Когда вы работаете с программным обеспечением, критически важным для вашей компании, вы не можете иметь журналы только для анализа того, что произошло некоторое время назад, когда клиент говорит вам, что ваше приложение сломано, а вы даже не знаете, что происходит, это реально проблема. Одним из способов справиться с этим является использование мониторинга и ведения журнала.
В большинстве приложений ведется логирование, даже если это просто текстовый файл, который потребует использования таких инструментов, как grep или tail, чтобы увидеть, что происходит. Но это очень пассивный способ просмотра журналов, поскольку вы должны принять меры, и, вероятно, вы будете просматривать журналы только тогда, когда что-то не так. Вам нужно, чтобы ваши журналы сообщали вам, что происходит, и сегодня мы собираемся сделать первый шаг для этого.
По названию вы, наверное, уже знаете, что мы будем говорить о Elasticstack . Мое намерение с этим постом состоит в том, чтобы предоставить базовый способ начать собирать и анализировать ваши журналы, без необходимости справляться со всеми трудностями, через которые я прошел.
Эластичный стек
Ранее известный как ELK, Elastic Stack — это набор инструментов, которые помогают вам collect , structure , store , analyse а также помогают создавать actions для определенных ситуаций.
Эластичный стек состоит из 4 компонентов:
-
Kibana— это инструмент визуализации, который считывает данные изElasticSearch. Вы можете создавать панели мониторинга или делать запросы кElasticSearchвручную. -
ElasticSearch— это магазин журналов. Вы можете отправлять журналы изBeatsилиLogstashи они хранятся в индексе. Вы можете иметь несколько индексов для хранения данных из нескольких источников. -
Logstash— это приложение, которое заботится о журналах, вы можете анализировать журналы в более полезные данные и отправлять их вElasticSearch. -
BeatsилиFilebeat— это легкий инструмент, который читает журналы и отправляет их вElasticSearchилиLogstash. Единственная цель этого инструмента — читать файлы журнала, он не может выполнять с ним никаких сложных операций. Если вам нужно выполнить сложную операцию, вы можете отправить этот журнал вLogstashчтобы он проанализировал нужную информацию.
Logstash
Мы начинаем с Logstash поскольку именно так вы собираете и анализируете свои логи (да, я упомянул Beats но вам это не нужно для запуска).
Logstash — это обработчик и получение журналов. Главная особенность Logstash — дать структуру неструктурированным файлам журнала, есть три шага для обработки журнала:
- Ввод — получение или получение журнала.
- Фильтр — обработка или фильтрация.
- Вывод — отправка журнала в постоянное хранилище.
вход
Logstash может извлекать данные не только из файлов журналов, но и из разных источников, например:
- Текстовые файлы
- Базы данных
- Команды оболочки
- Очереди
- Http-запросы
Если вы хотите увидеть все входные плагины, которые поддерживает Logstash проверьте документы .
Прямо сейчас, входы, которые я использовал, и я объясню, как использовать:
- Текстовые файлы
- Базы данных
- Команды оболочки
Ввод текстового файла
Один из наиболее распространенных способов хранения журналов — это текстовые файлы, которые находятся где-то на машине, обычно /var/log . Logstash имеет плагин, который читает файл и продолжает следить за новыми строками, как tail -f .
Чтобы использовать плагин, это очень просто, вам просто нужно добавить путь к файлу, а Logstash позаботится обо всем остальном, не беспокойтесь о повороте файлов, плагин знает, как с этим справиться.
Использование file плагина выглядит так:
|
1
2
3
4
5
6
|
input { file { path => /var/log/app/realworld.log id => realworld }} |
Таким образом, как мы настроили Logstash выше, каждая строка будет записью в журнале. Но иногда наши журналы не так просты, и у нас есть такие вещи, как трассировка стека, или мы записываем JSON в журналы. В этом случае нам нужно, чтобы они были вместе, чтобы иметь смысл, и поэтому Logstash предоставляет codecs , которые являются способом расширения входных плагинов. Одним из таких кодеков является Multiline .
Например, ниже у нас есть журналы для приложения, которое использует Spring, и когда у нас есть Stack Trace, мы хотим сгруппировать его только в одну строку.
|
01
02
03
04
05
06
07
08
09
10
11
|
2019-08-18 18:31:53.845 INFO 6724 --- [ main] o.s.t.web.servlet.TestDispatcherServlet : FrameworkServlet '': initialization completed in 17 mscom.andre2w.transaction.TransactionTooOldException at com.andre2w.transaction.TransactionService.validateTimestamp(TransactionService.java:46) at com.andre2w.transaction.TransactionService.add(TransactionService.java:29) at com.andre2w.controllers.TransactionController.create(TransactionController.java:42) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) 2019-08-18 18:31:53.891 INFO 6724 --- [ main] o.s.b.t.m.w.SpringBootMockServletContext : Initializing Spring FrameworkServlet ''2019-08-18 18:31:53.892 INFO 6724 --- [ main] o.s.t.web.servlet.TestDispatcherServlet : FrameworkServlet '': initialization started |
Поэтому, если мы хотим получить трассировку стека из наших журналов, мы можем сделать простое регулярное выражение, чтобы сгруппировать все, начиная с пробела.
|
01
02
03
04
05
06
07
08
09
10
|
input { file { path => /var/log/app/realworld.log id => realworld codec => multiline { pattern => "^\s" what => "previous" } }} |
Но в этом случае мы можем пойти еще дальше. Поскольку эти журналы взяты из приложения, использующего Spring, и все журналы имеют определенный формат, мы можем сгруппировать все, что не соответствует этому формату, включая трассировки стека, JSON и объекты.
|
01
02
03
04
05
06
07
08
09
10
11
12
|
input { file { path => /var/log/app/realworld.log id => realworld codec => multiline { pattern => "\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d{3} \w+ \d+ --- \[\s+\w+]" negate => true what => "next" } }} |
Что означает negate и what означает?
Отрицание — это опция, позволяющая определить, хотите ли вы сгруппировать строки, в которых регулярное выражение совпадает или не совпадает. В первом примере поле negate опущено, поэтому оно имеет значение по умолчанию False . negate => false означает, что строки будут сгруппированы, когда регулярное выражение будет найдено. negate => true означает, что строки будут сгруппированы, когда регулярное выражение НЕ соответствует.
То, как Logstash будет группировать запросы. previous означает, что совпавшая строка сгруппируется с предыдущей строкой, а next довольно очевидно, что она делает.
База данных
Поскольку Logstash работает с использованием Java, у вас есть доступ к любой базе данных, поддерживаемой JDBC . Для Postgres вы можете увидеть количество блокировок, запрашивающих таблицу pg_locks .
Конфигурация для чего-то подобного будет:
|
01
02
03
04
05
06
07
08
09
10
11
|
input { jdbc { jdbc_connection_string => "jdbc:postgres://localhost:5432/main" jdbc_user => "postgres" jdbc_password => "postgres" jdbc_driver_class => "org.postgresql.Driver" statement_filepath => "/etc/logstash/queries/query-locks.sql" schedule => "* * * * *" tags => ["jdbc","staging-1","query-locks", "main"] }} |
Поля, начинающиеся с jdbc_ содержат информацию для подключения к базе данных. Затем у нас есть Logstash , это указывает на файл с запросом, который вы хотите запустить Logstash , вы также можете использовать опцию Logstash для большего количества специальных запросов. Наконец, у нас есть опция schedule , это частота, с которой вы хотите выполнить запрос, значение основано на crontab Linux, в этом примере оно будет выполняться каждую минуту.
tags помогут вам определить запрос, который вы выполняете. Это просто массив строк, вы можете добавить что угодно.
Logstash проанализирует все поля и отправит его в хранилище данных, указанное в выходных данных.
При использовании входных данных JDBC нужно следить за тем, чтобы вам нужен jar в пути к классам Logstash. В папке установки Logstash вы идете в libs/jars и добавляете jar для драйвера базы данных.
Exec
Иногда вам может Logstash получить данные из источника, который Logstash не очень хорошо поддерживает. В этом случае вы можете использовать входной плагин exec который выполняет приложение командной строки и получает результат в виде лог-строки.
|
1
2
3
4
5
6
7
|
input { exec { command => "/usr/bin/retrieve-data.sh" schedule => "* * * * *" tags => ["retrieve-data","staging"] }} |
Этот ввод очень прост в использовании, у вас есть варианты:
-
command:commandоболочки, которую вы хотите использовать. -
schedule: то же самое, что и расписаниеjdbc-input— это частота, с которой вы хотите выполнить команду. -
tags: информация для определения результата позже.
С этим плагином вам не нужно беспокоиться о многолинейности результата, Logstash сгруппирует все в одну строку.
Фильтр
Допустим, мы получаем данные из всех входных данных, но нам нужно преобразовать эти данные во что-то полезное. Мы не просто хотим иметь строки журнала, но мы хотим, чтобы статистика могла видеть, что происходит в режиме реального времени, и преобразовывать полученные журналы в правильно структурированные данные.
Grok Parser
В большинстве случаев используется плагин Grok Parser. В большинстве случаев данные из журналов не представлены в структурированном формате, но нам все еще необходимо проанализировать эти неструктурированные данные и придать им некоторое значение. Мы не можем иметь числа, являющиеся строками, если мы хотим что-то сложить. Grok не структурирует данные с помощью регулярных выражений, Logstash имеет набор встроенных регулярных выражений, которые покрывают большинство случаев.
Вот пример фильтра.
Мы получаем HTTP-запросы из Интернета, и мы хотим отслеживать, какие конечные точки имеют наибольшее количество запросов, наш журнал структурирован следующим образом:
192.168.0.1 GET / index
Итак, мы добавили фильтр Grok, чтобы структурировать это:
|
1
2
3
4
5
6
7
|
filter { grok { match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request}" } }} |
Что происходит в этом фильтре?
match говорит о том, чтобы проверить поле сообщений полученных нами журналов и преобразовать их в структурированные данные.
Итак, у нас есть запрос от веб-сервера:
Я хочу, чтобы Logstash получил журнал и преобразовал его в структурированные данные (это JSON, как и все в наше время). Мы делаем матчер как:
|
1
|
"%{IP:client} %{WORD:method} %{URIPATHPARAM:request}" |
Синтаксис для grok: %{PATTERN:field}
Шаблон — это то, как вы хотите сопоставить поле и какое регулярное выражение будет использоваться в данных, а поле будет полем, в котором эти данные будут храниться (немного очевидно). Вы можете увидеть все шаблоны, доступные здесь .
В случае, если Logstash не может правильно проанализировать шаблон, он добавит тег _grokparsefailure .
Так как это просто куча регулярных выражений при разборе данных, вы можете создавать свои собственные шаблоны. Для этого вам нужно создать папку с именем Logstash внутри папки Logstash (вам нужно будет проверить, где она установлена). Имя файла может быть названо как угодно, Logstash будет читать все внутри.
|
1
2
3
4
5
6
|
grok { match => { "path" => "/%{FILE_VERSION:version}_%{BU_ID:id}\.csv$" } patterns_dir => ["/elasticsearch/logstash/example/patterns"]} |
Есть также способ поместить файлы в другую папку, а затем объявить это в файле конфигурации.
Содержимое файла должно соответствовать шаблону PATTERN_NAME regex , поэтому вы должны получить что-то вроде:
|
1
2
|
FILE_VERSION \w+\d{6}(?=_)BU_ID \d{3}(?=\.) |
Если вы не планируете повторно использовать регулярное выражение и хотите встроить его, вы также можете сделать это:
|
1
|
%{DATESTAMP:timestamp} (?<mti_before>\w{46})(?<mti>\w{4})%{GREEDYDATA} |
Подобно группе регулярных выражений, вы используете скобки, чтобы указать, что вы хотите сгруппировать, затем вы начинаете со знака вопроса, чтобы сообщить, что вы собираетесь использовать регулярное выражение. Затем вы добавляете имя поля, к которому вы собираетесь анализировать данные, и, наконец, вы можете добавить регулярное выражение.
Grok также разрешит преобразования в int и float . Вам просто нужно добавить в качестве дополнительного параметра в match . Например: %{IP:client:int}
При использовании плагина grok старайтесь не дублировать отправляемое сообщение, добавив шаблон:
|
1
2
3
|
grok { match { message => "%{GREEDYDATA:message}" }} |
Это добавит новое сообщение в поле сообщения вместо замены.
JSON
Возможно, вы оказались в лучшем положении и структурировали свои журналы в формате, подобном JSON. Для этого Logstash даст вам бесплатный анализ.
|
1
2
3
4
|
json { source => "message" target => "payload"} |
Это все, что вам нужно сделать, чтобы Logstash проанализировал все сообщения JSON и установил правильный тип данных для полей.
Key-Value
Другой фильтр, который может быть полезен, это Key-Value или kv . Он используется для разделения данных на основе двух ключей. Так что, если у нас есть логлайн, который выглядит так:
|
1
|
timestamp=10/09/2019 10:10:50, level=INFO, message=Something wrong might not be right |
Мы можем использовать фильтр kv следующим образом:
|
1
2
3
4
5
6
7
8
|
filter { kv { source => "message" field_split => "," value_split => "=" target => "summary" }} |
Таким образом, мы можем проанализировать данные из сообщения, используя фильтр kv . Единственная проблема с этим фильтром состоит в том, что вы не можете установить тип данных во время шага фильтра.
Mutate
Возможно, вы захотите изменить журнал, который вы получаете, я не говорю о полном разборе журнала, но небольшие изменения. Для этого есть фильтр mutate , и есть несколько команд, которые можно использовать для изменения вашего журнала.
Некоторые примеры того, что вы можете сделать с помощью фильтра mutate:
-
convert: вы могли бы проанализировать поле, но вам нужно, чтобы это поле было больше, чем просто строка. Командаconvertпозволяет вам преобразовать вinteger,integerfloat,stringилиboolean.
|
1
2
3
4
5
6
7
8
|
filter { mutate { convert => { "quantity" => "integer" "is_paid" => "boolean" } }} |
-
remove_field: вы можете удалить некоторые конфиденциальные данные из ваших журналов, поэтому вы можете использовать эту команду для их удаления.
|
1
2
3
4
5
|
filter { mutate { remove_field => ["sensitive_data"] }} |
-
gsub: это опция для замены значений с помощью регулярных выражений, вы можете захотеть скрыть некоторые данные, которые не имеют значения, вы можете использовать эту опцию для этого.
|
1
2
3
4
5
6
7
8
|
filter { mutate { gsub => [ # field regex result "transaction_reference", "\d{4}-\d{4}-\d{4}-\d{4}", "XXXX-XXXX-XXXX-XXXX" ] }} |
Это заменит все ссылки на транзакции замаскированной версией.
Выход
Это та часть, где вы можете направить только что проанализированный журнал в выходной файл или хранилище данных. В нашем случае мы собираемся использовать Elasticsearch который является хранилищем документов NoSQL, но вы также можете отправлять в другие места, такие как CSV , HTTP или даже по email .
Вы можете проверить документацию для Logstash чтобы увидеть все выходные плагины.
|
1
2
3
4
5
6
7
8
|
output { elasticsearch { hosts => ["192.168.0.15"] user => "elastic_user" password => "elastic_password" index => "application-log" }} |
В этом примере мы отправляем наши журналы в Elasticsearch размещенный на другом компьютере.
Elasticsearch
Elasticsearch — это механизм поисковой аналитики, который выполняет работу по сбору и агрегированию хранимых данных. Он также обеспечивает поиск в реальном времени всех видов данных, будь то структурированный или неструктурированный текст или числовые данные.
Все данные в Elasticsearch хранятся в формате JSON, а затем индексируются, что позволяет сразу же искать их. Каждый сохраненный документ представляет собой набор пар ключ-значение, которые содержат данные и хранятся в оптимизированной структуре данных, которая помогает искать их позже.
Основные конструкции
Вершины
Узлы являются одной из самых основных конструкций, которые хранят и индексируют данные. Есть несколько типов узлов.
- Главный узел: контролирует кластер
- Узел данных: содержит данные и выполняет операции CRUD, агрегации и поиск.
- Ingest node: преобразует и обогащает данные перед индексацией.
Показатель
Индекс — это набор документов с похожими характеристиками, они похожи на таблицы в реляционной базе данных.
Индексы более гибкие, чем реляционные базы данных, так как они легки, вы можете создать несколько индексов без особых затруднений. Например, при ведении журнала вы можете создать индекс для каждого дня и иметь тип журнала, который у вас есть.
Каждый день будет создаваться новый индекс, вы не сделаете этого для реляционной БД.
Использование Elasticsearch
Есть две основные вещи, на которые мы должны обратить внимание при работе с Elasticsearch . Это templates и policies .
Шаблоны
Шаблоны можно считать схемой вашего индекса, Elasticsearch может установить схему по умолчанию, но вам нужно больше контролировать ее, если вы хотите делать агрегации и вычисления в данных, которые у вас есть.
Какие типы поддерживает Elasticsearch ? Основные поддерживаемые типы данных:
- строка
- Числовой (long, int, short, double, float)
- Дата
Создание шаблонов
Как мне настроить мой шаблон? Что ж, у Elasticsearch есть REST-подобный API, с которым вы можете легко взаимодействовать.
Мы добавляем журналы для заявки для компании Fintech, и мы хотим отслеживать переводы, которые мы делаем. Полезная нагрузка, которую мы имеем для переводов:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
{ "paymentDate": "2019-09-14 11:25:32.321", "amount": 100.00, "message": "Payment message", "origin": { "sortCode": "11-11-11", "account": "838383" }, "destination": { "sortCode": "11-11-11", "account": "1313123" }} |
Мы начинаем создавать наш шаблон с поля payment_date и мы можем установить тип в качестве даты и указать формат для поля:
|
1
2
3
4
|
"payment_date": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss.SSS"} |
Затем у нас есть amount , мы добавляем это поле с типом scaled_float и scaling_factor равным 100, чтобы Elasticsearch мог обрабатывать две цифры в десятичной части, делая жизнь немного проще для наших поисков позже:
|
1
2
3
4
|
"amount": { "type": "scaled_float", "scaling_factor": "100"} |
Затем у нас есть поле message которое является просто строкой, поэтому мы будем использовать text тип, который создает поле, индексированное для полнотекстового поиска:
|
1
2
3
|
"message": { "type": "text"} |
Поля origin и destination практически одинаковы, и они всегда имеют одинаковый формат, поэтому мы можем использовать тип keyword . Этот тип подходит для небольших объемов полуструктурированных данных, таких как почтовый индекс, адреса, электронные письма, коды сортировки и номера счетов:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
"origin": { "properties": { "body": { "properties": { "sort_code": { "type": "keyword" }, "account": { "type": "keyword" } } } }} |
Теперь у нас есть полное отображение индекса, которое мы можем вставить в Elasticsearch . Мы просто делаем запрос PUT .
|
1
|
|
|
001
002
003
004
005
006
007
008
009
010
011
012
013
014
015
016
017
018
019
020
021
022
023
024
025
026
027
028
029
030
031
032
033
034
035
036
037
038
039
040
041
042
043
044
045
046
047
048
049
050
051
052
053
054
055
056
057
058
059
060
061
062
063
064
065
066
067
068
069
070
071
072
073
074
075
076
077
078
079
080
081
082
083
084
085
086
087
088
089
090
091
092
093
094
095
096
097
098
099
100
101
102
103
104
105
106
107
108
109
110
111
112
|
{ "index_patterns": [ "transfers-*" ], "mappings": { "_meta": { "beat": "transfers", "version": "7.0.1" }, "date_detection": false, "dynamic_templates": [ { "labels": { "mapping": { "type": "keyword" }, "match_mapping_type": "string", "path_match": "labels.*" } }, { "container.labels": { "mapping": { "type": "keyword" }, "match_mapping_type": "string", "path_match": "container.labels.*" } }, { "fields": { "mapping": { "type": "keyword" }, "match_mapping_type": "string", "path_match": "fields.*" } }, { "docker.container.labels": { "mapping": { "type": "keyword" }, "match_mapping_type": "string", "path_match": "docker.container.labels.*" } }, { "kibana.log.meta": { "mapping": { "type": "keyword" }, "match_mapping_type": "string", "path_match": "kibana.log.meta.*" } }, { "strings_as_keyword": { "mapping": { "ignore_above": 1024, "type": "keyword" }, "match_mapping_type": "string" } } ], "properties": { "@timestamp": { "type": "date" }, "payment_date": { "type": "date", "format": "yyyy-MM-ddTHH:mm:ss.SSSSSS" }, "amount": { "type": "scaled_float", "scaling_factor": "100" }, "message": { "type": "text" }, "origin": { "properties": { "body": { "properties": { "sort_code": { "type": "keyword" }, "account": { "type": "keyword" } } } } }, "destination": { "properties": { "body": { "properties": { "sort_code": { "type": "keyword" }, "account": { "type": "keyword" } } } } } } }} |
полисы
Эта функция доступна только в премиальных версиях Elasticsearch .
Индексы будут постоянно засыпаны данными, и, как и файлы журналов, нам нужна политика ролловера, чтобы наши диски не были заполнены. В премиальной версии Elasticsearch у нас есть инструменты Elasticsearch политики, которые помогут нам в этом.
Первое, что нужно знать, это каковы состояния индекса.
-
hot: индекс, в который мы пишем. -
warm: Индекс, который мы часто запрашиваем, но не пишем. -
cold: индекс, в который мы больше не пишем, и мы также не очень часто запрашиваем данные. -
delete: индекс, который больше не нужен и может быть удален.
Индекс начинается в hot состоянии, и мы можем сказать Elasticsearch когда не хотим больше писать в индексе. Мы говорим ему начать использовать другой индекс, используя max_age и max_size . В приведенном ниже примере мы создаем новый индекс каждый день или когда он достигает 5GB (число было выбрано произвольно).
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
{ "policy": { "phases": { "hot": { "actions": { "rollover": { "max_age": "1d", "max_size": "5GB" } } } } }} |
Мы не хотим поддерживать все индексы hot , поэтому мы можем начать изменять состояние наших старых индексов и делать их warm . Политика определения того, что происходит в warm состояние, начинается с параметра min_age , который звучит совершенно очевидно, что он делает. В нашем случае мы устанавливаем min_age на 7d , поэтому все hot индексы, которые старше семи дней, будут преобразованы в warm индекс.
Для « warm индексов у нас есть несколько опций, которые ранее не были доступны в « hot , раздел actions позволяет нам вносить некоторые изменения при изменении состояния индекса.
Первое, что мы видим, это forcemerge этой опции, когда установлено значение 1 , говорит Elasticsearch объединить все индексы, которые идут от hot к hot . Это полезно, потому что в Elastisearch когда вы удаляете документ, этот документ на самом деле не удаляется, а удаляется только отмеченный. Во время слияния документы, помеченные как удаленные, будут должным образом удалены, как если бы вы отправляли файлы в Trash bin а затем удаляли их из вашей системы.
Затем мы имеем shrink которое используется для уменьшения количества сегментов индекса. Поскольку мы больше не пишем в этом индексе, нам не нужны все шарды, которые мы выделили ранее.
И наконец мы должны allocate . Здесь мы можем установить number_of_replicas , в случае, если нам нужны данные, чтобы быть высокодоступными, а также это более безопасно, чем иметь только один осколок.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
"warm": { "min_age": "7d", "actions": { "forcemerge": { "max_num_segments": 1 }, "shrink": { "number_of_shards": 1 }, "allocate": { "number_of_replicas": 2, "require": { "data": "warm" } } }} |
Для данных, которые даже старше, чем мы установили для warm состояния, и которые мы просто храним по соображениям безопасности, мы можем перевести их индексы в cold . Мы устанавливаем для каждого индекса старше 6 месяцев cold и замораживаем их. Преимущество замораживания на этом этапе заключается в том, что Elastisearch не использует дополнительную память для замороженных индексов.
|
1
2
3
4
5
6
|
"cold": { "min_age": "180d", "actions": { "freeze": {} }} |
Наконец, есть удаление индекса, который довольно прост.
|
1
2
3
4
5
6
|
"delete": { "min_age": "365d", "actions": { "delete": {} }} |
Окончательная политика, которая у нас есть, будет выглядеть так:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
{ "policy": { "phases": { "hot": { "actions": { "rollover": { "max_age": "1d", "max_size": "5GB" } } }, "warm": { "min_age": "7d", "actions": { "forcemerge": { "max_num_segments": 1 }, "shrink": { "number_of_shards": 1 }, "allocate": { "number_of_replicas": 2, "require": { "data": "warm" } } } }, "cold": { "min_age": "100d", "actions": { "freeze": {} } }, "delete": { "min_age": "365d", "actions": { "delete": {} } } } }} |
Удары
FileBeat
Filebeat — это легкий инструмент, который читает журналы и отправляет их в ElasticSearch или Logstash . Единственная цель этого инструмента — читать файлы журнала, он не может выполнять с ним никаких сложных операций. Если вы хотите выполнять сложные операции, вы можете отправить журнал в Logstash и проанализировать необходимую информацию.
Когда у вас есть несколько серверов, и вы не хотите устанавливать Logstash на всех компьютерах, потому что это тяжелое приложение, вы можете использовать Filebeat как написано на Go, изначально скомпилировано и очень легко.
Настроить Filebeat так как он мало что делает. У вас есть filebeat.yml который содержит конфигурацию:
|
01
02
03
04
05
06
07
08
09
10
|
filebeat.config.inputs: filebeat: inputs: - type: log paths: - "/var/log/applog/*.log" output: logstash: hosts: ["logstash:5043"] |
Мы можем видеть часть inputs которая читает журналы из папки и отправляет их на output в Logstash который размещен в другом месте. В этом файле конфигурации мы читаем журналы из папки applog . Вы также можете использовать шаблоны глобуса в путях для получения нескольких файлов или для записи различий, таких как прописные или строчные буквы.
Многострочная строка
При работе с Filebeat вам может понадобиться прочитать многострочные строки. Так же, как Logstash вы можете использовать multiline параметры в конфигурации для чтения файла, все те же поля для Logstash применяются для Filebeat .
|
1
2
3
4
5
6
7
8
|
filebeat.config.inputs: - type: log paths: - "/var/log/applog/application.log" multiline: pattern: "\\[\\d{2}\\/\\d{2}\\/\\d{4} \\d{2}:\\d{2}:\\d{2}]\\[\\w{2}\\]" negate: True match: after |
Как работает Filebeat | Filebeat Reference [7.1] | Эластичный
поля
Вы также можете добавить дополнительную информацию в журналы, которые вы читаете, чтобы вы могли идентифицировать файлы, из которых были получены данные для использования в более поздний срок.
|
01
02
03
04
05
06
07
08
09
10
|
filebeat.config.inputs: - type: log paths: - "/var/log/applog/application.log" fields: file_name: "application_log" multiline: pattern: "\\[\\d{2}\\/\\d{2}\\/\\d{4} \\d{2}:\\d{2}:\\d{2}]\\[\\w{2}\\]" negate: True match: after |
автоперезагрузки
Вы также можете отделить входной список от файла конфигурации и, сделав это, вы можете обновить файл входными данными, не перезапуская Filebeat . Таким образом, вместо непосредственного добавления inputs в основной файл конфигурации, мы предоставляем в файл конфигурацию входных данных.
|
1
2
3
4
5
|
filebeat.config.inputs: enabled: true path: inputs.yml reload.enabled: true reload.period: 10s |
inputs.yml который Filebeat собирается загрузить:
|
1
2
3
4
5
|
- type: log paths: - "/var/log/haproxy.log" fields: file_name: "Haproxy" |
Kibana
До этого момента мы собираем, структурируем и храним все эти журналы. Теперь нам нужно получить некоторую ценность от них. Просто хранить их не лучший вариант, нам нужно визуализировать их, чтобы иметь обратную связь.
Для визуализации всех данных, которые были сохранены в Elasticsearch вы можете использовать Kibana . Это приложение, которое позволяет запрашивать данные из Elasticsearch и создавать на их основе визуализации.
В доме Kibana мы решили подключиться к индексу в Elastisearch используя шаблон для указания имени индекса, такого как logs-* чтобы мы могли искать все индексы, начиная с logs- поскольку мы могли бы группировать наши журналы по дням, а не по всем в одном индексе.
открытие
Область Discovery позволяет визуализировать и искать данные, хранящиеся в Elastichsearch .

1 — Фильтры
У вас есть панель, где вы можете написать свои запросы, используя KQL, который является языком пользовательских запросов, который довольно прост в использовании. Kibana также поможет вам автоматически выполнить запрос.
Поэтому, если мы хотим выполнить поиск, вы можете просто набрать:
|
1
|
tags: "retrieve-data" and stats1 >= 10000 |
Или вы можете использовать раздел filters где у вас есть более ориентированный на пользовательский интерфейс способ поиска.
Вы также можете сохранить результаты поиска на потом, чтобы вам не приходилось переписывать их каждый раз. Сохраненные результаты поиска можно использовать в других частях пользовательского интерфейса Kibana.
2 — Фильтры даты
Если вы хотите отфильтровать результаты по определенному периоду, фильтр позволяет использовать две опции:
- Абсолют: вы можете установить точную дату и время, которое вы хотите.
- Относительно: Вы устанавливаете желаемую дату и метку времени, как
10 minutes ago. С помощью этой опции вы также можете настроить получение последних данных отElasticsearch.
3 — Записи
Вы можете развернуть и просмотреть записи способом ключ-значение, а также отобразить тип поля, которое может быть три:
-
t— текстовое поле -
#— Числовое поле - Символ часов — Дата и время
Вы также можете отфильтровать поля, которые вы хотите видеть, выбрав их в меню « Available Fields слева.
Визуализируйте
Нам нужен способ визуализировать все эти данные, которые хорошо хранятся, а Visualize позволяет нам создавать различные виды графиков.
Y-Axis
В этом примере мы создаем bar graph . В левом меню вы можете установить параметры для создания графика.

-
Aggregation: вид операции, которую вы хотите выполнить, это может бытьcountопераций,sumиaverage. Есть также более сложные операции, такие какStandard Deviationи операции, использующие другие значения. -
Field: Поле, которое вы хотите использовать для расчета и отображаемое значение. Для простых агрегаций вы можете сразу выбрать поле из выпадающего списка, а для более сложных запросов вы можете использоватьQueryDSLиJSONчтобы найти значения. -
Custom Label: Вы, вероятно, не хотите отображать свои данные без смысла, поэтому здесь вы можете добавить для них хорошую метку.
Ковши
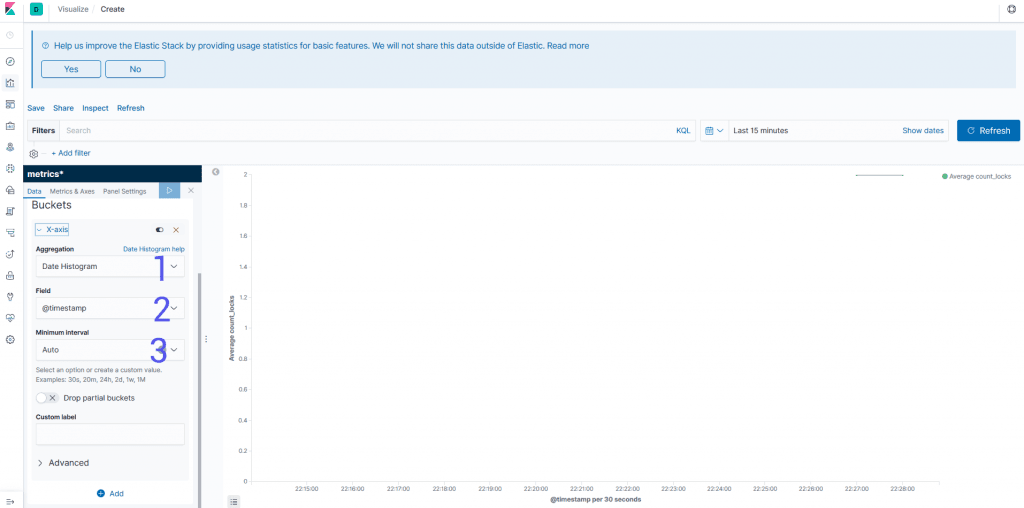
-
Aggregation: как вы собираетесь группировать ваши данные. Возможно, вам понадобится время с использованиемDate Histogramили чего-то еще, чтобы сгруппировать конечные точки, которые у вас есть, используя определенное поле. -
Field: поле, которое вы собираетесь использовать для разделения данных. Если вам нужно более сложное агрегирование, вы сможете использоватьQueryDSLв качестве входных данных. -
Interval: Если вы хотите сгруппировать по дате, вы можете указать период времени, который вы хотите разделить данные. Для других агрегатов, таких как диапазоны, вы получаете разные поля интервалов.
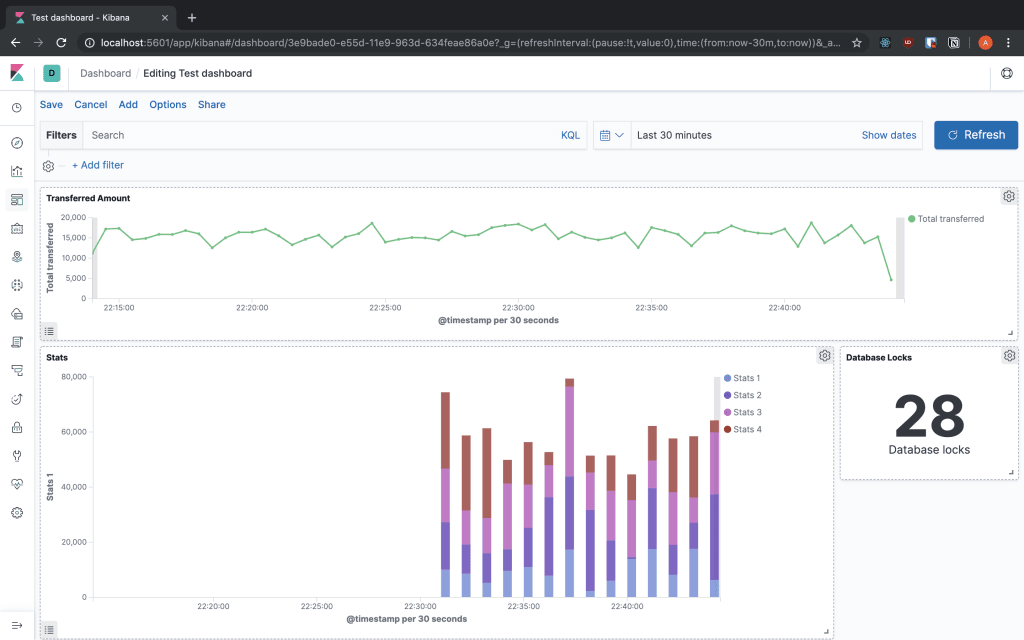
Сводки
Теперь мы можем собрать визуализацию, встроенную в Dashboards , чтобы объединить все данные, которые мы хотим видеть, в одном месте. Вы можете добавить созданные вами визуализации и изменить их размер, чтобы они соответствовали экрану так, как вы хотите. Также вы можете изменить их поиск и даже отображать их в полноэкранном режиме, чтобы они отображались очень хорошо.
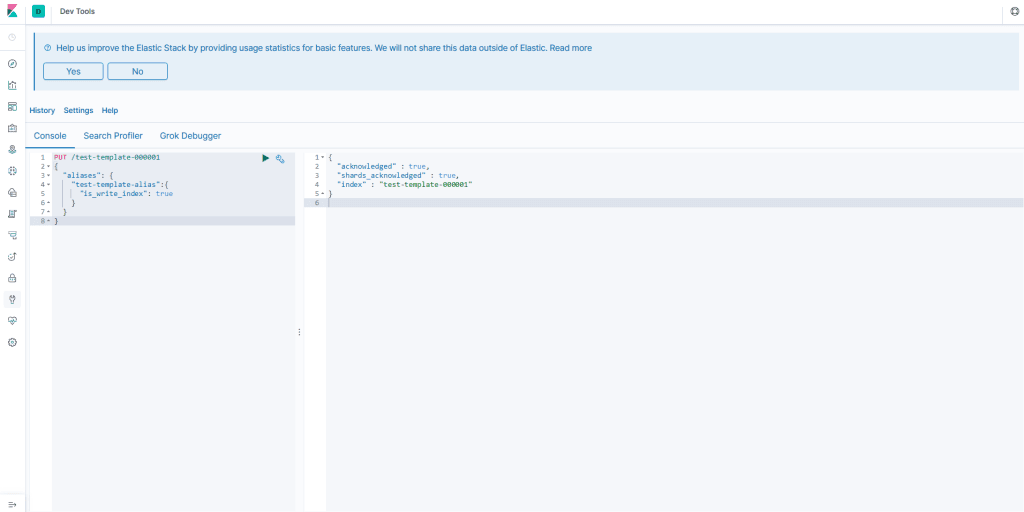
Dev Tools
Kibana также предоставляет вам разделы Dev Tools , в которых есть некоторые инструменты для вашей работы.
Приставка
Мы увидели, что Elasticsearch имеет REST-подобный API, так что консоль обеспечивает простой способ взаимодействия с API. Обеспечение автозаполнения и непосредственное подключение к Elasticsearch так что вам не нужно создавать весь запрос вручную. Вы можете сделать запрос, просто имея метод и путь, вы также можете написать JSON с проверкой и завершением.
|
1
|
GET _template/transfers_template |
|
1
2
3
4
5
6
7
8
|
PUT /test-template-000001{ "aliases": { "test-template-alias": { "is_write_index": true } }} |
Grok Debugger
Когда мы говорили о Logstash мы увидели плагин Grok и его мощь, но Grok работает с использованием регулярных выражений, и все знают, что регулярные выражения являются полным безумием и их легко сломать, поэтому отладчик помогает нам создавать шаблоны для анализа нашего строки журнала.
У нас есть сообщение, получающее статистику с нашего сервера, есть четыре столбца, но мы должны разбить их на соответствующие поля, поэтому мы используем для этого анализатор Grok .
|
1
|
16765 | 10475 | 26017 | 27583 |
|
1
|
%{NUMBER:stats1} \| %{NUMBER:stats2} \| %{NUMBER:stats3} \| %{NUMBER:stats4} |

Это все на сегодня
В этом посте мы увидели компоненты Elastic Stack, как начать их использовать и важность организации ваших логов. Также вы всегда можете обратиться к документации по Elastic Stack здесь, чтобы увидеть, какие другие функциональные возможности поддерживаются, которые не упомянуты в моем посте.
| Опубликовано на Java Code Geeks с разрешения Андре Гуэлфи Торреса, партнера нашей программы JCG. Смотрите оригинальную статью здесь: Elastic Stack Введение
Мнения, высказанные участниками Java Code Geeks, являются их собственными. |