Если у вас есть опыт разработки бизнес-приложений, то, скорее всего, вы столкнулись с требованием, чтобы приложение имело гибкий механизм отчетности. Компания, в которой я работаю, в основном занимается разработкой бизнес-решений, и отчетность — это важный элемент, который должен быть во всех разрабатываемых нами корпоративных системах. Чтобы обеспечить гибкую отчетность в наших системах, мы разработали собственный генератор отчетов с открытым исходным кодом (распространяется под лицензией Apache 2.0 ) — YARG (еще один генератор отчетов). Теперь YARG является сердцем отчетности на платформе CUBA, которая сама является основой всех систем, которые мы разрабатываем.
Почему существует необходимость в разработке нового
Прежде всего, позвольте мне отметить, что мы не изобретатели колес. Мы всегда ищем решения для интеграции, если эти решения нам подходят. К сожалению, в этом случае мы не смогли найти инструмент с открытым исходным кодом, который отвечал бы следующим требованиям:
- Создать отчет в формате шаблона и / или преобразовать вывод в PDF
- Избегайте использования внешних инструментов для создания шаблонов отчетов (Microsoft Office или Libreoffice должно быть достаточно)
- Поддержка различных форматов шаблонов: DOC, ODT, XLS, DOCX, XLSX, HTML
- Возможность использовать сложные шаблоны XLS и XLSX с диаграммами, формулами и т. Д.
- Возможность использовать макет HTML и вставлять / вставлять изображения
- Разделить слой данных (структура отчета и выборка данных) и уровень представления (шаблоны отчетов)
- Включить различные методы извлечения данных, такие как SQL, JPQL или Groovy скрипт
- Возможность интеграции с IoC-фреймворками ( Spring , Guice )
- Функциональность использования инструмента в качестве отдельного приложения, чтобы иметь возможность использовать его вне экосистемы Java (например, для создания отчетов с использованием PHP )
- Хранить структуру отчета в прозрачном формате XML
Самым близким инструментом, который мы могли найти, был JasperReports , но было несколько блокировщиков, которые мешали нам его использовать:
- Бесплатная версия не может генерировать отчеты DOC (была коммерческая библиотека, которая обеспечивала эту функциональность)
- Отчеты XLS были очень ограничены, и было невозможно использовать диаграммы, формулы и форматирование ячеек.
- Для создания отчета необходимо иметь определенный набор навыков и знание того, как использовать очень специфические инструменты (например, iReports )
- Нет четкого разделения между уровнями данных и представления
Конечно, мы исследовали множество других различных инструментов, но все остальные библиотеки, которые мы нашли, были ориентированы на какой-то определенный формат. Мы хотели иметь панацею для отчетности — один инструмент для всех видов отчетов.
Принимая во внимание все пункты и мысли, перечисленные выше, мы решили разработать другой, но сделанный на заказ инструмент для генерации отчетов.
Что под капотом
Когда мы запустили YARG, было не проблема найти библиотеку для интеграции XLS ( POI-HSSF , JXLS и т. Д.). Мы решили использовать Apache POI как самую популярную и хорошо поддерживаемую библиотеку.
Ситуация вокруг интеграции DOC была полностью противоположной. Лишь очень немногие варианты были доступны на рынке с открытым исходным кодом ( POI-HWPF , COM и UNO Runtime ). Библиотека POI-HWPF была очень ограничена по ряду причин, и мы не рассматривали ее как подходящий вариант. Нам пришлось выбирать между COM и UNO Runtime, что в буквальном смысле является API для интеграции на стороне сервера OpenOffice.
Итак, после глубокого изучения мы решили выбрать UNO Runtime , в основном из-за положительных отзывов от людей, которые успешно использовали его для систем, написанных на совершенно разных языках, таких как Python, Ruby, C # и т . Д.
Хотя использование POI-HSSF было довольно простым (кроме диаграмм), мы столкнулись с рядом проблем, связанных с интегрированием среды выполнения UNO :
- Нет четкого API для работы с таблицами
- Каждый раз, когда создается отчет, запускается OpenOffice. Первоначально мы использовали bootstrapconnector для управления процессами OpenOffice, но позже выяснилось, что во многих случаях он не убивает процесс после генерации отчета. Таким образом, нам пришлось заново реализовать логику запуска и завершения OpenOffice (спасибо разработчикам jodconverter , которые высказали много хороших идей по этому вопросу)
- Кроме того, UNO Runtime (и сам OpenOffice Server) имеют значительные проблемы с безопасностью потоков, и это может привести к зависанию или прекращению работы сервера в случае возникновения внутренней ошибки. Чтобы преодолеть это, мы должны были реализовать механизм перезапуска отчетов в случае сбоя сервера, что явно сказывается на производительности.
Позже, когда библиотека DOCX4J стала очень зрелой и популярной, мы поддержали XLSX / DOCX. Основное преимущество библиотеки DOCX4J заключается в том, что она обеспечивает необходимый низкоуровневый доступ к структуре документа (в основном вы работаете с XML). Еще одно преимущество использования DOCX4J заключается в том, что для генерации отчетов DOCX не требуется интеграция с сервером OpenOffice.
Также есть возможность использовать документ с разметкой Freemarker в качестве шаблона отчета. Обычно мы используем его для создания очень пользовательских отчетов в формате HTML, а затем конвертируем результат в PDF .
Наконец, инфраструктура YARG разработана с возможностью расширения, чтобы опытные пользователи могли самостоятельно осуществлять интеграцию с любым другим типом шаблона.
Hello World Report
Давайте познакомимся с YARG. Основная идея генератора отчетов заключается в разделении слоя данных и уровня представления. Уровень данных позволяет создавать сценарии или выполнять прямые запросы SQL для получения необходимой информации, а уровень представления представляет разметку выбранных данных.
Все отчеты YARG состоят из так называемых «полос» . Группа — это то, что связывает слои данных и презентации вместе. Итак, каждая группа знает, откуда взять данные и где они размещены в шаблоне.
Например, мы хотим распечатать всех наших сотрудников в электронную таблицу Excel. Нам нужно будет создать полосу «Сотрудники» и определить запрос SQL для получения списка сотрудников:
|
1
|
select name, surname, position from staff |
Java-код
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
ReportBuilder reportBuilder = new ReportBuilder();ReportTemplateBuilder reportTemplateBuilder = new ReportTemplateBuilder() .documentPath("/home/haulmont/templates/staff.xls") .documentName("staff.xls") .outputType(ReportOutputType.xls) .readFileFromPath();reportBuilder.template(reportTemplateBuilder.build());BandBuilder bandBuilder = new BandBuilder();ReportBand staff= bandBuilder.name("Staff") .query("Staff", "select name, surname, position from staff", "sql") .build();reportBuilder.band(staff);Report report = reportBuilder.build();Reporting reporting = new Reporting();reporting.setFormatterFactory(new DefaultFormatterFactory());reporting.setLoaderFactory( new DefaultLoaderFactory().setSqlDataLoader(new SqlDataLoader(datasource)));ReportOutputDocument reportOutputDocument = reporting.runReport( new RunParams(report), new FileOutputStream("/home/haulmont/reports/staff.xls")); |
Осталось только создать шаблон XLS :

Вот так! Просто запустите программу и наслаждайтесь результатом!
Расширенный пример без Java
Предположим, у нас есть сеть книжных магазинов. Необходимо создать отчет XLS, показывающий список проданных книг, со ссылкой на книжный магазин, где книги были проданы. Более того, у нас нет разработчика на Java, только системный администратор с базовыми навыками работы с XML и SQL .
Прежде всего нам нужно создать шаблон XLS для отчета:

Как видите, мы определяем две именованные области (соответствующие полосам): для магазинов (синим цветом) и для экземпляров книг (белым цветом).
Теперь мы должны получить необходимые данные из базы данных:
|
1
2
3
4
5
6
|
select shop.id as "id", shop.name as "name", shop.address as "address"from store shopselect book.author as "author", book.name as "name", book.price as "price", count(*) as "count"from book book where book.store_id = ${Shop.id} group by book.author, book.name, book.price |
Наконец, мы объявляем структуру бэндов отчета, используя XML :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
<?xml version="1.0" encoding="UTF-8"?><report name="report"> <templates> <template code="DEFAULT" documentName="bookstore.xls" documentPath="./test/sample/bookstore/bookstore.xls" outputType="xls" outputNamePattern="bookstore.xls"/> </templates> <rootBand name="Root" orientation="H"> <bands> <band name="Header" orientation="H"/> <band name="Shop" orientation="H"> <bands> <band name="Book" orientation="H"> <queries> <query name="Book" type="sql"> <script> select book.author as "author", book.name as "name", book.price as "price", count(*) as "count" from book where book.store_id = ${Shop.id} group by book.author, book.name, book.price </script> </query> </queries> </band> </bands> <queries> <query name="Shop" type="sql"> <script> select shop.id as "id", shop.name as "name", shop.address as "address" from store shop </script> </query> </queries> </band> </bands> <queries/> </rootBand></report> |
Давайте запустим отчет и посмотрим на результат (порядок запуска отчета описан ниже в автономном разделе):
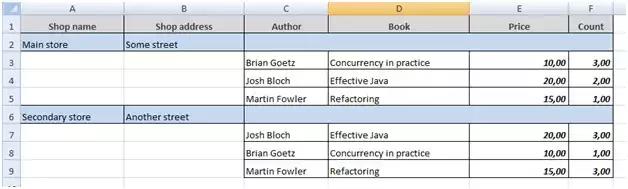
Этот пример использования показывает, что вы можете иметь ссылку на родительский диапазон: book.store_id = $ {Shop.id}. Это позволило нам отфильтровать книги, продаваемые каждым конкретным книжным магазином.
Еще один сложный пример
Давайте теперь создадим отчет по счетам. Мы создадим документ DOCX, а затем преобразуем в неизменяемую форму — документ PDF. Чтобы проиллюстрировать другой способ загрузки данных, мы будем использовать Groovy-скрипт вместо прямого SQL-запроса:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
<?xml version="1.0" encoding="UTF-8"?><report name="report"> <templates> <template code="DEFAULT" documentName="invoice.docx" documentPath="./test/sample/invoice/invoice.docx" outputType="pdf" outputNamePattern="invoice.pdf"/> </templates> <formats> <format name="Main.date" format="dd/MM/yyyy"/> <format name="Main.signature" format="${html}"/> </formats> <rootBand name="Root" orientation="H"> <bands> <band name="Main" orientation="H"> <queries> <query name="Main" type="groovy"> <script> return [ [ 'invoiceNumber':99987, 'client' : 'Google Inc.', 'date' : new Date(), 'addLine1': '1600 Amphitheatre Pkwy', 'addLine2': 'Mountain View, USA', 'addLine3':'CA 94043', 'signature':<![CDATA['<html><body><b><font color="red">Mr. Yarg</font></b></body></html>']]> ]] </script> </query> </queries> </band> <band name="Items" orientation="H"> <queries> <query name="Main" type="groovy"> <script> return [ ['name':'Java Concurrency in practice', 'price' : 15000], ['name':'Clear code', 'price' : 13000], ['name':'Scala in action', 'price' : 12000] ] </script> </query> </queries> </band> </bands> <queries/> </rootBand></report> |
Как вы могли заметить, скрипт Groovy возвращает объект List <Map <String, Object >> . Итак, каждый элемент представлен в виде ключа (имя параметра) и значения (значение параметра).
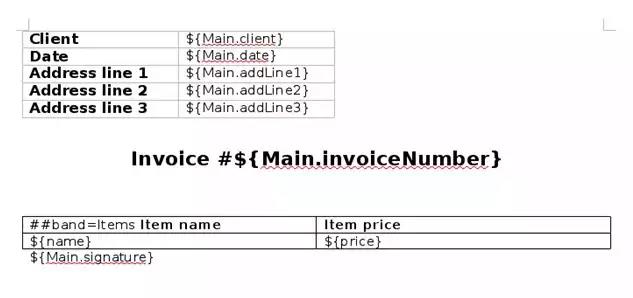
В завершение нам нужно создать шаблон DOCX:
Чтобы связать нижнюю таблицу со списком книг, мы используем маркер ## band = Items.
После того, как отчет сгенерирован, мы получаем следующий вывод:

Интеграция фреймворков IoC
Как упоминалось ранее, одним из требований было предоставить возможность интеграции в интегрированные среды IoC ( Spring , Guice ). Мы используем YARG как часть мощного механизма создания отчетов на платформе CUBA — нашей высокоуровневой Java-инфраструктуры для разработки корпоративных приложений. CUBA использует Spring как механизм IoC, давайте посмотрим, как YARG интегрируется в платформу:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
<bean id="reporting_lib_Scripting" class="com.haulmont.reports.libintegration.ReportingScriptingImpl"/><bean id="reporting_lib_GroovyDataLoader" class="com.haulmont.yarg.loaders.impl.GroovyDataLoader"> <constructor-arg ref="reporting_lib_Scripting"/></bean><bean id="reporting_lib_SqlDataLoader" class="com.haulmont.yarg.loaders.impl.SqlDataLoader"> <constructor-arg ref="dataSource"/></bean><bean id="reporting_lib_JpqlDataLoader" class="com.haulmont.reports.libintegration.JpqlDataDataLoader"/><bean id="reporting_lib_OfficeIntegration" class="com.haulmont.reports.libintegration.CubaOfficeIntegration"> <constructor-arg value="${cuba.reporting.openoffice.path?:/}"/> <constructor-arg> <list> <value>8100</value> <value>8101</value> <value>8102</value> <value>8103</value> </list> </constructor-arg> <property name="displayDeviceAvailable"> <value>${cuba.reporting.displayDeviceAvailable?:false}</value> </property> <property name="timeoutInSeconds"> <value>${cuba.reporting.openoffice.docFormatterTimeout?:20}</value> </property></bean><bean id="reporting_lib_FormatterFactory" class="com.haulmont.yarg.formatters.factory.DefaultFormatterFactory"> <property name="officeIntegration" ref="reporting_lib_OfficeIntegration"/></bean><bean id="reporting_lib_LoaderFactory" class="com.haulmont.yarg.loaders.factory.DefaultLoaderFactory"> <property name="dataLoaders"> <map> <entry key="sql" value-ref="reporting_lib_SqlDataLoader"/> <entry key="groovy" value-ref="reporting_lib_GroovyDataLoader"/> <entry key="jpql" value-ref="reporting_lib_JpqlDataLoader"/> </map> </property></bean><bean id="reporting_lib_Reporting" class="com.haulmont.yarg.reporting.Reporting"> <property name="formatterFactory" ref="reporting_lib_FormatterFactory"/> <property name="loaderFactory" ref="reporting_lib_LoaderFactory"/></bean> |
Чтобы интегрировать YARG в Spring Framework, должны быть зарегистрированы следующие bean-компоненты:
-
reporting_lib_Reporting— предоставляет доступ к основным функциям генерации отчетов. Reports_lib_FormatterFactory — управляет выводом данных в различных форматах (DOCX, XSLX, DOC и т. Д.) -
reporting_lib_LoaderFactory— обеспечивает функциональность загрузки данных (содержит количество бинов, соответствующих различным источникам) -
reporting_lib_OfficeIntegration— интегрирует генератор отчетов с сервером OpenOffice (требуется для генерации отчетов DOC и ODT)
Как вы можете видеть, YARG может быть легко встроен в ваше приложение.
Автономное использование
Еще одна ценная особенность YARG заключается в том, что его можно использовать как отдельное приложение. Технически, если у вас установлена JRE, вы можете запустить генератор отчетов из командной строки. Например, если у вас есть серверное PHP-приложение и вы хотите включить в своем приложении создание отчетов, то просто создайте шаблон XLS, объявите структуру отчета в XML и запустите YARG из командной строки:
|
1
|
yarg -rp ~/report.xml -op ~/result.xls “-Pparam1=20/04/2014” |
Больше возможностей, доступных с платформой CUBA
YARG глубоко интегрирован в платформу CUBA и выступает в качестве основного механизма для мощного механизма отчетности, реализованного в платформе.
Прежде всего, вы можете встроить отчетность в один клик с помощью CUBA Studio (демо-версия доступна только для чтения):
CUBA предлагает удобный пользовательский интерфейс для управления отчетами:
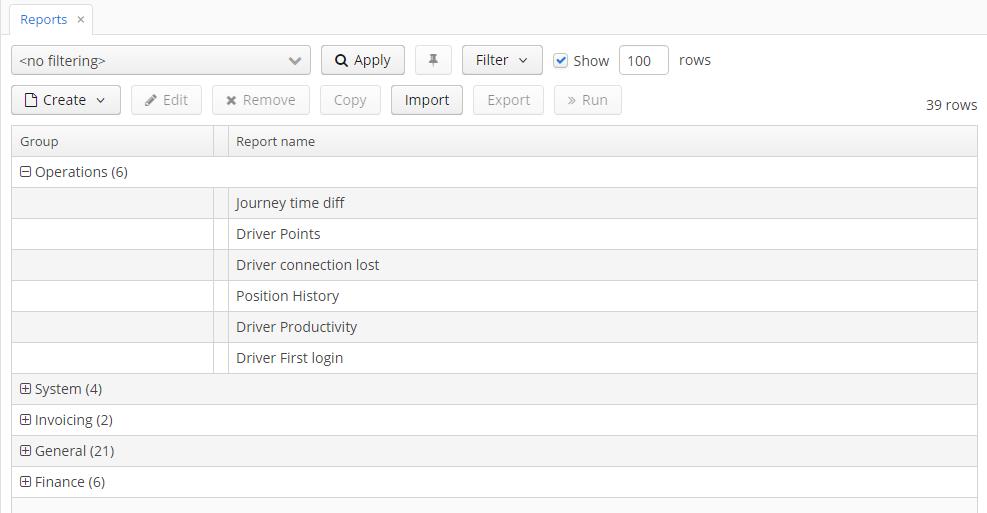
- Браузер отчетов с опциями для импорта / экспорта и запуска отчета.

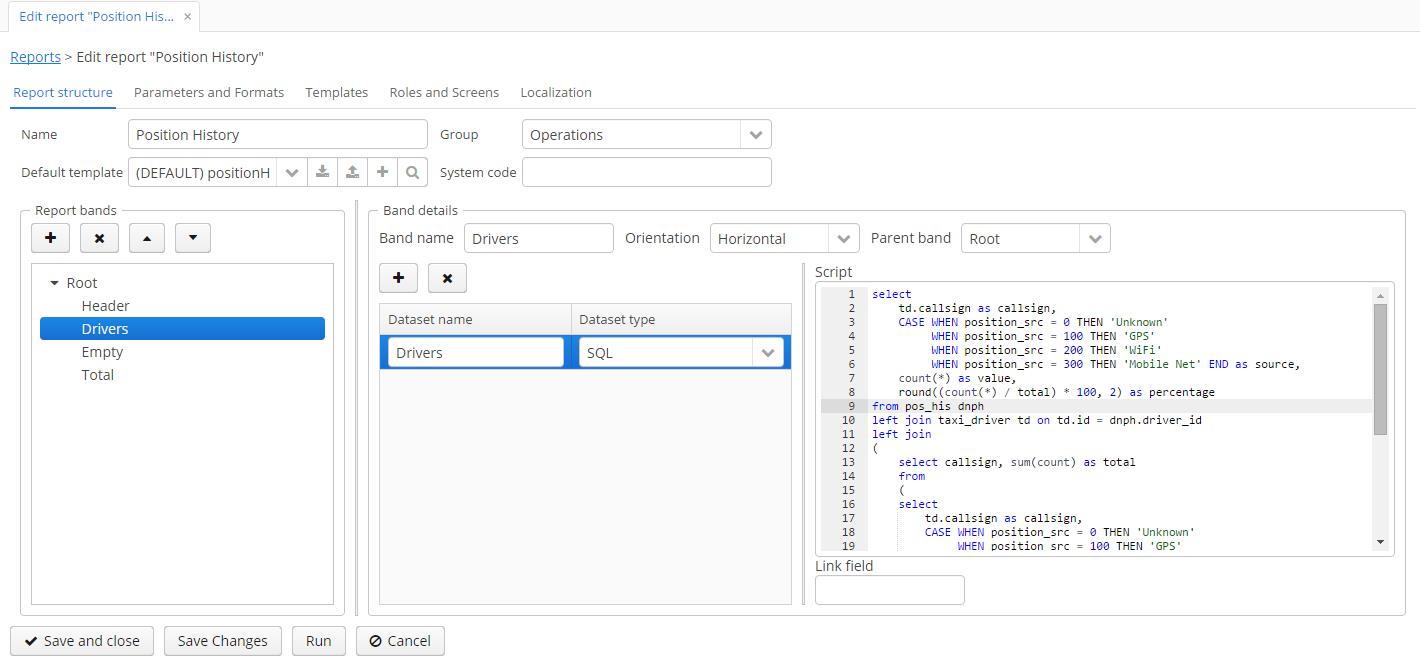
- Редактор отчетов позволяет создавать отчеты любой сложности (определять диапазоны, входные параметры, управлять шаблонами, использовать Groovy, SQL и JPQL для выбора данных):

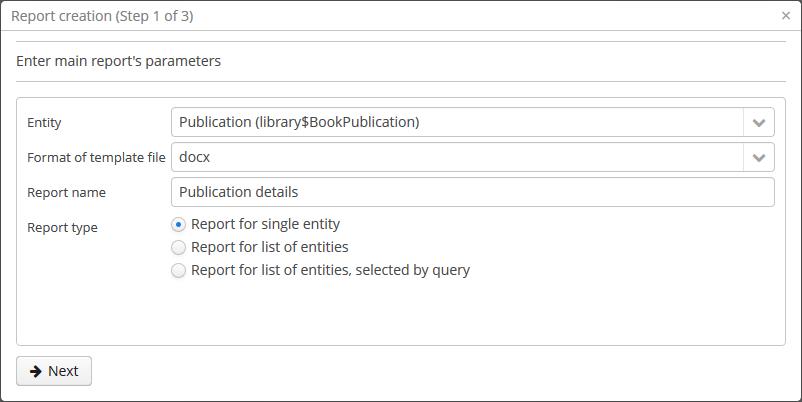
- CUBA представляет функциональность мастера отчетов . С помощью мастера любой пользователь может быстро создать отчет, даже имея ограниченные знания в области программирования:

В завершение статьи позвольте мне пропустить обычные скучные глубокие мысли (особенно потому, что всю информацию можно найти здесь ) и добавить пару моих любимых докладов:
Так что, если вам интересно, перейдите по ссылке и узнайте больше! Обратите внимание, что YARG абсолютно бесплатен и доступен на GitHub .