|
1
2
3
4
|
Map map = new NaturalResourcesCanadaExcelParser().convertToMap(data)new File('src/test/resources/NaturalResourcesCanadaNewSeedlings.json').withWriter {Writer writer -> writer << new JsonBuilder(map).toPrettyString()} |
Разбор JSON в линейные графики JFreeChart
Хорошо, теперь, когда мы превратили данные в немного более удобный формат, пришло время их визуализировать. Для этого случая я использую комбинацию библиотеки JFreeChart и проекта GroovyChart, который обеспечивает хороший синтаксис DSL для работы с JFreeChart API. В настоящее время он не находится в стадии разработки, но, за исключением того факта, что файл jar не был опубликован в доступном хранилище, он полностью соответствовал этой задаче.
Мы собираемся создать четыре диаграммы для каждой из четырнадцати областей, представленных в общей сложности для 56 графиков. Все эти графики содержат сюжетные линии для каждого из восьми отслеживаемых видов деревьев. Это означает, что в целом нам нужно создать 448 различных временных рядов. Я не делал каких-либо формальных временных интервалов для определения того, сколько времени это займет, но в целом это заняло менее десяти секунд, чтобы сгенерировать все это. Просто для забавы, я добавил GPars в смесь, чтобы распараллелить создание диаграмм, но поскольку запись изображений на диск будет самой дорогой частью этого процесса, я не думаю, что это сильно ускоряет процесс.
Во-первых, чтение данных JSON из файла просто с помощью JsonSlurper.
|
1
2
3
4
5
|
def datanew File(jsonFilename).withReader {Reader reader -> data = new JsonSlurper().parse(reader)}assert data |
Вот пример того, как выглядят данные JSON для одного вида за один год, разбитые сначала по одной из четырех основных групп, затем по видам деревьев, затем по годам и, наконец, по провинции или территории.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
{ 'Provincial': [ { 'name': 'Pine', '1990': { 'NL': 583.0, 'NL_notes': '', 'PE': 52.0, 'PE_notes': '', 'NS': 4.0, 'NS_notes': '', 'NB': 4715.0, 'NB_notes': '', 'QC': 33422.0, 'QC_notes': '', 'ON': 51062.0, 'ON_notes': '', 'MB': 2985.0, 'MB_notes': '', 'SK': 4671.0, 'SK_notes': '', 'AB': 8130.0, 'AB_notes': '', 'BC': 89167.0, 'BC_notes': 'e', 'YT': '-', 'YT_notes': '', 'NT *a': 15.0, 'NT *a_notes': '', 'NU': '..', 'NU_notes': '', 'CA': 194806.0, 'CA_notes': 'e' }, ... |
Построение диаграмм — это простая итерация по полученной карте проанализированных данных. В этом случае мы игнорируем данные ‘notes’, но включаем их в набор данных на случай, если мы захотим использовать их позже. Мы также просто игнорируем любые нечисловые значения.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
GROUPINGS.each { group -> withPool { AREAS.eachParallel { area -> ChartBuilder builder = new ChartBuilder(); String title = sanitizeName('$group-$area') TimeseriesChart chart = builder.timeserieschart(title: group, timeAxisLabel: 'Year', valueAxisLabel: 'Number of Seedlings(1000s)', legend: true, tooltips: false, urls: false ) { timeSeriesCollection { data.'$group'.each { species -> Set years = (species.keySet() - 'name').collect {it as int} timeSeries(name: species.name, timePeriodClass: 'org.jfree.data.time.Year') { years.sort().each { year -> final value = species.'$year'.'$area' //check that it's a numeric value if (!(value instanceof String)) { add(period: new Year(year), value: value) } } } } } }...} |
Затем мы применяем дополнительное форматирование к JFreeChart для улучшения стиля вывода, вставляем изображение в фон и исправляем цветовые схемы графика.
|
01
02
03
04
05
06
07
08
09
10
|
JFreeChart innerChart = chart.chartString longName = PROVINCE_SHORT_FORM_MAPPINGS.find {it.value == area}.keyinnerChart.addSubtitle(new TextTitle(longName))innerChart.setBackgroundPaint(Color.white)innerChart.plot.setBackgroundPaint(Color.lightGray.brighter())innerChart.plot.setBackgroundImageAlignment(Align.TOP_RIGHT)innerChart.plot.setBackgroundImage(logo)[Color.BLUE, Color.GREEN, Color.ORANGE, Color.CYAN, Color.MAGENTA, Color.BLACK, Color.PINK, Color.RED].eachWithIndex { color, int index -> innerChart.XYPlot.renderer.setSeriesPaint(index, color)} |
И мы записываем каждый из графиков в png-файл с формульным названием.
|
01
02
03
04
05
06
07
08
09
10
11
12
|
def fileTitle = '$FILE_PREFIX-${title}.png'File outputDir = new File(outputDirectory)if (!outputDir.exists()){ outputDir.mkdirs()}File file = new File(outputDir, fileTitle)if (file.exists()){ file.delete()}ChartUtilities.saveChartAsPNG(file, innerChart, 550, 300) |
Чтобы связать все это вместе, HTML-страница создается с использованием MarkupBuilder для демонстрации всех результатов, упорядоченных по провинции или территории.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
def buildHtml(inputDirectory){ File inputDir = new File(inputDirectory) assert inputDir.exists() Writer writer = new StringWriter() MarkupBuilder builder = new MarkupBuilder(writer) builder.html { head { title('Number of Seedlings Planted by Ownership, Species') style(type: 'text/css') { mkp.yield(CSS) } } body { ul { AREAS.each { area -> String areaName = sanitizeName(area) div(class: 'area rounded-corners', id: areaName) { h2(PROVINCE_SHORT_FORM_MAPPINGS.find {it.value == area}.key) inputDir.eachFileMatch(~/.*$areaName\.png/) { img(src: it.name) } } } } script(type: 'text/javascript', src: 'https://ajax.googleapis.com/ajax/libs/jquery/1.7.1/jquery.min.js', '') script(type: 'text/javascript') { mkp.yield(JQUERY_FUNCTION) } } } writer.toString()} |
Сгенерированная html-страница предполагает, что все изображения находятся в одной папке, представляет четыре изображения на провинцию / территорию и, просто для удовольствия, использует JQuery для прикрепления обработчика щелчков к каждому из заголовков. Нажмите на заголовок, и изображения в этом div будут анимированы в фоновом режиме. Я уверен, что реальный используемый JQuery мог бы быть улучшен, но он служит своей цели. Вот пример вывода html:
|
1
2
3
4
5
6
7
8
9
|
<ul> <div class='area rounded-corners' id='NL'> <h2>Newfoundland and Labrador</h2> <img src='naturalResourcesCanadaNewSeedlings-Federal-NL.png' /> <img src='naturalResourcesCanadaNewSeedlings-PrivateLand-NL.png' /> <img src='naturalResourcesCanadaNewSeedlings-Provincial-NL.png' /> <img src='naturalResourcesCanadaNewSeedlings-Total-NL.png' /> </div> ... |
Полученная страница выглядит так в Firefox.

Исходный код и ссылки
Исходный код доступен на GitHub . Таким образом, это итоговая HTML-страница . Весь исходный код, необходимый для перехода от Excel к диаграммам, встроенным в html-страницу, занимает чуть менее 300 строк кода, и я не думаю, что результаты будут слишком плохими, если потратить пару часов усилий. Наконец, результаты JSON также размещаются на страницах GitHub для проекта для всех, кто захочет вникать в данные.
Некоторые чтения, связанные с этой темой:
- Groovy любит POI и POI любит Groovy
- Написание скриптов пакетного импорта с Grails, GSQL и GPars
- GSheets — Groovy Builder на основе Apache POI
- Groovy для офиса
Ссылки по теме:
- Groovy inspect () / Eval для экстернализации данных
- Groovy обратная карта сортировки сделано легко
- Пять классных вещей, которые вы можете сделать с помощью скриптов Groovy
Ссылка: JFreeChart с Groovy и Apache POI от нашего партнера по JCG Келли Робинсон в блоге The Kaptain на… материале .