Эта статья является частью нашего курса Академии под названием Elasticsearch Tutorial для разработчиков Java .
В этом курсе мы предлагаем серию руководств, чтобы вы могли разрабатывать свои собственные приложения на основе Elasticsearch. Мы охватываем широкий спектр тем, от установки и эксплуатации до интеграции Java API и создания отчетов. С нашими простыми учебными пособиями вы сможете запустить и запустить собственные проекты за минимальное время. Проверьте это здесь !
1. Введение
В этой последней части руководства мы рассмотрим и узнаем, как идеально Elasticsearch вписывается в экосистему Java и вдохновляет на множество интересных проектов. Один из лучших способов проиллюстрировать это — взглянуть на сочетание Elasticsearch и Hibernate Framework, исключительно любимого выбора среди разработчиков Java для управления уровнем персистентности.
Содержание
Кроме того, в самом конце мы рассмотрим чрезвычайно популярный набор приложений, известный как Elastic Stack , и что вы можете с ним сделать. Хотя это выходит далеко за рамки только Java-приложений, трудно переоценить значение, которое оно предлагает для современных, сильно распределенных программных систем.
2. Elasticsearch для пользователей Hibernate
Практически невозможно найти разработчика Java, который бы не слышал об инфраструктуре Hibernate . С другой стороны, не так много разработчиков знают, что под зонтиком Hibernate скрыто немало проектов, и один из них — настоящая жемчужина под названием Hibernate Search .
Hibernate Search прозрачно индексирует ваши объекты и предлагает быстрый регулярный полнотекстовый поиск и поиск по геолокации. Простота использования и простота кластеризации являются основными. — http://hibernate.org/search/
Поиск Hibernate начинался как простой связующий слой между Hibernate и Apache Lucene и использовался для предоставления очень ограниченного набора поддерживаемых бэкэндов для управления поисковыми индексами. Но ситуация меняется в лучшую сторону с только что вышедшей финальной версией Hibernate Search 5.7.0 вместе с полноценной поддержкой Elasticsearch (пока еще носящей experimental лейбл). Практически это означает, что если ваш уровень персистентности управляется Hibernate , то, подключив Hibernate Search, вы можете обогатить свою модель данных с помощью полнотекстового поиска, все это поддерживается Elasticsearch . Звучит захватывающе, верно?
Чтобы понять, как все работает, давайте взглянем на нашу модель данных catalog выраженную в виде сущностей JPA, украшенных аннотациями Hibernate Search , начиная с класса Book .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
@Entity@Table(name = "BOOKS")@Indexed(index = "catalog")public class Book { @Id @Field(name = "isbn", analyze = Analyze.NO) private String id; @Field @Column(name = "TITLE", nullable = false) private String title; @IndexedEmbedded(depth = 1) @ElementCollection private Set categories = new HashSet<>(); @Field(analyze = Analyze.NO) @Column(name = "PUBLISHER", nullable = false) private String publisher; @Field @Column(name = "DESCRIPTION", nullable = false, length = 4096) private String description; @Field(name = "published_date", analyze = Analyze.NO) @Column(name = "PUBLISHED_DATE", nullable = false) @DateBridge(resolution = Resolution.DAY) private LocalDate publishedDate; @NumericField @Field(name = "rating") @Column(name = "RATING", nullable = false) private int rating; @IndexedEmbedded @ManyToMany private Set authors = new HashSet(); } |
Для опытных Java-разработчиков это знакомый фрагмент кода для описания постоянных сущностей, с добавлением только нескольких аннотаций Hibernate Search (таких как @Field , @DateBridge , @IndexedEmbedded ). Мы не собираемся обсуждать их здесь, к сожалению, эта тема сама по себе достойна полного урока, но, пожалуйста, не стесняйтесь обращаться к официальной документации для получения более подробной информации. С учетом сказанного, мы просто переходим к классу Category .
|
1
2
3
4
5
6
|
@Embeddablepublic class Category { @Field(analyze = Analyze.NO) @Column(name = "NAME", nullable = false) private String name; } |
Затем следует класс Author .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
@Entity@Indexed(index = "catalog")@Table(name = "AUTHORS")public class Author { @Id private String id; @Field(name = "first_name", analyze = Analyze.NO) @Column(name = "FIRST_NAME", nullable = false) private String firstName; @Field(name = "last_name", analyze = Analyze.NO) @Column(name = "LAST_NAME", nullable = false) private String lastName;} |
Благодаря Spring Framework и, в частности, Spring Boot magic, настройка Hibernate и Hibernate Search, указывающая на Elasticsearch в качестве бэкэнда поиска, так же проста, как добавление пары строк в файл application.yml .
|
1
2
3
4
5
6
7
8
9
|
spring: jpa: properties: hibernate: search: default: indexmanager: elasticsearch elasticsearch: host: http://localhost:9200 |
Честно говоря, вам может понадобиться немного изменить эту конфигурацию, чтобы она соответствовала потребностям ваших приложений, к счастью, официальная документация довольно хорошо описывает эту часть. Каждый раз, когда экземпляры классов Book или Author создаются, изменяются или удаляются, Hibernate Search обеспечивает синхронизацию индекса Elasticsearch, он полностью прозрачен.
Как выглядит поиск? Что ж, Hibernate Search предоставляет собственный уровень абстракции Query DSL , основанный на запросах Apache Lucene (в то же время оставляя маршрут для использования некоторых собственных функций Elasticsearch ), например:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
@Autowired private EntityManager entityManager; final FullTextEntityManager fullTextEntityManager = Search .getFullTextEntityManager(entityManager); final QueryBuilder qb = fullTextEntityManager .getSearchFactory() .buildQueryBuilder() .forEntity(Book.class) .get(); final FullTextQuery query = fullTextEntityManager .createFullTextQuery( qb.bool() .must( qb.keyword() .onField("categories.name") .matching("analytics") .createQuery() ) .must( qb.keyword() .onField("authors.last_name") .matching("Tong") .createQuery() ).createQuery(), Book.class); final List books = query.getResultList();... |
Определенно, есть много общего с собственным Query DSL от Elasticsearch, поэтому этот фрагмент кода должен показаться вам уже знакомым. Но прежде чем вы будете слишком взволнованы, есть несколько ограничений, связанных с Hibernate Search и интеграцией Elasticsearch . Прежде всего, последняя версия Elasticsearch, которая на данный момент поддерживается Hibernate Search, — это 2.4.4 . Неплохо, но довольно далеко от текущей ветки релиза 5.x , надеюсь, это будет исправлено в ближайшее время. Во-вторых, действительно, подмножество функций Elasticsearch, предоставляемых через API Hibernate Search , в частности Query DSL , весьма ограничено, но, честно говоря, может быть достаточно для многих приложений.
Во всяком случае, почему мы упоминаем Hibernate Search в первую очередь? Проще говоря, если ваши приложения построены на основе устойчивости Hibernate , использование Hibernate Search , вероятно, является самым быстрым и дешевым способом воспользоваться возможностями полнотекстового поиска для ваших моделей данных, используя Elasticsearch за кулисами.
3. Эластичный стек: получи все
Если вы уже столкнулись с загадочной аббревиатурой ELK и вам было любопытно, что это значит, этот раздел поможет вам найти ответы. ELK — это, по сути, набор продуктов, состоящий из (E) lasticsearch , (L) ogstash и (K) ibana , поэтому просто ELK вкратце. Недавно, с добавлением Beats , нового члена этой удивительной семьи, ELK теперь часто называют Elastic Stack .
Несомненно, Elasticsearch является сердцем и душой ELK, поэтому давайте поговорим о том, что эти другие продукты и почему они полезны.
Kibana позволяет вам визуализировать данные Elasticsearch и ориентироваться в Elastic Stack , поэтому вы можете делать все, что угодно, от изучения причин, по которым вы получаете страничку в 2:00 утра до понимания влияния дождя на ваши квартальные показатели. — https://www.elastic.co/products/kibana
По сути, Kibana — это просто веб-приложение, способное создавать мощные диаграммы и информационные панели на основе данных, которые вы проиндексировали в Elasticsearch .
Logstash — это конвейер обработки данных на стороне сервера с открытым исходным кодом, который одновременно принимает данные из множества источников, преобразует их и затем отправляет в ваш любимый «stash», например, Elasticsearch — https://www.elastic.co/products / logstash
Следовательно, Logstash — это потрясающий инструмент, способный извлекать, массировать и передавать данные в Elasticsearch (и множество других источников), которые впоследствии можно будет визуализировать с помощью Kibana . Удары довольно близки к Logstash, но еще не настолько сильны.

Иллюстрированный эластичный стек
Одна из областей, где Elastic Stack исключительно полезен и ведет гонку, — это сбор и анализ огромного количества журналов приложений. Это может звучать не очень убедительно, зачем вам такая сложная система, чтобы привязать / grep к файлу журнала? Но в масштабе, когда вы имеете дело с сотнями или даже тысячами приложений (например, с микросервисами ), преимущества становятся очень очевидными: у вас внезапно появляются централизованные места, где журналы всех приложений перенаправляются и могут просматриваться, анализироваться, коррелированные и визуализированные.
Без дальнейших обсуждений давайте продемонстрируем, как можно настроить типичное приложение Spring Boot для отправки своих журналов в Logstash , который направит их в Elasticsearch как есть, без применения преобразований. Во-первых, нам нужно, чтобы Logstash был установлен либо в виде контейнера Docker, либо просто запущен на локальной машине , официальная документация исключительно хорошо описывает шаги установки.
Единственное, что нам нужно сообщить Logstash, — откуда брать журналы (используя входные плагины ) и куда отправлять массированные журналы (используя выходные плагины ), все это через logstash.conf конфигурации logstash.conf .
|
01
02
03
04
05
06
07
08
09
10
11
|
input { tcp { port => 7760 }}output { elasticsearch { hosts => [ "localhost:9200" ] }} |
Число входных и выходных плагинов, поддерживаемых Logstash, поражает воображение. Чтобы сохранить пример очень простым, мы собираемся доставить журналы через входной плагин сокета TCP и переслать прямо в Elasticsearch с помощью выходного плагина Elasticsearch .
Это выглядит великолепно, но как мы могли бы отправлять логи из наших Java-приложений в Logstash ? Есть много способов сделать это, и самый простой из них, вероятно, заключается в использовании возможностей вашей системы ведения журналов. Большинство приложений Java в настоящее время полагаются на потрясающую инфраструктуру Logback, и сообщество внедрило специальный кодировщик Logback, который будет использоваться вместе с Logstash .
Вам просто нужно включить дополнительную зависимость в ваш проект, как мы делаем здесь, например, используя Apache Maven :
|
1
2
3
4
5
|
<dependency> <groupId>net.logstash.logback</groupId> <artifactId>logstash-logback-encoder</artifactId> <version>4.9</version></dependency> |
Затем добавьте приложение Logstash в logback.xml конфигурации logback.xml . Следует отметить, что есть несколько доступных приложений, один из которых нас интересует, это LogstashTcpSocketAppender который общается с Logstash через TCP-сокет. Обратите внимание, что порт под тегом destination должен соответствовать конфигурации вашего входного плагина Logstash , в нашем случае это 7760 .
|
1
2
3
4
|
<appender name="logstash" class="net.logstash.logback.appender.LogstashTcpSocketAppender"> <destination>localhost:7760</destination> <encoder class="net.logstash.logback.encoder.LogstashEncoder" /></appender> |
По большому счету это все, что нам нужно сделать! Журналы будут отправлены из нашего приложения в Elasticsearch, и мы могли бы изучить их с помощью инструментальных панелей Kibana . При загрузке и запуске Kibana на локальном компьютере веб-интерфейс по умолчанию доступен по адресу http: // localhost: 5601 :

Панель быстрого Кибана
Легкий, простой, мощный … способ Elasticsearch . Единственное, что нужно помнить, это то, что вам лучше использовать те же версии Elasticsearch , Logstash и Kibana . Поскольку мы использовали Elasticsearch 5.2.0 этом руководстве, Logstash и Kibana должны быть версии 5.2.0 .
Если вы уже используете Elasticsearch или планируете это сделать, Elastic Stack просто открывает целую вселенную интересных возможностей для вас, чтобы узнать и извлечь из них выгоду. Более того, он постоянно совершенствуется и дополняется новыми функциями, добавляемыми в каждом выпуске.
4. Supercharge Elasticsearch с плагинами
Elasticsearch — это замечательно, но часто инструменты командной строки или даже API-интерфейсы Java не лучший способ взаимодействия с вашими кластерами. К счастью, Elasticsearch с самого начала имеет встроенную расширяемость в виде плагинов.
На данный момент доступно множество плагинов и сопутствующих инструментов, но стоит поговорить о трех из них:
- головка упругого поиска : веб-интерфейс для кластера Elasticsearch
- asticsearch-HQ : мониторинг, управление и использование веб-интерфейса для Elasticsearch
- охранник : безопасность для Elasticsearch
По сути , asticsearch-head — это полноценный веб-интерфейс для Elasticsearch . Мало того, что у вас есть хорошее визуальное представление индексов и сегментов, вы также можете просматривать документы, играть с поисковыми запросами и легко перемещаться по результатам.
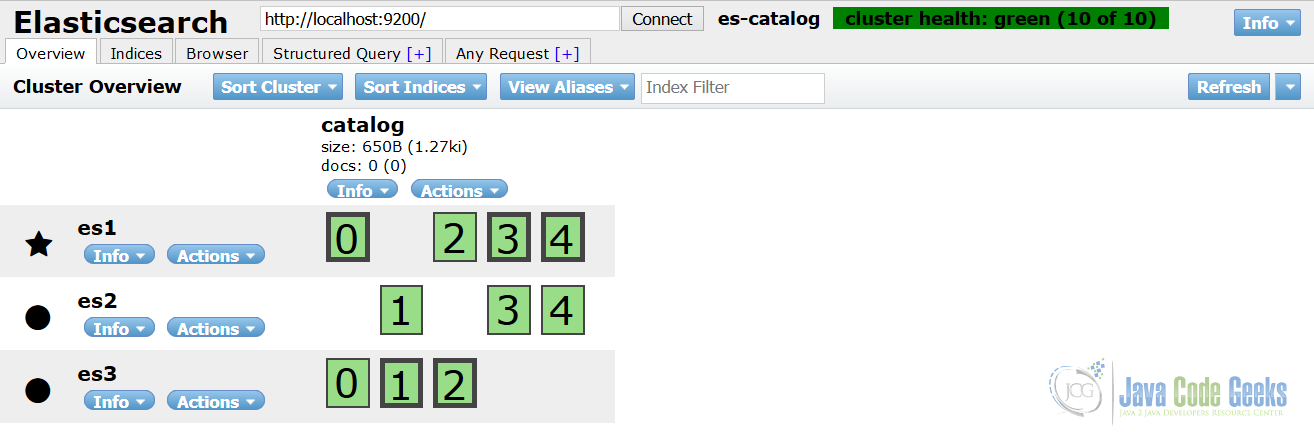
Пример эластичного заголовка, показывающего индекс каталога и статус кластера
Возможность выполнения структурированных или произвольных запросов очень полезна, особенно если ваш запрос возвращает много результатов, и вам нужен удобный способ пройти через все из них.
Другой очень интересный объект — FlexibleSearch-HQ, в котором основное внимание уделяется раскрытию оперативной информации о кластерах и узлах ElasticSearch . К сожалению, на момент написания этой статьи , asticsearch-HQ не поддерживает ветку релиза 5.x Elasticsearch, но работа над этим уже началась.
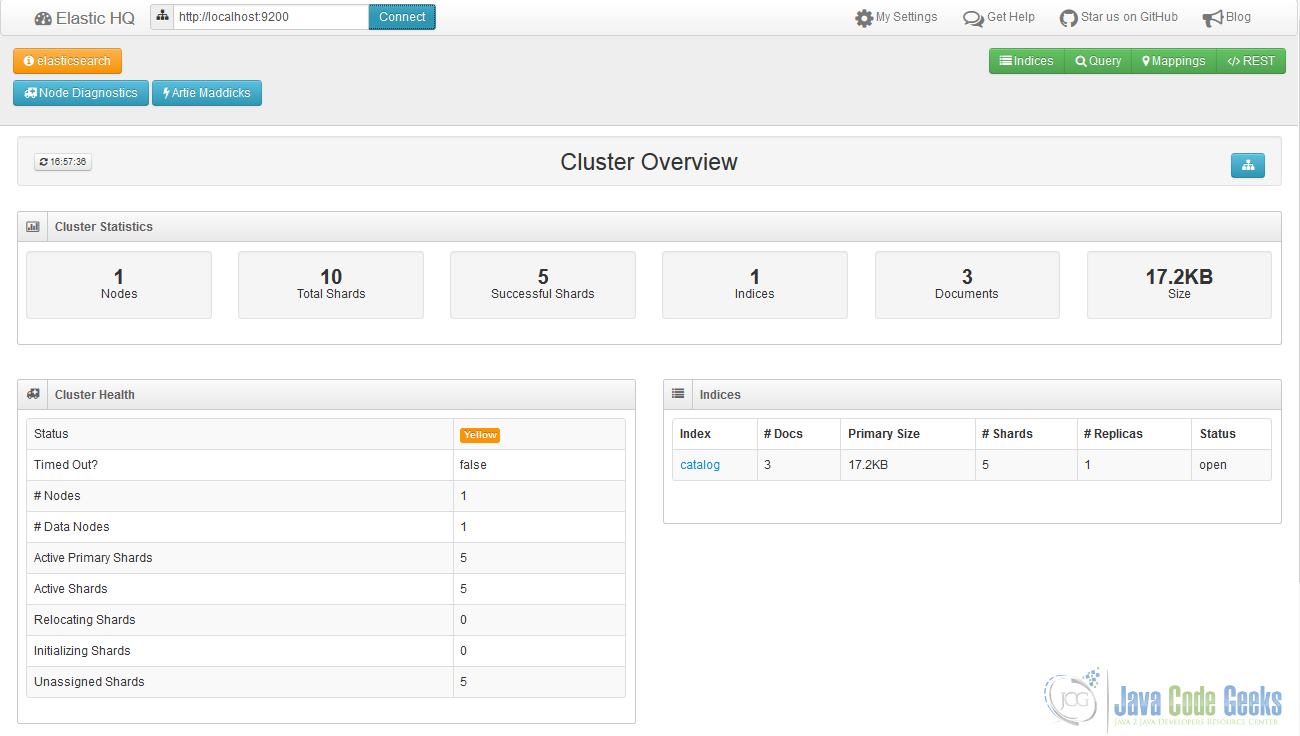
Пример эластичного поиска-HQ, показывающий индекс каталога и статус кластера
Прежде чем мы коснемся последнего плагина, поисковой охраны , было бы хорошо поговорить о состоянии безопасности в Elasticsearch . На самом деле, нам лучше сказать, что Elasticsearch не имеет ничего общего с точки зрения безопасности или аналога (хотя эта функция, наряду со многими другими, доступна как часть коммерческого распространения Elasticsearch ). Search-guard — это самый старый плагин, поддерживаемый сообществом, который добавляет в Elasticsearch довольно много возможностей безопасности. Пожалуйста, не забудьте взглянуть на это, если вы серьезно относитесь к запуску Elasticsearch в производстве, к счастью, он поддерживает все последние версии Elasticsearch .
5. Выводы
На этом часть серии «Elasticsearch for Java Developers» подходит к своему логическому завершению. В этом уроке мы узнали о Elasticsearch , о том, что он делает и как с ним общаться, используя инструменты командной строки и его богатый набор RESTful API . Мы также обсудили различные разновидности Java API, доступные на данный момент, и кратко обсудили, когда использовать тот или иной. И наконец, мы охватили процветающую экосистему проектов (и продуктов), которая возникла вокруг Elasticsearch и в значительной степени опирается на ее особенности.
Надеюсь, вы узнали кое-что на этом пути, и если вы уже колебались, пытаясь дать Elasticsearch попробовать или нет, все ваши сомнения должны быть прояснены сейчас. Это отличный продукт с потрясающим потенциалом для решения широкого спектра сложных проблем и воплощения ваших идей в успех.
С этим, удачи в этом путешествии! Полный исходный код этой статьи доступен здесь .