Эта статья является частью нашего курса Академии под названием Elasticsearch Tutorial для разработчиков Java .
В этом курсе мы предлагаем серию руководств, чтобы вы могли разрабатывать свои собственные приложения на основе Elasticsearch. Мы охватываем широкий спектр тем, от установки и эксплуатации до интеграции Java API и создания отчетов. С нашими простыми учебными пособиями вы сможете запустить и запустить собственные проекты за минимальное время. Проверьте это здесь !
1. Введение
Эффективные, быстрые и точные функции поиска являются неотъемлемой частью подавляющего большинства современных приложений и программных платформ. Либо у вас небольшой веб-сайт электронной коммерции, и вам нужно предложить своим клиентам поиск по каталогам продуктов, либо вы являетесь поставщиком услуг и вам нужно предоставить API, чтобы разработчики могли фильтровать пользователей и компании, или вы создаете какой-либо своего рода приложение для обмена сообщениями, где поиск разговора в истории является обязательной функцией с первого дня … Что действительно важно, так это то, что максимально быстрое получение релевантных результатов может стать еще одним конкурентным преимуществом продукта или платформы, которую вы разрабатываете. ,
Содержание
Действительно, поиск может иметь много лиц, целей, задач и разного масштаба. Это может быть так же просто, как поиск по точному совпадению слов, или так сложно, как попытка понять цель и контекстуальное значение слов, которые ищут ( семантические поисковые системы). С точки зрения масштаба, это может быть тривиально, как запрос одной таблицы базы данных, или настолько сложно, как перебирать миллиарды и миллиарды веб-страниц для достижения желаемых результатов. Это очень интересная и процветающая область исследований, с множеством алгоритмов и статей, опубликованных за эти годы.
Если вы разработчик Java / JVM, возможно, вы слышали о проекте Apache Lucene , высокопроизводительной, полнофункциональной библиотеке индексации и поиска. Это первый и лучший в своем классе выбор, позволяющий раскрыть возможности полнотекстового поиска и внедрить его в свои приложения. Несмотря на то, что это потрясающая библиотека, многие разработчики считают Apache Lucene слишком низкоуровневым и не простым в использовании. Это одна из причин, по которой появились два других замечательных проекта, Elasticsearch и Apache Solr .
В этом уроке мы поговорим о Elasticsearch , сделав акцент на стороне разработки, а не на работе. Мы собираемся изучить основы Elasticsearch , ознакомиться с терминологией и обсудить различные способы ее запуска и взаимодействия с ней из приложений Java / JVM или из командной строки. В самом конце урока мы поговорим об Elastic Stack, чтобы продемонстрировать экосистему вокруг Elasticsearch и ее удивительные возможности.
Если вы начинающий или опытный Java / JVM-разработчик и заинтересованы в изучении Elasticsearch , этот учебник определенно для вас.
2. Основы Elasticsearch
Для начала было бы здорово ответить на вопрос: что такое Elasticsearch , как он может мне помочь и зачем мне его использовать?
Elasticsearch — это хорошо масштабируемая система полнотекстового поиска и анализа с открытым исходным кодом. Это позволяет хранить, искать и анализировать большие объемы данных быстро и практически в реальном времени. Обычно он используется в качестве базового механизма / технологии, которая обеспечивает работу приложений, имеющих сложные функции и требования поиска. — https://www.elastic.co/
Elasticsearch построен на основе Apache Lucene, но поддерживает взаимодействие через RESTful API и расширенные функции аналитики. RESTful часть делает Elasticsearch особенно простым в освоении и использовании. На момент написания этой статьи последняя ветвь стабильного выпуска Elasticsearch была 5.2 , а последняя выпущенная версия — 5.2.0 . Мы, безусловно, должны отдать должное ребятам из 5.0.x / 5.1.x , что 5.0.x / 5.1.x так часто выпускают новые версии, 5.0.x / 5.1.x всего несколько месяцев …
С точки зрения Elasticsearch , API RESTful имеет еще одно преимущество: каждый отдельный фрагмент данных, отправляемых или получаемых из Elasticsearch , сам по себе является читаемым человеком документом JSON (хотя это не единственный протокол, поддерживаемый Elasticsearch, как мы увидим позже) ,
Чтобы обсуждение было актуальным и практичным, мы будем делать вид, что разрабатываем приложение для управления каталогом книг. Модель данных будет включать категории, авторов, издателя, сведения о книге (например, дату публикации, ISBN, рейтинг) и краткое описание.

Каталог книг
Давайте посмотрим, как мы можем использовать Elasticsearch, чтобы сделать наш каталог книг легко доступным для поиска, но перед этим нам нужно немного ознакомиться с терминологией. Хотя в следующих нескольких разделах мы рассмотрим большинство концепций Elasticsearch , пожалуйста, не стесняйтесь обращаться к официальной документации Elasticsearch в любое время.
2.1. документы
Проще говоря, в контексте документа Elasticsearch это просто произвольный фрагмент данных (обычно структурированный). Это может быть абсолютно все, что имеет смысл для ваших приложений (например, пользователи, журналы, сообщения в блогах, статьи, продукты, …), но это основная единица информации, которой Elasticsearch может манипулировать.
2.2. индексы
Elasticsearch хранит документы внутри индексов, и поэтому индекс — это просто набор документов. Чтобы быть справедливым, сохранение абсолютно разных типов документов в одном и том же индексе было бы несколько удобным, но довольно сложным для работы, поэтому каждый индекс может иметь один или несколько типов. Типы группируют документы логически, определяя набор общих свойств (или полей), которые должен иметь каждый документ такого типа. Типы служат метаданными о документах и очень полезны для изучения структуры данных и построения значимых запросов и агрегатов.
2,3. Настройки индекса
Каждый индекс в Elasticsearch может иметь определенные параметры, связанные с ним во время его создания. Наиболее важными из них являются количество осколков и фактор репликации. Давайте поговорим об этом на минуту.
Elasticsearch был создан с нуля для работы с огромным количеством индексированных данных, которые, скорее всего, превысят возможности памяти и / или хранилища одного экземпляра физической (или виртуальной) машины. Таким образом, Elasticsearch использует сегментирование в качестве механизма для разделения индекса на несколько более мелких частей, называемых сегментами, и распределения их между многими узлами. Обратите внимание, что после установки количества шардов нельзя изменить (хотя это уже не совсем так, индекс можно сжать на меньшее количество шардов ).
Действительно, шардинг решает реальную проблему, но он уязвим к проблемам потери данных из-за сбоев отдельных узлов. Для решения этой проблемы Elasticsearch поддерживает высокую доступность, используя репликацию. В этом случае, в зависимости от коэффициента репликации, Elasticsearch поддерживает одну или несколько копий каждого шарда и следит за тем, чтобы реплика каждого шарда была размещена на другом узле.
2,4. Отображения
Процесс определения типа документов и присвоения его определенному индексу называется отображением индекса, типом отображения или просто отображением. Вероятно, создание правильного сопоставления типов — это одно из самых важных упражнений по проектированию, которое вам придется выполнить, чтобы максимально использовать Elasticsearch . Давайте уделим немного времени и поговорим о отображениях в деталях.
Каждое отображение состоит из необязательных мета-полей (обычно они начинаются с символа подчеркивания '_' например _index , _index , _parent ) и обычных полей документа (или свойств). Каждое поле (или свойство) имеет тип данных , который в Elasticsearch может относиться к одной из следующих категорий:
- Простые типы данных
- текст — индексирует полнотекстовые значения
- ключевое слово — индексирует структурированные значения
- date — индексирует значения даты / времени
- long — индексирует 64-битные целые значения со знаком
- integer — индексирует 32-битные целые значения со знаком
- short — индексирует 16-битные целочисленные значения со знаком
- byte — индексирует 8-битные целые значения со знаком
- double — индексирует 64-битные значения IEEE 754 с двойной точностью
- float — индексирует 32-битные значения с плавающей точкой IEEE 754 одинарной точности
- half_float — индексирует полу-точность 16-битных значений IEEE 754 с плавающей запятой
- scaled_float — индексирует значения с плавающей запятой, которые поддерживаются long и фиксированным коэффициентом масштабирования
- boolean — индексирует логические значения (например, true / false , вкл / выкл , да / нет , 1/0 )
- ip — индексирует значения адресов IPv4 или IPv6
- двоичный — индексирует любое двоичное значение, закодированное как строка Base64
- Составные типы данных
- Специализированный тип данных
- geo_point — индексирует пары широта-долгота
- geo_shape — индексирует произвольные геометрические фигуры (например, прямоугольники и многоугольники)
- завершение — выделенный тип данных для поддержки функций автозаполнения / поиска по мере ввода
- token_count — выделенный тип данных для подсчета количества токенов в строке
- percolator — специализированный тип данных для хранения запроса, который будет использоваться запросом percolate для сопоставления документов
- Типы данных диапазона:
- integer_range — индексирует диапазон 32-битных целых чисел со знаком
- float_range — индексирует диапазон 32-битных значений с плавающей точкой IEEE 754 одинарной точности
- long_range — индексирует диапазон 64-битных целых чисел со знаком
- double_range — индексирует диапазон 64-битных значений IEEE 754 с плавающей запятой двойной точности
- date_range — индексирует диапазон значений даты, представленных в виде 64-разрядного целого числа без знака, прошедшего с начала системы
Не могу не подчеркнуть, что выбор правильного типа данных для полей (свойств) ваших документов является ключом для быстрого и эффективного поиска, который дает действительно релевантные результаты. Однако есть одна загвоздка: поля в каждом типе отображения не являются полностью независимыми друг от друга. Поля с одинаковыми именами и в одном и том же индексе, но в разных типах сопоставления должны иметь одно и то же определение сопоставления . Причина в том, что внутренне эти поля отображаются в одно и то же поле .
Возвращаясь к нашей модели данных приложения, давайте попробуем определить простейший тип отображения для коллекций books , используя наши только что приобретенные знания о типах данных.

Каталог картографических книг: первая попытка
Для большинства свойств книги типы данных сопоставления довольно просты, но как насчет авторов и categories ? Эти свойства по существу содержат коллекцию значений, для которых Elasticsearch еще не имеет прямого типа данных … или имеет?
2.5. Расширенные сопоставления
Интересно, что на самом деле Elasticsearch не имеет выделенного массива или типа коллекции, но по умолчанию любое поле может содержать ноль или более значений (своего типа данных).
В случае сложных структур данных Elasticsearch поддерживает отображение с использованием объектных и вложенных типов данных, а также установление родительских / дочерних отношений между документами в пределах одного индекса. У каждого подхода есть свои плюсы и минусы, но чтобы узнать, как использовать эти методы, давайте сохраним categories как вложенное свойство типа отображения books , в то время как authors будут представлены в виде выделенного отображения, которое ссылается на books как на родителей.
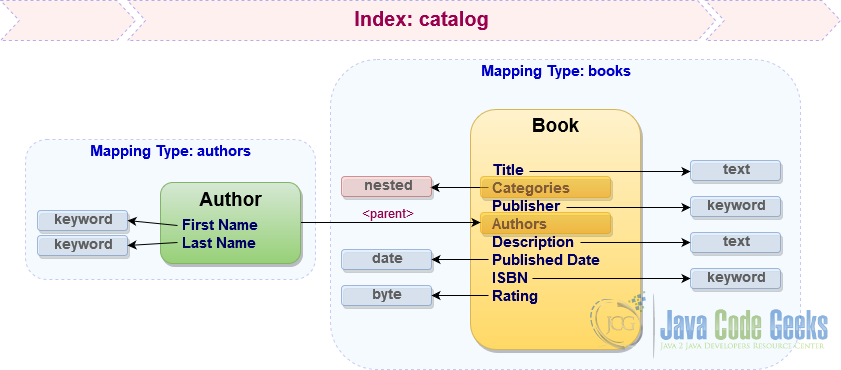
Каталог картографических книг: вторая (и последняя) попытка
Это наши близкие к окончательному типу отображения для индекса catalog . Как мы уже знаем, JSON является гражданином первого класса в Elasticsearch , поэтому давайте посмотрим, как выглядит типичное отображение индекса в формате, который фактически понимает Elasticsearch .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
{ "mappings": { "books": { "_source" : { "enabled": true }, "properties": { "title": { "type": "text" }, "categories" : { "type": "nested", "properties" : { "name": { "type": "text" } } }, "publisher": { "type": "keyword" }, "description": { "type": "text" }, "published_date": { "type": "date" }, "isbn": { "type": "keyword" }, "rating": { "type": "byte" } } }, "authors": { "properties": { "first_name": { "type": "keyword" }, "last_name": { "type": "keyword" } }, "_parent": { "type": "books" } } }} |
Вы можете быть удивлены, но явное определение полей и типов отображения может быть опущено. Elasticsearch поддерживает динамическое отображение, благодаря чему новые типы отображения и новые имена полей будут добавляться автоматически при индексации документа (в этом случае Elasticsearch принимает решение, какими должны быть типы данных поля).
Еще одна важная деталь, о которой следует упомянуть, заключается в том, что с каждым типом сопоставления могут быть связаны пользовательские метаданные с помощью специального свойства _meta . Это исключительно полезный метод, который будет использован нами позже в этом уроке.
2.6. индексирование
Как только Elasticsearch определит все ваши индексы и их типы отображения (или выведет их с помощью динамического отображения ), он будет готов анализировать и индексировать документы. Это довольно сложный, но интересный процесс, в котором участвуют как минимум анализаторы , токенизаторы , фильтры токенов и фильтры символов .
Elasticsearch поддерживает довольно большое количество параметров отображения, которые позволяют адаптировать фазы индексации, анализа и поиска именно к вашим потребностям. Например, каждое отдельное поле (или свойство) может быть настроено на использование собственных анализаторов времени индекса и времени поиска , поддержки синонимов , применения стволовых символов , отфильтровывания стоп-слов и многого другого. Тщательно продумав эти параметры, вы можете получить превосходные возможности поиска, однако обратное также справедливо, если их потерять, и каждый раз может возвращаться множество ненужных и шумных результатов.
Если вам все это не нужно, вы можете перейти к настройкам по умолчанию, как мы делали в предыдущем разделе, не используя параметры. Тем не менее, это редко так. Чтобы дать реалистичный пример, в большинстве случаев наши приложения должны поддерживать несколько языков (и локалей). К счастью, Elasticsearch сияет и здесь.
Прежде чем мы перейдем к следующей теме, есть важное ограничение, о котором вы должны знать. После того, как типы сопоставления настроены, в большинстве случаев они не могут быть обновлены, поскольку это автоматически предполагает, что все документы в соответствующих коллекциях больше не актуальны и должны быть повторно проиндексированы.
2,7. Интернализация (i18n)
Процесс индексации и анализа документов очень чувствителен к родному языку документа. По умолчанию Elasticsearch использует стандартный анализатор, если ни один не указан в типах сопоставления. Он хорошо работает для большинства языков, но Elasticsearch предоставляет специальные анализаторы для арабского, армянского, баскского, бразильского, болгарского, чешского, датского, голландского, английского, финского, французского, немецкого, греческого, хинди, венгерского, индонезийского, ирландского, итальянского , Латышский, литовский, норвежский, персидский, португальский, румынский, русский, испанский, шведский, турецкий, тайский и некоторые другие .
Существует несколько способов приблизиться к индексации одного и того же документа на нескольких языках, в зависимости от вашей модели данных и бизнес-ситуации. Например, если экземпляры документа физически существуют (переведены) на несколько языков, то, вероятно, имеет смысл иметь один индекс для каждого языка.
В случае, когда документы частично переведены, Elasticsearch имеет еще одну интересную опцию, скрытую в рукавах, называемую несколькими полями . Несколько полей позволяют индексировать одно и то же поле документа (свойство) по-разному, чтобы использовать его для разных целей (как, например, поддержка нескольких языков). Возвращаясь к нашему типу отображения books , мы могли определить свойство title как многопольное , например:
|
1
2
3
4
5
6
7
8
9
|
"title": { "type": "text", "fields": { "en": { "type": "text", "analyzer": "english" }, "fr": { "type": "text", "analyzer": "french" }, "de": { "type": "text", "analyzer": "german" }, ... }} |
Это не единственные доступные варианты, но они достаточно хорошо иллюстрируют гибкость и зрелость Elasticsearch в выполнении довольно сложных требований.
3. Запуск Elasticsearch
Elasticsearch включает в себя простоту во многих отношениях, и один из них — чрезвычайно простой способ начать работу практически на любой платформе всего за два шага: скачать и запустить . В следующих нескольких разделах мы поговорим о нескольких различных способах запуска вашего Elasticsearch .
3.1. Автономный экземпляр
Запуск Elasticsearch в качестве отдельного приложения (или экземпляра) — самый быстрый и простой путь. Просто скачайте пакет по вашему выбору и запустите скрипт оболочки в операционных системах Linux / Unix / Mac :
|
1
|
bin/elasticsearch |
Или из командного файла в операционной системе Windows :
|
1
|
bin\elasticsearch.bat |
И это все, довольно просто, не так ли? Однако, прежде чем мы пойдем дальше и поговорим о более продвинутых опциях, было бы полезно узнать, что на самом деле означает запускать экземпляр Elasticsearch . Чтобы быть более точным, каждый раз, когда мы говорим, что запускаем экземпляр Elasticsearch , мы фактически запускаем экземпляр node . Таким образом, в зависимости от предоставленной конфигурации (по умолчанию она хранится в файле conf/elastisearch.yml ), существует несколько типов узлов, которые в данный момент поддерживает conf/elastisearch.yml . В этом отношении каждый работающий автономный экземпляр Elasticsearch может быть настроен для работы в качестве одного (или комбинации) из этих типов узлов:
- узел данных : узлы такого типа поддерживают данные и выполняют операции над этими данными (это контролируется
node.dataконфигурацииnode.dataкоторый по умолчанию имеет значениеtrue) - Узел загрузки : это особый вид узлов, которые могут применять конвейер
node.ingestдля преобразования и обогащения документа перед его индексацией (это контролируетсяnode.ingestконфигурацииnode.ingestкоторый по умолчанию имеет значениеtrue)
Пожалуйста, обратите внимание, что это не исчерпывающий список типов узлов, мы собираемся узнать немало больше за одну минуту.
3.2. Кластеризация
Запуск Elasticsearch в качестве отдельного экземпляра хорош для целей разработки, обучения или тестирования, но, безусловно, не подходит для производственных систем. Как правило, в большинстве реальных развертываний Elasticsearch настроен для работы в кластере : набор из одного или нескольких узлов предпочтительно разделен на несколько физических экземпляров. Кластер Elasticsearch управляет всеми данными, а также предоставляет возможности федеративного индексирования, агрегирования и поиска по всем его узлам.
Каждый кластер Elasticsearch идентифицируется уникальным именем, которое контролируется cluster.name конфигурации cluster.name (по умолчанию установлен "elasticsearch" ). Узлы присоединяются к кластеру, ссылаясь на его имя, так что это довольно важная часть конфигурации. И последнее, но не менее важное: у каждого кластера есть выделенный главный узел, который отвечает за выполнение действий и операций на уровне всего кластера.
Специально применимый к кластерной конфигурации, Elasticsearch поддерживает несколько дополнительных типов узлов, в дополнение к тем, о которых мы уже знаем:
- главный узел : узлы такого типа помечаются как подходящие для
node.masterв качестве главного узла (это контролируетсяnode.masterконфигурацииnode.masterкоторый по умолчанию имеет значениеtrue) - только координирующий узел : это особый вид узлов, которые могут только маршрутизировать запросы, обрабатывать некоторые фазы поиска и распределять массовую индексацию, по сути, выступая в качестве балансировщиков нагрузки (узел автоматически становится только координирующим, когда
node.master,node.dataиnode.ingestпараметровnode.ingestустановлено значениеfalse) - узел племени : это особый вид координируемых узлов, которые могут подключаться к нескольким кластерам и выполнять поиск или другие операции во всех них (это контролируется
tribe.*настройки конфигурации)
По умолчанию, если конфигурация не указана, каждый узел Elasticsearch конфигурируется как отвечающий требованиям мастера , узел данных и узел загрузки . Подобно автономному экземпляру, экземпляры кластера Elasticsearch можно было быстро запустить из командной строки:
|
1
|
bin/elasticsearch -Ecluster.name=<cluster-name> -Enode.name=<node-name> |
Или на платформе Windows:
|
1
|
bin\elasticsearch.bat -Ecluster.name=<cluster-name> -Enode.name=<node-name> |
Помимо сегментирования и репликации, кластер Elasticsearch обладает всеми свойствами высокодоступной и масштабируемой системы, которая будет органически развиваться в соответствии с потребностями ваших приложений. Следует отметить, что, несмотря на значительные усилия, вложенные в стабилизацию кластерной реализации Elasticsearch и охватывающую множество крайних случаев, связанных с различными типами сценариев сбоев, на данный момент Elasticsearch до сих пор не рекомендуется использовать в качестве системы записи (или основного механизма хранения данных). ваши данные).
3.3. Встраивание в приложение
Не так давно (вплоть до ветки релиза 5.0 ) Elasticsearch полностью поддерживал опцию, которая запускается как часть приложения, в рамках того же процесса JVM (метод, обычно называемый встраиванием). Хотя это, безусловно, не рекомендуемая практика, иногда она была очень полезной и экономила много усилий, например, во время тестов интеграции / системы / компонента.
Ситуация недавно изменилась, и встроенная версия Elasticsearch официально не поддерживается и не рекомендуется. К счастью, если вам действительно нужен встроенный экземпляр, например, при медленной миграции со старых версий Elasticsearch , это все еще возможно .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
@Configurationpublic class ElasticsearchEmbeddedConfiguration { private static class EmbeddedNode extends Node { public EmbeddedNode(Settings preparedSettings) { super( InternalSettingsPreparer.prepareEnvironment(preparedSettings, null), Collections.singletonList(Netty4Plugin.class) ); } } @Bean(initMethod = "start", destroyMethod = "stop") Node elasticSearchTestNode() throws NodeValidationException, IOException { return new EmbeddedNode( Settings .builder() .put(NetworkModule.TRANSPORT_TYPE_KEY, "netty4") .put(NetworkModule.HTTP_TYPE_KEY, "netty4") .put(NetworkModule.HTTP_ENABLED.getKey(), "true") .put(Environment.PATH_HOME_SETTING.getKey(), home().getAbsolutePath()) .put(Environment.PATH_DATA_SETTING.getKey(), data().getAbsolutePath()) .build()); } @Bean File home() throws IOException { return Files.createTempDirectory("elasticsearch-home-").toFile(); } @Bean File data() throws IOException { return Files.createTempDirectory("elasticsearch-data-").toFile(); } @PreDestroy void destroy() throws IOException { FileSystemUtils.deleteRecursively(home()); FileSystemUtils.deleteRecursively(data()); }} |
Хотя этот фрагмент кода основан на потрясающей Spring Framework , идея довольно проста и может быть использована в любом приложении на основе JVM. С учетом сказанного, будьте осторожны и пересмотрите долгосрочное решение без необходимости встраивать Elasticsearch .
3.4. Запуск в качестве контейнера
Появление таких инструментов, как Docker , CoreOS, и огромная популяризация контейнеров и развертываний на основе контейнеров существенно изменили наше представление об инфраструктуре и, во многих случаях, также о подходах к разработке.
Другими словами, нет необходимости загружать Elasticsearch и запускать его, используя сценарии оболочки или командные файлы. Все является контейнером и может быть извлечено, настроено и запущено с помощью одной команды docker (к счастью, существует официальный репозиторий Elasticseach Dockerhub ).
Предполагая, что на вашем компьютере установлен Docker , давайте запустим один экземпляр Elasticsearch, используя конфигурацию по умолчанию:
|
1
|
docker run -d -p 9200:9200 -p 9300:9300 elasticsearch:5.2.0 |
Вращать кластер Elasticsearch немного сложнее, но, безусловно, гораздо проще, чем делать это вручную с помощью сценариев оболочки. По большому счету, кластеру Elasticsearch требуется поддержка многоадресной рассылки, чтобы узлы могли автоматически обнаруживать друг друга, но, к сожалению, с Docker вам нужно будет вернуться к одноадресному обнаружению (если у вас нет подписки для разблокировки коммерческих функций ).
|
1
|
docker run -d -p 9200:9200 -p 9300:9300 --name es1 elasticsearch:5.2.0 -E cluster.name=es-catalog -E node.name=es1 -E transport.host=0.0.0.0 |
|
1
|
docker run -d --name es2 --link=es1 elasticsearch:5.2.0 -E cluster.name=es-catalog -E node.name=es2 -E transport.host=0.0.0.0 -E discovery.zen.ping.unicast.hosts=es1 |
|
1
|
docker run -d --name es3 --link=es1 elasticsearch:5.2.0 -E cluster.name=es-catalog -E node.name=es3 -E transport.host=0.0.0.0 -E discovery.zen.ping.unicast.hosts=es1 |
После запуска контейнеров необходимо создать кластер из трех узлов Elasticsearch , с главным узлом, доступным по адресу http://localhost:9200 (в случае встроенной поддержки Docker ). Если по каким-либо причинам вы все еще находитесь на Docker Machine (или даже на более старой версии boot2docker ), главный узел будет открыт по адресу http://<docker-machine-ip>:9200 соответственно.
Если вы активно используете Docker Compose , существуют определенные ограничения, которые усложнят вашу жизнь на этом этапе. В настоящее время образы Elasticsearch требуют передачи некоторых аргументов в точку входа (все, что вы видите в конце командной строки как опция -E ), однако Docker Compose пока не поддерживает такую функцию (хотя вы можете создавать свои собственные изображения как Обходной путь).
В этом руководстве мы будем использовать только Elasticsearch, запущенный в качестве Docker- контейнеров, надеюсь, это то, что вы уже давно применили.
4. Где подходит Elasticsearch
Поиск является одной из ключевых особенностей Elasticsearch, и он делает это исключительно хорошо. Но Elasticsearch выходит далеко за рамки простого поиска и предоставляет богатые аналитические возможности в виде структуры агрегации, которая выполняет агрегацию данных на основе поискового запроса. В случае, если вам нужно будет провести некоторую аналитику вокруг ваших данных, Elasticsearch также отлично подойдет и здесь.
Хотя это может быть неочевидно , Elasticsearch можно использовать для управления данными временных рядов (например, метрики, цены на акции) и даже для поиска изображений . Одно из заблуждений о Elasticsearch заключается в том, что его можно использовать в качестве хранилища данных. В какой-то степени это правда, что он хранит данные, однако он не дает таких же гарантий, как вы ожидаете от типичного хранилища данных.
5. Заключение
Хотя мы говорили о многих вещах здесь, тонны интересных деталей и полезных функций Elasticsearch еще не были рассмотрены. Наше внимание было сосредоточено на аспектах разработки, и поэтому акцент был сделан на понимании основ Elasticsearch и быстром запуске. Надеюсь, вы уже взволнованы и достаточно взволнованы, чтобы сразу же приступить к чтению официальной справочной документации , поскольку на подходе более интересные темы.
6. Что дальше
В следующем разделе мы собираемся перейти от обсуждений к действиям, исследуя и играя с множеством API-интерфейсов RESTful, предоставляемых Elasticsearch , вооруженных только командной строкой и великолепными инструментами curl / http .
Исходный код этого поста доступен здесь для скачивания.